
| Join Telegram |  |
| Join Whatsapp Groups |  |
Big Data Interview Questions and Answers: Big data involves vast amounts of data, often in terabytes or petabytes. Around 90% of today’s data was generated in the last two years. The term “big data” was coined in the mid-2000s. It helps companies refine marketing campaigns and gain valuable insights. This article features the Top 100 Big Data Interview Questions and Answers, having a list of the Latest Big Data Interview Questions and Big Data Interview Questions for Freshers.
★★ Latest Technical Interview Questions ★★
Big Data Technical Interview Questions
Prepare for Big Data interviews with our Top 100 Big Data Interview Questions and Answers 2023. Whether you’re a fresh graduate or an experienced developer, demonstrate your understanding of concepts, syntax, and best practices. Impress your interviewer and succeed in the realm of Big Data Technical Interview Questions.
Top 100 Big Data Interview Questions and Answers
1. What is Big Data and what are its defining characteristics?
Big Data refers to large and complex datasets that cannot be easily managed using traditional data processing methods. Its defining characteristics are volume, variety, and velocity.
2. Explain the three V’s of Big Data.
The three V’s of Big Data are Volume (the vast amount of data generated), Variety (the diverse types and formats of data), and Velocity (the speed at which data is generated and processed).
3. What are the 5 V’s in Big Data?
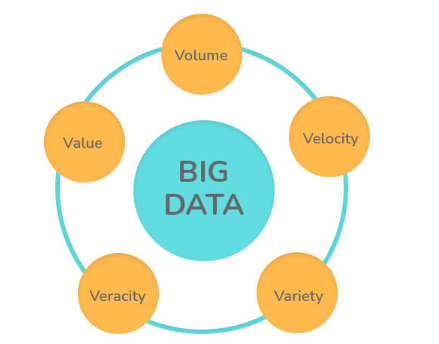
- Volume: Large volumes of data, ranging from terabytes to petabytes, need to be examined and processed.
- Velocity: Real-time production of data at a high pace, such as social media posts generated per second or hour.
- Variety: Big Data includes structured, unstructured, and semi-structured data from diverse sources, requiring specific analyzing and processing techniques.
- Veracity: Data veracity refers to the reliability and quality of the analyzed data.
- Value: Extracting valuable information from raw data by converting it into meaningful insights.
4. Differentiate between structured and unstructured data.
Structured data is organized and formatted in a specific way, typically stored in databases and spreadsheets. Unstructured data, on the other hand, lacks a predefined structure and can include text documents, images, videos, social media posts, etc.
5. Difference between structured and unstructured data
| Structured Data | Unstructured Data |
|---|---|
| Data is organized in a fixed format with a predefined schema. | Data does not have a predefined structure or schema. |
| Examples include relational databases, spreadsheets, and CSV files. | Examples include text documents, social media posts, and multimedia content. |
| Easy to analyze and query using traditional database techniques. | Difficult to analyze due to the lack of a predefined structure. |
| Well-suited for traditional data processing and analytics. | Requires advanced techniques like natural language processing for analysis. |
6. How to deploy a Big Data Model? Mention the key steps involved.
Deploying a model into a Big Data Platform involves mainly three key steps they are,
- Data ingestion
- Data Storage
- Data Processing
- Data Ingestion: Collect data from various sources like social media platforms, business applications, and log files.
- Data Storage: Storing a large volume of data in databases, with Hadoop Distributed File System (HDFS) being a key component.
- Data Processing: Analyzing and visualizing the data using specific algorithms and technologies like Hadoop, Apache Spark, and Pig.
- Deployment: Successfully implementing a Big Data model after completing the essential steps.
7. What is the Hadoop framework and how does it handle Big Data processing?
Hadoop is an open-source framework that enables distributed processing of large datasets across clusters of computers. It uses the MapReduce programming model to divide tasks and distribute them among multiple nodes in the cluster, allowing parallel processing of Big Data.
8. Explain the MapReduce algorithm and its role in Big Data processing.
MapReduce is a programming model and algorithm used for processing and analyzing large datasets in parallel across distributed computing environments. It involves two stages: the Map stage, where data is divided into smaller chunks and processed independently, and the Reduce stage, where the results from the Map stage are combined to produce the final output.
9. What is the role of Apache Sqoop in Big Data?
- Apache Sqoop is a tool used for transferring data between Hadoop and relational databases.
- It simplifies the import and export of structured data from databases to Hadoop and vice versa.
- Sqoop supports parallel data transfers and can handle incremental data imports.
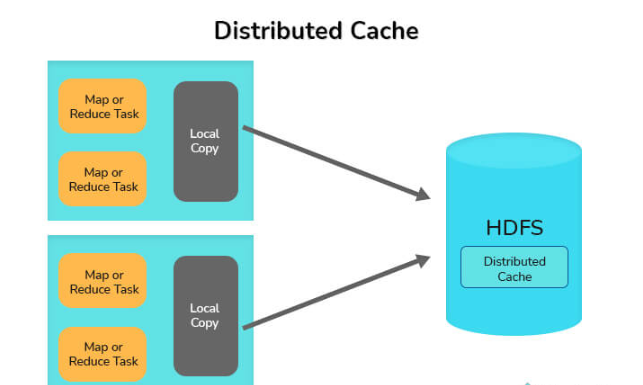
10. Explain the distributed Cache in the MapReduce framework.
The Distributed Cache is a crucial feature offered by the MapReduce Framework in Hadoop, enabling the sharing of files across all nodes in a Hadoop cluster. This feature is particularly useful when there is a need to distribute files such as jar files or properties files to every node in the cluster. With Hadoop’s MapReduce framework, it becomes possible to cache and distribute small to moderate-sized read-only files, including text files, zip files, and jar files, among others. These files are replicated to each Datanode (worker-node) where MapReduce jobs are executed, ensuring that every Datanode has a local copy of the distributed file thanks to the Distributed Cache mechanism.
11. Explain the concept of data skewness and its impact on Big Data processing.
- Data skewness refers to an uneven distribution of data across partitions or nodes in a distributed system.
- It can lead to performance issues, as some partitions or nodes may have a significantly higher workload than others.
- Data skewness can be mitigated by using techniques like data partitioning, hash-based shuffling, or data reorganization.
12. What are the advantages of using Apache Kafka in Big Data architectures?
- Apache Kafka provides high-throughput, fault-tolerant, and real-time data streaming capabilities.
- It allows the decoupling of data producers and consumers, enabling scalable and distributed data processing.
- Kafka provides durable storage and efficient data replication, ensuring reliable data streaming and processing.
13. Mention features of Apache sqoop.
- Robust: Sqoop is a robust and user-friendly tool, with strong community support and contributions.
- Full Load: Sqoop allows for easy loading of tables in one command, and multiple tables can be loaded simultaneously.
- Incremental Load: Sqoop supports incremental loading, allowing for partial loading when a table is updated.
- Parallel Import/Export: Data import and export operations are performed using the YARN framework, providing fault tolerance.
- Import Results of SQL Query: Sqoop enables the import of SQL query output directly into the Hadoop Distributed File System (HDFS).

14. Explain the concept of data sampling in Big Data analytics.
- Data sampling involves selecting a subset of data from a larger dataset for analysis.
- It helps in reducing computational requirements and processing time for large datasets.
- Sampling techniques include random sampling, stratified sampling, and cluster sampling.
15. What is the role of Apache Flink in Big Data processing?
- Apache Flink is a stream-processing and batch-processing framework for Big Data.
- It supports event-driven applications, real-time analytics, and high-throughput data processing.
- Flink provides fault tolerance, exactly-once processing semantics, and low-latency data processing.
16. Difference between batch processing and real-time processing
| Batch Processing | Real-time Processing |
|---|---|
| Data is processed in large volumes at specific intervals or time windows. | Data is processed as it arrives, providing immediate results. |
| Typically used for offline or non-time-critical applications. | Used for time-sensitive applications that require immediate responses. |
| Suitable for analyzing historical data and generating reports. | Supports real-time decision-making and event-driven applications. |
| Examples include Hadoop MapReduce and batch ETL (Extract, Transform, Load) processes. | Examples include real-time stream processing frameworks like Apache Kafka and Apache Flink. |
17. Explain the concept of data compression in Big Data storage.
- Data compression is the process of reducing the size of data to save storage space and improve data transfer efficiency.
- Compression algorithms are used to remove redundancy and represent data in a more compact form.
- Common compression techniques include gzip, Snappy, and LZO.
18. What are the key considerations for data backup and recovery in Big Data systems?
- Data backup and recovery strategies should include regular backups, off-site storage, and redundancy.
- Incremental backups and snapshot-based techniques can help reduce backup time and storage requirements.
- Testing backup and recovery processes is crucial to ensure data can be restored effectively in case of failures.
19. Explain the concept of data latency in Big Data processing.
- Data latency refers to the delay between data generation and its availability for processing or analysis.
- Low latency is desirable for real-time analytics and immediate data-driven decision-making.
- High latency can occur due to factors like network congestion, processing bottlenecks, or inefficient data transfer mechanisms.
20. What is the role of Apache Zeppelin in Big Data analytics?
- Apache Zeppelin is a web-based notebook for data exploration, visualization, and collaboration.
- It provides an interactive environment for writing and executing code in languages like Scala, Python, SQL, and R.
- Zeppelin integrates with various Big Data frameworks and supports real-time data visualization.
21. Explain the concept of data lineage in Big Data.
- Data lineage refers to tracking and documenting the origin, transformation, and movement of data throughout its lifecycle.
- It helps in understanding data provenance, ensuring data quality, and complying with regulatory requirements.
- Data lineage tools provide visibility into data flow, dependencies, and transformations in Big Data systems.
22. Difference between data privacy and data security in the context of Big Data
| Data Privacy | Data Security |
|---|---|
| Focuses on protecting individuals’ personal information and ensuring its proper handling. | Concerned with safeguarding data from unauthorized access, breaches, and malicious activities. |
| Involves implementing measures to control and regulate the collection, use, and disclosure of personal data. | Includes techniques and technologies to prevent, detect, and respond to security threats and breaches. |
| Addresses legal and regulatory requirements related to privacy, such as data protection laws. | Covers measures like encryption, access controls, authentication, and network security. |
| Emphasizes individuals’ rights to consent, access, rectify, and delete their personal data. | Aims to maintain the confidentiality, integrity, and availability of data throughout its lifecycle. |
23. What are the key components of the Hadoop ecosystem?
The key components of the Hadoop ecosystem include Hadoop Distributed File System (HDFS) for storing data, YARN for resource management, MapReduce for processing data, and additional tools like Hive, Pig, and Spark for higher-level data processing and analysis.
24. Describe the role of HDFS (Hadoop Distributed File System) in Big Data storage.
HDFS is a distributed file system designed to store and manage large amounts of data across multiple machines in a Hadoop cluster. It provides fault tolerance, high throughput, and scalability by dividing data into blocks and replicating them across different nodes in the cluster.
25. Difference between Hadoop and Spark in the data processing
| Hadoop | Spark |
|---|---|
| Primarily designed for distributed storage and batch processing of large datasets. | Provides a unified and flexible processing framework for batch, interactive, and streaming workloads. |
| Uses the Hadoop Distributed File System (HDFS) for data storage and MapReduce for processing. | Offers in-memory processing, which makes it faster compared to Hadoop for iterative and interactive tasks. |
| Suitable for processing structured, semi-structured, and unstructured data. | Supports various data formats and provides higher-level APIs for data manipulation and analytics. |
| Well-suited for offline analytics and large-scale data processing. | Efficient for real-time streaming, machine learning, and graph processing use cases. |
26. What is the purpose of YARN in the Hadoop ecosystem?
YARN (Yet Another Resource Negotiator) is a component of the Hadoop ecosystem responsible for resource management and job scheduling in a distributed computing environment. It allows different applications to run concurrently on a Hadoop cluster, effectively managing resources and allocating them to specific tasks.
27. Explain the concept of data partitioning in Hadoop.
Data partitioning in Hadoop involves dividing large datasets into smaller, manageable partitions that can be processed independently across different nodes in the cluster. This allows for parallel processing and efficient utilization of resources in a distributed computing environment.
28. Difference between data warehousing and data lakes in Big Data architecture
| Data Warehousing | Data Lakes |
|---|---|
| Organizes structured data from various sources into a centralized repository. | Stores structured, semi-structured, and unstructured data in its raw form. |
| Uses a predefined schema to ensure data consistency and quality. | Allows storing data without a predefined schema, providing flexibility for analysis. |
| Supports complex querying, reporting, and business intelligence (BI) applications. | Enables exploration, ad-hoc analysis, and data discovery for data scientists and analysts. |
| Data is transformed and cleansed before being loaded into the warehouse. | Data is stored in its native format and transformed during analysis as per requirements. |
29. What is the difference between NameNode and DataNode in HDFS?
In HDFS, the NameNode is responsible for storing metadata about the files and directories in the distributed file system, while the DataNodes store the actual data blocks. The NameNode maintains the file system namespace and coordinates access to the data stored in DataNodes.
30. How can you write a Pig Latin script to load data from a Hadoop cluster and store it in a relation?
To load data from Hadoop and store it in a relation, you can use the following Pig Latin script:
data = LOAD 'hdfs://<Hadoop_cluster_address>/input_data' USING PigStorage(',');
STORE data INTO '<Hadoop_cluster_address>/output_data' USING PigStorage(',');
31. What is the role of Apache Spark in Big Data processing?
- Apache Spark is a fast and general-purpose cluster computing framework for Big Data processing.
- It supports in-memory data processing, iterative algorithms, and interactive queries.
- Spark provides high-level APIs in various programming languages and supports batch processing, streaming, and machine learning.
32. Difference between data mining and machine learning in extracting insights from Big Data
| Data Mining | Machine Learning |
|---|---|
| Focuses on discovering patterns, relationships, and insights from large datasets. | Utilizes algorithms to automatically learn patterns and make predictions from data. |
| Involves the use of statistical and analytical techniques to identify valuable information. | Uses algorithms to train models on data and make predictions or decisions. |
| Often used for exploratory analysis and uncovering hidden patterns in historical data. | Enables the development of predictive models and automated decision-making systems. |
| Helps in understanding data characteristics, identifying outliers, and finding associations. | Enables prediction, classification, clustering, and recommendation tasks. |
| Frequently employed for descriptive analytics and knowledge discovery from data. | Supports both descriptive and predictive analytics, as well as reinforcement learning. |
33. Explain the concept of data partitioning in distributed databases.
- Data partitioning involves dividing data into smaller subsets called partitions and distributing them across multiple nodes or servers.
- Partitioning enables parallel processing and improves scalability, as each node can handle a subset of the data independently.
- Different partitioning strategies include range partitioning, hash partitioning, and round-robin partitioning.
34. What are the key challenges of data quality in Big Data environments?
- Data quality challenges in Big Data include data inconsistency, missing values, data duplication, and data validation issues.
- Managing data quality requires techniques such as data profiling, data cleansing, and data integration processes.
- Handling data quality in Big Data environments is complex due to the volume, variety, and velocity of data.
35. Explain the concept of data anonymization in Big Data analytics.
- Data anonymization is the process of removing or obfuscating personally identifiable information (PII) from datasets.
- It is done to protect privacy and comply with data protection regulations.
- Anonymization techniques include generalization, suppression, and perturbation to ensure that individuals cannot be re-identified from the data.
36. What is the role of YARN in Hadoop?
- YARN (Yet Another Resource Negotiator) is the resource management layer in the Hadoop ecosystem.
- It manages resources and schedules tasks across the cluster, ensuring efficient utilization of resources.
- YARN enables multi-tenancy, supports various application frameworks, and provides scalability and fault tolerance.
37. Difference between NoSQL and SQL databases in Big Data environments
| NoSQL Databases | SQL Databases |
|---|---|
| Designed to handle large-scale, unstructured, and rapidly changing data. | Primarily used for structured data with fixed schemas and strong data consistency. |
| Offer flexible schemas that allow for dynamic data structures and schema evolution. | Require predefined schemas and rigid data structures. |
| Provide horizontal scalability and distributed data storage across multiple servers. | Typically scale vertically by adding more resources to a single server. |
| Optimize for high-performance read/write operations and horizontal scaling. | Optimize for transactional integrity, complex queries, and adherence to ACID properties. |
| Well-suited for use cases like real-time analytics, content management, and IoT applications. | Preferred for applications with well-defined data structures, transactional processing, and reporting. |
38. Explain the concept of data preprocessing in Big Data analytics.
- Data preprocessing involves transforming raw data into a suitable format for analysis.
- It includes tasks like data cleaning, data integration, data transformation, and feature extraction.
- Data preprocessing helps improve data quality, remove inconsistencies, and enhance the performance of machine learning models.
39. What is the role of Apache Hive in Big Data analytics?
- Apache Hive is a data warehouse infrastructure built on top of Hadoop for querying and analyzing large datasets.
- It provides a SQL-like query language called HiveQL for querying and processing data.
- Hive supports schema-on-read and integrates with Hadoop ecosystem tools, making it easier to work with structured and semi-structured data.
40. Explain the concept of data skew mitigation in Big Data processing.
- Data skew mitigation techniques aim to distribute workload evenly and avoid performance bottlenecks caused by data skewness.
- Techniques include data partitioning, using salting or hashing for key distribution, or using specialized algorithms to handle skewed data.
- By mitigating data skew, processing resources can be utilized more efficiently, improving overall system performance.
41. Difference between horizontal scaling and vertical scaling in Big Data systems
| Horizontal Scaling | Vertical Scaling |
|---|---|
| Involves adding more machines or nodes to distribute the workload and increase capacity. | Focuses on increasing the resources (CPU, memory, storage) of a single machine or node. |
| Allows for handling larger volumes of data and accommodating increased processing demands. | Enhances the performance and capacity of a single machine to handle more data and requests. |
| Provides scalability by leveraging parallel processing and data distribution across multiple nodes. | Offers scalability by upgrading the hardware components of a single machine. |
| Typically associated with distributed systems and architectures like Hadoop and Spark. | Commonly used in traditional database systems and applications. |
42. What are the key considerations for data storage in Big Data architectures?
- Key considerations for data storage in Big Data architectures include scalability, fault tolerance, data replication, and data locality.
- Choosing appropriate storage technologies such as Hadoop Distributed File System (HDFS), object storage, or cloud-based storage depends on specific requirements.
- Storage systems should be able to handle large volumes of data, support efficient data access, and provide data durability.
43. Difference between data sampling and data partitioning techniques in Big Data Analytics
| Data Sampling | Data Partitioning |
|---|---|
| Involves selecting a subset of data from a larger dataset for analysis or processing. | Divides a dataset into smaller, manageable partitions based on specific criteria. |
| Used to reduce the size of a dataset while preserving statistical characteristics. | Aims to distribute data across different nodes or storage systems for parallel processing. |
| Helps in speeding up analysis by working with a representative portion of the data. | Enables parallel processing and improves query performance by dividing data into smaller chunks. |
| May introduce sampling bias if the selected subset is not representative of the entire dataset. | Requires careful selection of partitioning keys to ensure balanced data distribution. |
| Suitable when working with large datasets and the analysis goal does not require the entire dataset. | Beneficial in distributed computing environments where data can be processed in parallel. |
44. Explain the concept of feature selection in machine learning with Big Data.
- Feature selection involves identifying the most relevant and informative features from a large set of available features.
- It helps reduce dimensionality, improve model performance, and reduce overfitting.
- Feature selection techniques include filter methods, wrapper methods, and embedded methods, considering factors like feature importance, correlation, and predictive power.
45. Provide an example of the syntax for writing a Hive query to calculate the average of a specific column.
To calculate the average of a column in Hive, you can use the following syntax:
SELECT AVG(column_name) FROM table_name;
46. How do you write a MapReduce program in Java to count the occurrences of words in a text file?
Here’s an example of the syntax for a MapReduce program in Java to count word occurrences:
// Map function
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// Implementation of map logic
}
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// Implementation of reduced logic
}
47. Explain the syntax for defining a schema in Apache Avro.
To define a schema in Apache Avro, you can use JSON-like syntax. For example:
{
"type": "record",
"name": "Employee",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"}
]
}
48. Difference between predictive analytics and prescriptive analytics in Big Data
| Predictive Analytics | Prescriptive Analytics |
|---|---|
| Focuses on analyzing historical data to make predictions and forecasts about future outcomes. | Goes beyond prediction and provides recommendations or actions to optimize outcomes. |
| Utilizes statistical modeling, machine learning, and data mining techniques for prediction. | Incorporates optimization algorithms and decision-making frameworks to suggest actions. |
| Helps in understanding patterns, trends, and potential future events based on historical data. | Provides actionable insights and recommendations for decision-making and optimization. |
| Used in various domains such as sales forecasting, demand prediction, and risk assessment. | Applied in scenarios where decision-making, resource allocation, or optimization is involved. |
49. Provide an example of the syntax for writing a Spark SQL query to filter data based on a specific condition.
To filter data in Spark SQL, you can use the following syntax:
SELECT * FROM table_name WHERE condition;
50. How do you write a Hadoop Streaming command to process data using a Python script?
The syntax for a Hadoop Streaming command with a Python script is as follows:
hadoop jar <path_to_streaming_jar> -input <input_path> -output <output_path> -mapper <python_script> -reducer <python_script> -file <python_script_file>
51. What is the role of Apache HBase in Big Data architectures?
- Apache HBase is a NoSQL database that provides real-time read/writes access to Big Data stored in Hadoop Distributed File System (HDFS).
- It is designed for random, low-latency access to large datasets and provides scalability and fault tolerance.
- HBase is commonly used for applications that require random access and high-speed data processing.
52. Explain the concept of data replication in Big Data systems.
- Data replication involves creating multiple copies of data and distributing them across different nodes or servers.
- Replication improves data availability, fault tolerance, and data locality for efficient data processing.
- Data replication strategies include simple replication, master-slave replication, and multi-master replication.
53. What are the key considerations for data scalability in Big Data architectures?
- Key considerations for data scalability include horizontal scalability, partitioning strategies, and data distribution techniques.
- Choosing scalable storage systems like Hadoop Distributed File System (HDFS) or cloud-based storage is important.
- Scalable processing frameworks like Apache Spark or Apache Flink are also used to handle growing data volumes.
54. Explain the concept of stream processing in Big Data.
- Stream processing involves analyzing and processing continuous streams of data in real time.
- It enables near-instantaneous processing of data as it arrives, facilitating real-time analytics and decision-making.
- Stream processing frameworks like Apache Kafka, Apache Flink, or Apache Storm are commonly used for stream processing tasks.
55. What is the role of Apache Cassandra in Big Data architectures?
- Apache Cassandra is a highly scalable and distributed NoSQL database designed to handle large amounts of data across multiple nodes.
- It provides high availability, fault tolerance, and linear scalability, making it suitable for Big Data applications.
- Cassandra is widely used for real-time analytics, time series data, and high-speed data ingestion.
56. Explain the concept of data serialization in Big Data processing.
- Data serialization involves converting complex data structures or objects into a binary or textual format for storage or transmission.
- Serialization is necessary when working with distributed systems, as it allows data to be easily transmitted between nodes.
- Common serialization formats in Big Data include Avro, Parquet, JSON, and Protocol Buffers.
57. What are the key challenges of data governance in Big Data environments?
- Data governance challenges in Big Data include data privacy, data quality management, regulatory compliance, and data access control.
- Managing and ensuring data consistency, lineage, and security become more complex with the volume and variety of data.
- Establishing robust data governance frameworks and policies is essential for effective and responsible data management.
58. Explain the concept of data replication in distributed databases.
- Data replication in distributed databases involves creating multiple copies of data and distributing them across different nodes or servers.
- Replication provides data redundancy, improves data availability, and enhances fault tolerance.
- Data replication strategies include master-slave replication, multi-master replication, and quorum-based replication.
59. What is the role of Apache Pig in Big Data processing?
- Apache Pig is a high-level scripting language and platform for analyzing large datasets in Hadoop.
- It provides a SQL-like language called Pig Latin for expressing data transformations and processing logic.
- Pig enables data extraction, transformation, and loading (ETL) tasks, and is particularly useful for data preparation in Big Data workflows.
60. Explain the concept of data shuffling in Big Data processing.
- Data shuffling refers to the process of redistributing data across nodes or partitions during data processing.
- It is necessary for tasks like data aggregation, joining, or grouping, where data needs to be reorganized to perform the operations.
- Shuffling data incurs network overhead and should be minimized to improve overall performance.
61. Explain the syntax for creating a new table in Apache HBase.
To create a table in HBase, you can use the following syntax:
create '<table_name>', '<column_family_name>'
62. How can you write a Scala code snippet to read data from a CSV file using Apache Spark?
Here’s an example of Scala code to read data from a CSV file using Spark:
val df = spark.read.format("csv").option("header", "true").load("<path_to_csv_file>")
63. Explain the syntax for running a Hive script from the command line.
To run a Hive script from the command line, you can use the following syntax:
hive -f <path_to_script_file>
64. How do you write a Hadoop command to delete a file or directory in HDFS?
The syntax to delete a file or directory in HDFS using the Hadoop command is as follows:
hdfs dfs -rm -r <path
65. Describe the role of Pig in Big Data processing.
Pig is a high-level scripting language and platform that simplifies the processing and analysis of Big Data. It provides a data flow language called Pig Latin, which allows users to express complex data transformations and operations in a concise and readable manner. Pig converts these operations into MapReduce tasks to be executed on a Hadoop cluster.
66. What is Hive and how does it facilitate querying in Hadoop?
Hive is a data warehousing infrastructure built on top of Hadoop that provides a SQL-like query language called HiveQL. It allows users to query and analyze structured data stored in Hadoop using familiar SQL syntax. Hive translates HiveQL queries into MapReduce or Tez jobs to process the data efficiently.
67. Explain the concept of data serialization in Hadoop.
Data serialization in Hadoop refers to the process of converting data objects into a binary or text format that can be stored, transmitted, and reconstructed later. Serialization is necessary for efficiently transferring data between nodes in a distributed system and for storing data in formats like SequenceFile or Avro in Hadoop.
68. What is Apache Spark and how does it differ from Hadoop?
Apache Spark is an open-source cluster computing framework that provides high-speed, in-memory data processing for Big Data. Unlike Hadoop, which relies on disk-based storage and MapReduce, Spark utilizes in-memory caching and the Resilient Distributed Dataset (RDD) abstraction to achieve faster and more flexible data processing.
69. Describe the RDD (Resilient Distributed Dataset) in Apache Spark.
RDD stands for Resilient Distributed Dataset, which is a fundamental data structure in Apache Spark. RDD is an immutable distributed collection of objects that can be processed in parallel across a cluster. RDDs provide fault tolerance, allowing for efficient data processing even in the presence of failures.
70. What is the significance of lineage in Spark?
Lineage in Spark refers to the history or lineage graph of an RDD or DataFrame. It tracks the transformations applied to the data starting from the original input data source. Lineage information is crucial for fault tolerance, as it enables Spark to recompute lost or corrupted partitions by replaying the transformations.
71. Explain the concept of lazy evaluation in Spark.
Lazy evaluation is a strategy used in Spark where transformations on RDDs or DataFrames are not immediately executed. Instead, Spark waits until an action is called, such as displaying the result or saving it to storage. This optimization reduces unnecessary computations and allows for efficient execution plans.
72. Differentiate between DataFrame and Dataset in Spark.
In Spark, a data frame is a distributed collection of data organized into named columns, similar to a table in a relational database. It provides a high-level API and supports various data formats. A Dataset, on the other hand, is a strongly-typed, object-oriented API that extends the DataFrame API with additional compile-time type safety.
73. What is the purpose of Spark SQL in Apache Spark?
Spark SQL is a Spark module that provides a programming interface for working with structured and semi-structured data using SQL queries, DataFrame API, or Dataset API. It allows seamless integration of SQL queries and traditional data processing, enabling users to leverage their SQL skills for Big Data analytics.
74. Describe the concept of streaming in Apache Spark.
Streaming in Apache Spark refers to the processing and analysis of real-time data streams in a continuous and near-real-time manner. Spark Streaming ingests data from various sources, such as Kafka or Flume, and processes it in micro-batches, enabling low-latency processing and real-time analytics on streaming data.
75. Explain the difference between batch processing and stream processing.
Batch processing refers to the execution of data processing jobs on a collection of data that is processed as a group or batch. Stream processing, on the other hand, involves the continuous processing of data records as they arrive in real-time. Batch processing is typically used for historical analysis, while stream processing enables real-time monitoring and immediate insights.
76. What is Apache Kafka and how does it facilitate real-time data streaming?
Apache Kafka is a distributed streaming platform that provides a reliable and scalable way to publish, subscribe to, and process streams of data in real time. It uses a distributed commit log architecture that allows high-throughput, fault-tolerant data streaming across multiple applications and systems.
77. Describe the role of Apache Storm in Big Data processing.
Apache Storm is a distributed real-time stream processing system. It enables the processing of high-velocity data streams by dividing the processing tasks into small units called bolts, which are executed in parallel across a cluster of machines. Storm provides fault tolerance and guarantees data processing even in the presence of failures.
78. What are the advantages of using NoSQL databases in Big Data applications?
NoSQL databases offer advantages such as scalability, flexibility, and high performance for handling Big Data. They can handle large volumes of data with horizontal scalability, support flexible data models, and provide fast read and write operations. NoSQL databases are also well-suited for unstructured or semi-structured data.
79. Explain the CAP theorem and its relevance in distributed databases.
The CAP theorem, also known as Brewer’s theorem, states that it is impossible for a distributed system to simultaneously provide consistency (C), availability (A), and partition tolerance (P). In distributed databases, the CAP theorem implies that trade-offs must be made between consistency and availability when dealing with network partitions or failures.
80. Describe the characteristics and use cases of Apache Cassandra.
Apache Cassandra is a highly scalable and distributed NoSQL database designed for handling massive amounts of structured and unstructured data. It offers high availability, fault tolerance, and linear scalability across multiple commodity servers. Cassandra is commonly used for use cases such as time-series data, real-time analytics, and powering high-traffic web applications.
81. What is Apache HBase and how does it differ from traditional relational databases?
Apache HBase is a distributed, column-oriented NoSQL database that runs on top of Hadoop. It provides random access to large amounts of structured data and offers scalability and fault tolerance. Unlike traditional relational databases, HBase does not support SQL queries but is optimized for high-volume, low-latency read/write operations.
82. Explain the concept of sharding in distributed databases.
Sharding is a technique used in distributed databases to horizontally partition data across multiple servers or nodes. Each shard contains a subset of the data, and the database system distributes the workload and storage requirements across the shards. Sharding enables scalability, as data can be distributed and processed in parallel.
83. What is the role of ZooKeeper in distributed systems?
ZooKeeper is a centralized service used for maintaining configuration information, providing distributed synchronization, and ensuring coordination among nodes in a distributed system. It is often used in distributed databases to manage cluster metadata, leader election, and synchronization, providing a reliable foundation for distributed system coordination.
84. Describe the concept of data replication in distributed databases.
Data replication in distributed databases involves creating multiple copies of data and storing them on different nodes or servers. Replication improves fault tolerance and availability, as data can still be accessed even if some nodes fail. It also enhances read performance by allowing data to be served from nearby replicas.
85. Explain the concept of data deduplication in Big Data storage.
Data deduplication is a technique used to eliminate redundant copies of data in storage systems. It identifies and removes duplicate data blocks, storing only unique data once. Data deduplication reduces storage space requirements, improves data efficiency, and minimizes backup and replication costs.
86. What are the key considerations for data privacy and security in Big Data environments?
Data privacy and security in Big Data environments require considerations such as access control mechanisms, encryption of sensitive data, secure data transfer protocols, regular security audits, and compliance with data protection regulations. Additionally, implementing proper authentication and authorization measures, and securing data at rest and in transit is crucial.
87. Describe the concept of a data lake and its benefits in Big Data architectures.
A data lake is a centralized repository that stores large amounts of raw, unprocessed data in its native format. It enables organizations to store diverse data types and formats in a cost-effective manner and allows for flexible data exploration and analysis. Data lakes facilitate data-driven insights and support various data processing frameworks and tools.
88. Explain the concept of data governance and its importance in Big Data.
Data governance encompasses the processes, policies, and controls implemented to ensure the availability, integrity, and security of data. In Big Data environments, data governance becomes even more critical due to the volume, variety, and velocity of data. It involves establishing data quality standards, data lifecycle management, compliance, and data privacy considerations.
89. What is the role of machine learning in Big Data analytics?
Machine learning algorithms play a crucial role in Big Data analytics by enabling automated pattern recognition, predictive modeling, and data-driven insights. Machine learning techniques allow organizations to extract valuable information from large datasets, uncover hidden patterns, and make data-driven decisions.
90. Explain the concept of feature engineering in machine learning with Big Data.
Feature engineering involves transforming raw data into meaningful features that can be used as inputs for machine learning algorithms. It includes tasks such as data cleaning, normalization, scaling, dimensionality reduction, and creating new features from existing ones. Feature engineering is crucial for improving the performance and accuracy of machine learning models.
91. Describe the challenges of real-time analytics with Big Data.
Real-time analytics with Big Data faces challenges such as processing high-velocity data streams, ensuring low-latency data ingestion and processing, handling data consistency and quality, managing infrastructure scalability, and implementing real-time decision-making processes. Additionally, data privacy and security concerns are also significant challenges in real-time Big Data analytics.
92. What is the role of data visualization in Big Data analytics?
Data visualization plays a vital role in Big Data analytics by presenting complex and large datasets in a visual format that is easy to understand and interpret. It helps analysts and decision-makers gain insights from data quickly, identify patterns, trends, and outliers, and communicate findings effectively.
93. Explain the concept of sentiment analysis and its use in social media analytics.
Sentiment analysis, also known as opinion mining, involves using natural language processing and machine learning techniques to determine the sentiment or emotion expressed in text data. In social media analytics, sentiment analysis helps analyze public opinion, customer feedback, and brand perception by classifying text as positive, negative, or neutral.
94. What are the challenges of data integration in Big Data projects?
Data integration in Big Data projects faces challenges such as data format and schema differences, data consistency and quality, data transformation complexities, data lineage tracking, and integrating data from various sources and systems. Ensuring data compatibility and maintaining data integrity are key challenges in the data integration process.
95. What is the role of Apache Beam in Big Data processing?
- Apache Beam is a unified programming model and API for building batch and stream processing pipelines.
- It provides a portable and scalable way to express data processing pipelines across various execution engines, such as Apache Flink, Apache Spark, and Google Cloud Dataflow.
- Beam supports both batch and stream processing paradigms, allowing developers to write code that can be executed on different processing engines without modification.
96. Explain the concept of data governance in Big Data environments.
- Data governance in Big Data refers to the overall management, protection, and control of data assets within an organization.
- It involves defining policies, procedures, and guidelines for data management, ensuring data quality, privacy, and compliance.
- Data governance includes activities such as data classification, metadata management, access control, and data lifecycle management.
97. What are the challenges of data integration in Big Data environments?
- Challenges of data integration in Big Data include data heterogeneity, data volume, and real-time data processing.
- Integrating data from multiple sources with different formats, structures, and data models can be complex and time-consuming.
- Real-time data integration requires efficient data ingestion, transformation, and synchronization mechanisms to ensure data consistency and timeliness.
98. Explain the concept of a data lake in Big Data architectures.
- A data lake is a central repository that stores vast amounts of raw, unprocessed data in its native format.
- It allows data to be stored in a flexible and scalable manner, accommodating structured, semi-structured, and unstructured data.
- Data lakes enable data exploration, advanced analytics, and data-driven decision-making by providing a unified and comprehensive view of the organization’s data.
99. What is the role of Apache Kylin in Big Data analytics?
- Apache Kylin is an open-source distributed analytics engine designed to provide interactive analytics on large-scale datasets.
- It supports high-speed, SQL-like queries and provides sub-second query response times on massive datasets.
- Kylin uses cube-based OLAP (Online Analytical Processing) techniques to pre-aggregate and index data for accelerated query performance.
100. Explain the concept of data skews in Big Data processing.
- Data skew refers to an imbalanced distribution of data across partitions or nodes in a distributed system.
- It occurs when a subset of data has significantly more records or a different distribution than other subsets.
- Data skew can impact performance by causing resource bottlenecks and uneven workload distribution among nodes.
For those aiming to excel in Big Data Technical Interview Questions, freshersnow.com provides a comprehensive compilation of the Top 100 Big Data Questions and Answers. Accessing their valuable insights and Big Data Interview Questions for Freshers will help you stay updated and enhance your knowledge in the field.