
| Join Telegram |  |
| Join Whatsapp Groups |  |
Data Science Interview Questions and Answers: Data science is a collaborative field that delves into raw data, scrutinizes it, and uncovers meaningful patterns that unlock valuable insights. At its core, data science relies on a blend of disciplines including statistics, computer science, machine learning, deep learning, data analysis, data visualization, and a range of other technologies.
In this article, we will provide a comprehensive list of the Top 100 Data Science Interview Questions and Answers suitable for both freshers and experienced individuals. We will also discuss the scope of the Latest Data Science Interview Questions and career opportunities associated with Data Science Technical Interview Questions.
★★ Latest Technical Interview Questions ★★
Data Science Technical Interview Questions
To aid you in your interview preparation, we have curated a comprehensive collection of Data Science Interview Questions for Freshers, featuring the most recent and pertinent inquiries in the field.
Top 100 Data Science Interview Questions and Answers
1. What is the difference between supervised and unsupervised learning?
Supervised learning involves training a model using labeled data, where the input features are mapped to corresponding target labels. In unsupervised learning, there are no target labels, and the algorithm seeks to find patterns or structures in the data on its own.
2. Explain the Central Limit Theorem and its significance in statistics.
The Central Limit Theorem states that the sampling distribution of the mean of any independent and identically distributed random variables will approximate a normal distribution, regardless of the shape of the original population distribution. It is significant because it allows us to make inferences about a population based on a smaller sample.
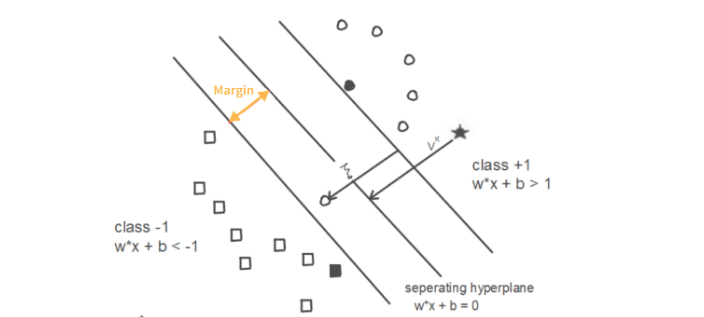
3. What are Support Vectors in SVM (Support Vector Machine)?
In the given diagram, the support vectors are represented by thin lines, indicating their distance from the classifier to the nearest data points (darkened data points). Support vectors can be defined as the data points or vectors that are closest to the hyperplane. These support vectors play a crucial role in determining the position of the hyperplane. As their name suggests, they provide support to the hyperplane and significantly influence its placement and orientation.
4. Difference between Supervised and Unsupervised Learning
| Supervised Learning | Unsupervised Learning |
|---|---|
| Requires labeled training data | Does not require labeled training data |
| Predicts output based on input features and known target variables | Discovers patterns or relationships in data without known target variables |
| Examples include classification and regression algorithms | Examples include clustering and dimensionality reduction algorithms |
| The goal is to generalize the learned patterns to unseen data | The goal is to uncover hidden structures or groupings within the data |
5. What is the curse of dimensionality and how does it impact data analysis?
The curse of dimensionality refers to the challenges that arise when working with high-dimensional data. As the number of dimensions increases, the data becomes more sparse and the distance between points becomes larger. This can lead to difficulties in data analysis, such as increased computational complexity, overfitting, and the need for more data to obtain meaningful results.
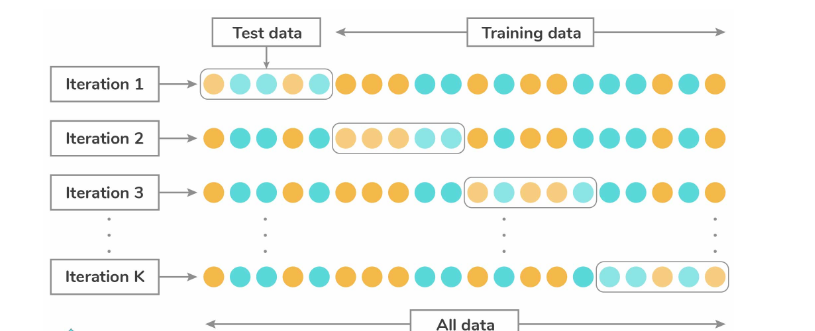
6. What is Cross-Validation?
Cross-validation is a statistical technique employed to enhance the performance of a model. It involves training and testing the model using different subsets of the training dataset, ensuring its effectiveness in handling unfamiliar data. The training data is divided into multiple groups, and the model is iteratively trained and validated against these groups in a rotational manner. By systematically rotating the data subsets, cross-validation provides a robust evaluation of the model’s performance and its ability to generalize to new, unseen data.
The most commonly used techniques are:
- K- Fold method
- Leave p-out method
- Leave-one-out method
- Holdout method
7. Describe the process of feature selection in machine learning.
Feature selection involves choosing a subset of relevant features from the original set of input variables. This process helps to improve model performance, reduce overfitting, and enhance interpretability. Common techniques for feature selection include filter methods, wrapper methods, and embedded methods.
8. What is regularization and why is it important in model training?
Regularization is a technique used to prevent overfitting in machine learning models. It introduces a penalty term to the loss function, which discourages large parameter values. Regularization helps to generalize the model by controlling the complexity and reducing the influence of noisy or irrelevant features.
9. How do you handle missing values in a dataset?
Missing values can be handled by various methods, such as deleting rows or columns with missing values, imputing the missing values with statistical measures like mean or median, using advanced imputation techniques like regression imputation or multiple imputations, or treating missing values as separate category.
10. Why do we need selection bias?
Selection bias occurs when there is a lack of randomization in the process of selecting a subset of the dataset for analysis. This bias indicates that the analyzed sample does not accurately represent the entire population intended for analysis.
For instance, in the provided image, it is evident that the selected sample does not fully reflect the characteristics of the overall population. This raises concerns regarding the appropriateness of the chosen data for analysis and prompts us to question the representativeness of the sample.
11. Explain the concept of transfer learning in deep learning.
Transfer learning is a technique in deep learning where knowledge gained from training one task or domain is transferred and applied to a different but related task or domain. Instead of starting the training of a deep neural network from scratch, transfer learning utilizes pre-trained models that have been trained on large-scale datasets like ImageNet. The pre-trained models learn general features and patterns that are useful across different tasks. By leveraging these learned features, transfer learning enables faster training and improved performance, especially when the new dataset is small or similar to the original dataset.
12. What are the steps involved in a typical machine-learning pipeline?
A typical machine-learning pipeline involves several steps:
- Data collection: Gathering the relevant data required for the task.
- Data preprocessing: Cleaning the data, handling missing values, encoding categorical variables, scaling or normalizing features, etc.
- Feature engineering: Creating new features or transforming existing features to capture relevant information.
- Model selection: Choosing an appropriate model or algorithm based on the problem type and data characteristics.
- Model training: Fitting the chosen model to the training data.
- Model evaluation: Assessing the model’s performance using suitable evaluation metrics and validation techniques.
- Hyperparameter tuning: Optimizing the model’s hyperparameters to improve performance.
- Model deployment: Applying the trained model to new data for predictions or decision-making.
- Monitoring and maintenance: Continuously monitoring the model’s performance and making necessary updates or retraining as required.
13. What is the role of regularization in machine learning?
Regularization is a technique used to prevent overfitting in machine learning models. It involves adding a penalty term to the loss function during training to discourage complex or extreme parameter values. Regularization helps to control the model’s capacity and complexity, making it more robust and less prone to overfitting the training data. It can be achieved through techniques such as L1 and L2 regularization, dropout, early stopping, or model averaging. Regularization encourages models to generalize well to unseen data and improves their performance on new instances.
14. Describe the difference between unsupervised learning and supervised learning.
- Unsupervised learning and supervised learning are two main categories of machine learning techniques:
- Unsupervised learning: In unsupervised learning, the algorithm learns patterns, structures, or representations in the data without explicit labels or target variables. It aims to discover inherent relationships, clusters, or patterns in the data. Common unsupervised learning techniques include clustering, dimensionality reduction, and generative modeling.
- Supervised learning: In supervised learning, the algorithm learns a mapping between input features and corresponding target labels or outputs. The training data consists of labeled examples, where the input features are paired with their corresponding correct outputs. Supervised learning algorithms aim to generalize from the provided examples to make accurate predictions or classifications on unseen data.
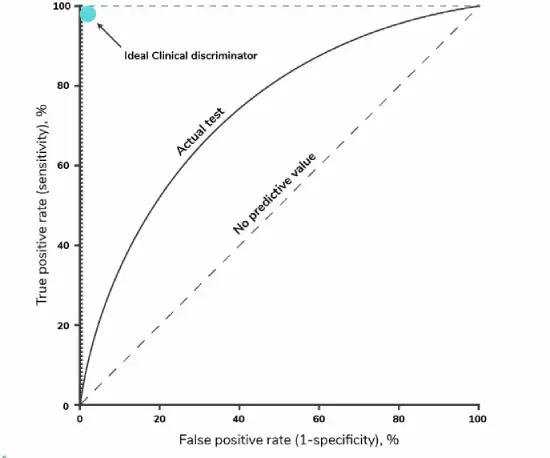
15. What does the ROC Curve represent and how to create it?
The ROC (Receiver Operating Characteristic) curve is a graphical representation that illustrates the relationship between false-positive rates (FPR) and true-positive rates (TPR) at various thresholds. It serves as a visual tool for evaluating the trade-off between sensitivity (TPR) and specificity.
The ROC curve is constructed by plotting the TPR (also known as sensitivity) against the FPR (which is equal to 1 – specificity) at different threshold values. TPR represents the proportion of correctly predicted positive observations out of the total positive observations. In the context of medical testing, TPR signifies the rate at which individuals are accurately identified as having a specific disease.
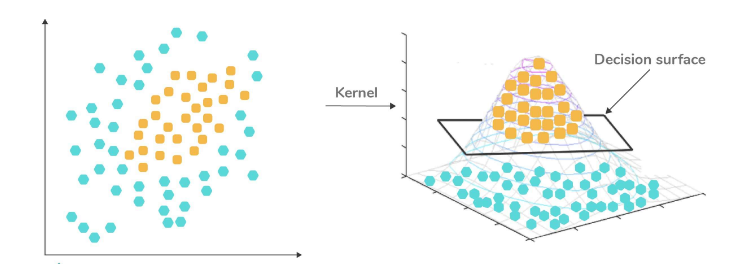
16. What do you understand by a kernel trick?
Kernel functions are mathematical functions that generalize the concept of dot products. They are used to compute the dot product of vectors x and y in a high-dimensional feature space. The kernel trick is a method employed to address non-linear problems by transforming data that is not linearly separable into a form that is separable using a linear classifier. This transformation occurs by mapping the data into a higher-dimensional space.
17. What is the difference between precision and accuracy?
- Precision and accuracy are both evaluation metrics, but they measure different aspects of a model’s performance:
- Precision: Precision measures the proportion of correctly predicted positive instances out of the total instances predicted as positive. It focuses on the accuracy of positive predictions and helps assess the model’s ability to avoid false positives.
- Accuracy: Accuracy measures the proportion of correctly predicted instances (both positive and negative) out of the total instances. It provides an overall measure of correctness and is influenced by both true positives and true negatives.
18. What is the purpose of cross-validation in machine learning?
Cross-validation is a technique used to assess the performance of a machine-learning model. It involves dividing the dataset into multiple subsets or folds, training the model on a subset of the data, and evaluating its performance on the remaining fold. This helps to estimate how the model would perform on unseen data and detect potential issues like overfitting.
19. Explain the difference between precision and recall.
Precision is the ratio of correctly predicted positive instances to the total predicted positive instances. It measures the model’s accuracy in predicting positive cases. Recall, on the other hand, is the ratio of correctly predicted positive instances to the total actual positive instances. It measures the model’s ability to identify all positive cases correctly. Precision focuses on the correctness of positive predictions, while recall focuses on the completeness of positive predictions.
20. What is the ROC curve and what does it represent?
The ROC (Receiver Operating Characteristic) curve is a graphical representation of the performance of a binary classification model. It plots the true positive rate (sensitivity) against the false positive rate (1 – specificity) at different classification thresholds. The ROC curve illustrates the trade-off between sensitivity and specificity and can help determine an optimal threshold for the model.
21. How do you handle imbalanced datasets in classification problems?
Imbalanced datasets occur when one class is significantly more prevalent than the others. To handle this, several techniques can be applied, such as oversampling the minority class (e.g., SMOTE), undersampling the majority class, generating synthetic samples, using ensemble methods like random forests or gradient boosting, or using specific algorithms designed for imbalanced data, such as weighted or cost-sensitive learning.
22. Describe the process of outlier detection and its significance.
Outlier detection involves identifying and handling data points that significantly deviate from the norm or expected patterns. Outliers can distort analysis results and affect model performance. Common approaches for outlier detection include statistical methods like z-score or modified z-score, clustering-based methods, and distance-based methods like Mahalanobis distance or isolation forests.
23. What is the purpose of dimensionality reduction techniques like PCA?
Dimensionality reduction techniques like Principal Component Analysis (PCA) are used to reduce the number of input variables while retaining important information. PCA identifies linear combinations of the original variables, called principal components, which capture the maximum variance in the data. It helps to simplify data representation, remove redundancy, and can improve model performance and interpretability.
24. Explain the concept of ensemble learning and its advantages.
Ensemble learning combines multiple individual models to make predictions. It leverages the diversity and collective intelligence of multiple models to improve overall performance, increase stability, and reduce bias or variance. Ensemble methods like bagging (e.g., random forests) or boosting (e.g., AdaBoost, Gradient Boosting) are widely used in machine learning to enhance predictive accuracy.
25. How do you assess model performance in regression problems?
Model performance in regression problems can be assessed using various evaluation metrics such as mean squared error (MSE), root means squared error (RMSE), mean absolute error (MAE), R-squared (coefficient of determination), or adjusted R-squared. These metrics measure the accuracy, goodness-of-fit, and predictive power of regression models.
26. What is the difference between bagging and boosting algorithms?
Bagging and boosting are both ensemble learning techniques, but they differ in their approach. Bagging (bootstrap aggregating) trains multiple models independently on different subsets of the data and combines their predictions through averaging or voting. Boosting, on the other hand, trains models sequentially, where each subsequent model focuses on correcting the errors made by previous models. Boosting assigns higher weights to misclassified instances to prioritize difficult cases.
27. Describe the Naive Bayes algorithm and its assumptions.
Naive Bayes is a probabilistic classification algorithm based on Bayes’ theorem. It assumes that features are conditionally independent given the class label, which is a strong simplifying assumption. Despite this oversimplification, Naive Bayes performs well in many real-world scenarios and is particularly effective when the independence assumption holds approximately or when dealing with high-dimensional data.
28. How does the k-nearest neighbors algorithm work?
The k-nearest neighbors (k-NN) algorithm is a non-parametric classification or regression method. It assigns a new data point to the majority class or calculates the average of the k nearest data points based on a distance metric (e.g., Euclidean distance). The choice of k determines the number of neighbors considered, and it influences the bias-variance trade-off of the algorithm.
29. What is the purpose of A/B testing in data analysis?
A/B testing, also known as split testing, is a technique used to compare two or more variations of a webpage, marketing campaign, or product feature to determine which performs better. It involves randomly dividing users or samples into different groups, applying different variants, and analyzing the results to make data-driven decisions and optimize performance.
30. Explain the difference between bias and variance in machine learning.
Bias refers to the error introduced by approximating a real-world problem with a simplified model. High bias can lead to underfitting, where the model is too simple to capture the underlying patterns. Variance, on the other hand, measures the model’s sensitivity to fluctuations in the training data. High variance can lead to overfitting, where the model fits the noise in the training data and performs poorly on unseen data.
31. What are the steps involved in the data preprocessing pipeline?
The data preprocessing pipeline typically includes steps such as data cleaning (handling missing values, removing duplicates), data transformation (scaling, normalization), feature selection or extraction, handling categorical variables (encoding, dummy variables), and splitting the data into training and test sets. The specific steps may vary depending on the nature of the data and the requirements of the problem.
32. How do you handle categorical variables in a dataset?
Categorical variables can be handled by encoding them into numerical representations. One common approach is one-hot encoding, where each category is represented by a binary feature (0 or 1). Another approach is label encoding, where each category is assigned a unique integer. The choice of encoding method depends on the nature of the data and the algorithms being used.
33. Describe the process of feature scaling and normalization.
Feature scaling is the process of transforming input features to a similar scale or range. Common techniques include min-max scaling (scaling features to a specific range, e.g., 0 to 1), standardization (transforming features to have zero mean and unit variance), or robust scaling (scaling based on percentiles to handle outliers). Scaling is important for algorithms that are sensitive to the magnitude of features, such as distance-based methods or optimization algorithms.
34. What is the difference between correlation and covariance?
Covariance measures the extent of the linear relationship between two variables. It can be positive (both variables move in the same direction), negative (variables move in opposite directions), or zero (no linear relationship). Correlation, on the other hand, is a standardized measure of the linear relationship between two variables, ranging from -1 (perfect negative correlation) to 1 (perfect positive correlation). Correlation is covariance divided by the standard deviations of the variables, making it easier to interpret and compare.
35. Explain the concept of overfitting and how to avoid it.
Overfitting occurs when a model learns the training data too well, including the noise or random fluctuations. It results in poor generalization of unseen data. To avoid overfitting, techniques such as regularization (e.g., L1 or L2 regularization), cross-validation, early stopping, or using more data can be employed. Simplifying the model, reducing the number of features, or increasing regularization strength can also help mitigate overfitting.
36. How do you assess the importance of features in a model?
Feature importance can be assessed using various methods. Some common approaches include examining the coefficients or weights in linear models, feature importance scores from tree-based models (e.g., random forests, gradient boosting), permutation importance, or using dimensionality reduction techniques like PCA or LASSO regression to identify relevant features. The choice of method depends on the model and the nature of the data.
37. Describe the steps involved in the k-means clustering algorithm.
The k-means algorithm starts by randomly initializing k-cluster centroids. It then alternates between two steps: assigning each data point to the nearest centroid (based on a distance metric such as Euclidean distance) and updating the centroids as the mean of the data points assigned to each cluster. The algorithm converges when the centroids no longer change significantly or after a specified number of iterations.
38. What is the purpose of association rule mining in data science?
Association rule mining aims to discover interesting relationships or patterns among items in large datasets. It identifies frequently occurring itemsets and derives association rules, which express relationships between items based on their co-occurrence. Association rule mining is commonly used in market basket analysis, recommender systems, and understanding customer behavior.
39. Explain the bias-variance trade-off in machine learning.
The bias-variance trade-off is a fundamental concept in machine learning that refers to the balance between model complexity (flexibility) and model generalization (ability to perform well on unseen data). High-bias models are simpler and tend to underfit the data, while high-variance models are more complex and tend to overfit the data. Finding the right balance is crucial for optimal model performance.
40. How do decision trees handle categorical variables?
Decision trees can handle categorical variables by splitting the data based on each category. For example, if a categorical feature has three categories, a decision tree can have three branches corresponding to each category. Various algorithms, like CART (Classification and Regression Trees), use techniques such as binary encoding or one-hot encoding to convert categorical variables into numerical representations that decision trees can work with.
41. What is the purpose of the support vector machine (SVM) algorithm?
The support vector machine algorithm is a powerful supervised learning method used for classification and regression. It aims to find an optimal hyperplane that separates data points of different classes with the largest margin. SVM can handle both linear and non-linear classification problems through the use of different kernels (e.g., linear, polynomial, radial basis function). SVM has the ability to handle high-dimensional data and works well with small to moderate-sized datasets.
41. Difference between Correlation Coefficient and Covariance
| Correlation Coefficient | Covariance |
|---|---|
| Measures the strength and direction of the linear relationship between two variables | Measures the extent to which two variables vary together |
| Ranges between -1 and 1, where -1 indicates a strong negative relationship, 0 indicates no relationship, and 1 indicates a strong positive relationship | Can take any value, with positive values indicating a positive relationship and negative values indicating a negative relationship |
| Is dimensionless and normalized | Depends on the units of the variables being measured |
| Ignores the scale of the variables and only focuses on the relationship | Takes into account both the relationship and the individual variances of the variables |
42. What is the purpose of the “lambda” function in Python, and how is it different from a regular function?
The “lambda” function in Python is used to create anonymous functions on the fly. Unlike regular functions, lambda functions don’t require a def statement and are typically used for short and simple operations.
43. In R, what does the “$” symbol represent when accessing elements within a data frame?
In R, the “$” symbol is used to access specific variables within a data frame. It allows you to retrieve a single column as a vector by specifying the column name after the “$” symbol.
44. How do you handle missing values in SQL when performing calculations or aggregations?
In SQL, missing values can be handled using the “NULL” keyword. Functions like “ISNULL” or “COALESCE” can be used to replace missing values with a default value or handle them in specific ways during calculations or aggregations.
45. Difference between Classification and Regression Algorithms
| Classification Algorithms | Regression Algorithms |
|---|---|
| Predicts categorical or discrete class labels | Predicts continuous numerical values |
| Output is a class or category label | Output is a numeric value |
| Examples include logistic regression, decision trees, and support vector machines | Examples include linear regression, polynomial regression, and random forest regression |
| Evaluation metrics include accuracy, precision, recall, and F1-score | Evaluation metrics include mean squared error, mean absolute error, and R-squared |
46. What is the purpose of the backslash ” ” character in regular expressions?
In regular expressions, the backslash ” ” character is used to escape special characters and give them their literal meaning. For example, to match a literal dot (.), you would use “.” in the regular expression pattern.
47. How can you concatenate two strings in Python, and what is the difference between the “+” operator and the “join” method?
In Python, you can concatenate two strings using either the “+” operator or the “join” method. The “+” operator concatenates strings directly, while the “join” method joins a list of strings by inserting a separator between them.
48. Explain the difference between the “loc” and “iloc” functions in pandas.
In pandas, the “loc” function is used for label-based indexing, where you specify the row and column labels to access data. The “iloc” function, on the other hand, is used for integer-based indexing, where you specify the row and column indices to access data.
49. Difference between Feature Selection and Feature Extraction
| Feature Selection | Feature Extraction |
|---|---|
| Selects a subset of relevant features from the original set | Creates new features by transforming the original set |
| Reduces the dimensionality of the dataset | Also reduces the dimensionality but focuses on creating new representations |
| Examples include methods like filter methods, wrapper methods, and embedded methods | Examples include Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), and Non-negative Matrix Factorization (NMF) |
| Retains the original features but discards irrelevant or redundant ones | Creates new features based on combinations or transformations of the original features |
50. How do you write a conditional statement in R using the “if-else” construct?
In R, the “if-else” construct allows you to write conditional statements. The basic syntax is: “if (condition) { statement } else { statement }”. If the condition is true, the statements within the first block are executed; otherwise, the statements within the second block are executed.
51. What is the purpose of the “@” symbol in Python when defining decorators?
In Python, the “@” symbol is used as syntactic sugar to define decorators. It allows you to modify the behavior of a function by wrapping it with additional functionality without explicitly calling the decorator function.
52. How can you convert a character variable to a numeric variable in R?
In R, you can convert a character variable to a numeric variable using the “as. numeric” function. This function attempts to convert the input to a numeric type, but it will return “NA” for elements that cannot be converted.
53. Difference between Bagging and Boosting in Ensemble Learning
| Bagging | Boosting |
|---|---|
| Involves training multiple models independently on different subsets of the training data | Trains model sequentially, with each model attempting to correct the mistakes of the previous models |
| Each model in the ensemble has equal weight in the final prediction | Models are weighted based on their performance, with more weight given to better-performing models |
| Reduces variance and helps to mitigate overfitting | Focuses on reducing bias and improving the overall predictive power |
| Examples include Random Forest and Extra Trees algorithms | Examples include AdaBoost, Gradient Boosting, and XGBoost |
54. Explain the purpose of the “pass” statement in Python and when it is commonly used.
In Python, the “pass” statement is a null operation that does nothing. It is commonly used as a placeholder when a statement is syntactically required but doesn’t need to perform any action. It can be useful when defining empty functions or placeholder code blocks.
55. Describe the process of natural language processing (NLP).
Natural Language Processing (NLP) is a field of data science that focuses on the interaction between computers and human language. The process involves tasks such as text preprocessing (tokenization, stemming, stop word removal), feature extraction (bag-of-words, TF-IDF), syntactic and semantic analysis (part-of-speech tagging, named entity recognition, parsing), sentiment analysis, topic modeling, and language generation. NLP techniques are used for various applications like chatbots, sentiment analysis, machine translation, and text summarization.
56. How does the random forest algorithm work?
Random forests are an ensemble learning method that combines multiple decision trees. Each tree is trained on a random subset of the data and features, and their predictions are aggregated through voting or averaging. The randomization reduces overfitting and increases model stability. Random forests can handle high-dimensional data, capture non-linear relationships, and provide feature importance estimates.
57. Difference between Precision and Recall
| Precision | Recall |
|---|---|
| Measures the proportion of true positive predictions among the predicted positive instances | Measures the proportion of true positive predictions among the actual positive instances |
| Focuses on the accuracy of positive predictions | Focuses on capturing all the positive instances |
| High precision indicates fewer false positive predictions | High recall indicates fewer false negative predictions |
| Calculated as TP / (TP + FP) | Calculated as TP / (TP + FN) |
| Used in situations where false positives are more critical | Used in situations where false negatives are more critical |
58. What is the purpose of the MapReduce framework in big data processing?
The MapReduce framework is a programming model for processing large-scale datasets in a distributed computing environment. It divides the data into smaller chunks and distributes them across multiple nodes in a cluster. The map phase applies a user-defined function to each data chunk independently, and the reduce phase combines the intermediate results to produce the final output. MapReduce is designed for scalability, fault tolerance, and parallel processing, making it suitable for big data processing tasks.
59. Difference between Data Lake and Data Warehouse
| Data Lake | Data Warehouse |
|---|---|
| Stores data in its raw, unstructured, or semi-structured form | Stores structured and processed data |
| Accommodates any type of data, including raw data, logs, and unprocessed files | Stores data that has been transformed, integrated, and organized for specific business needs |
| Supports schema-on-read, where data can be interpreted and structured at the time of analysis | Uses schema-on-write, where data is defined and structured upfront before loading into the warehouse |
| Designed for flexible and exploratory analysis of large volumes of diverse data | Designed for optimized querying, reporting, and business intelligence purposes |
| Utilizes technologies like Hadoop, Apache Spark, and object storage systems | Utilizes technologies like relational databases, SQL, and OLAP cubes |
60. Explain the concept of deep learning and its applications.
Deep learning is a subset of machine learning that focuses on artificial neural networks with multiple layers (deep architectures). It enables the automatic learning of hierarchical representations from raw data by using multiple levels of abstraction. Deep learning has revolutionized fields like computer vision (image classification, object detection), natural language processing (language modeling, machine translation), speech recognition, and reinforcement learning.
61. Difference between Time Series and Cross-Sectional Data
| Time Series Data | Cross-Sectional Data |
|---|---|
| Represents data collected over a sequence of time periods or intervals | Represents data collected at a specific point in time or for a specific event |
| Examples include stock prices, weather measurements, and daily sales data | Examples include survey data, demographic data, and financial ratios |
| The analysis focuses on temporal patterns, trends, seasonality, and forecasting | The analysis focuses on comparing and analyzing different observations or entities at a specific point in time |
| Requires handling autocorrelation and time dependencies | Does not involve time dependencies or autocorrelation |
| Often analyzed using techniques like autoregressive integrated moving average (ARIMA) and exponential smoothing | Often analyzed using statistical tests, regression analysis, and cross-sectional modeling |
62. How do you handle a class imbalance in classification problems?
Class imbalance occurs when one class has significantly fewer instances than the other. To handle this, techniques such as resampling (oversampling the minority class or undersampling the majority class), using different performance metrics (e.g., precision, recall, F1-score), cost-sensitive learning, or applying specific algorithms for imbalanced data (e.g., SMOTE, ADASYN) can be used. The choice of technique depends on the specific problem and the available data.
63. Describe the process of time series analysis.
Time series analysis involves studying and modeling data points collected over time to uncover patterns, trends, and seasonality. The process typically includes tasks like data visualization, decomposition into the trend, seasonal, and residual components, statistical analysis (autocorrelation, stationarity), selecting appropriate models (ARIMA, SARIMA, exponential smoothing), model fitting and validation, and making future predictions or forecasting.
64. What are some common evaluation metrics for classification problems?
Common evaluation metrics for classification problems include accuracy, precision, recall, F1-score, the area under the ROC curve (AUC-ROC), the area under the precision-recall curve (AUC-PR), and confusion matrix (true positive, true negative, false positive, false negative). These metrics provide insights into the performance of the classification model and help assess its effectiveness in different scenarios.
65. Difference between K-means Clustering and Hierarchical Clustering
| K-means Clustering | Hierarchical Clustering |
|---|---|
| Divides data into a pre-specified number of non-overlapping clusters | Builds a hierarchy of clusters where each observation starts in its own cluster and is recursively merged |
| Requires specifying the number of clusters (k) in advance | Does not require specifying the number of clusters |
| Assigns each data point to the closest centroid based on distance metrics | Builds clusters through a process of merging or splitting based on similarity measures |
| Fast and efficient for large datasets | Slower and more computationally intensive, especially for large datasets |
| Results in a flat structure with distinct clusters | Results in a hierarchical structure with multiple levels of clusters |
66. How do you handle outliers in a dataset?
Outliers can be handled by different methods, depending on the context and nature of the data. Some approaches include removing outliers based on predefined thresholds or statistical measures, transforming the data using robust statistics or winsorization, treating outliers as a separate category, or using outlier-resistant algorithms. The choice of method should be based on careful analysis and domain knowledge.
67. Explain the concept of transfer learning in deep learning.
Transfer learning is a technique where knowledge gained from training a model on one task is transferred and applied to a related but different task. Instead of starting from scratch, a pre-trained model (e.g., a deep neural network trained on a large dataset) is used as a starting point, and the model is fine-tuned on the target task. Transfer learning can save computational resources, reduce training time, and improve performance, especially when the target task has limited training data.
68. What is the difference between overfitting and underfitting in machine learning?
Overfitting occurs when a model performs well on the training data but fails to generalize to unseen data. It happens when the model is too complex, capturing noise or irrelevant patterns in the training data. Underfitting, on the other hand, occurs when a model is too simple to capture the underlying patterns in the data. Underfit models have high bias and perform poorly on both the training and test data. Both overfitting and underfitting are undesirable, and finding the right model complexity is crucial for optimal performance.
69. Difference between L1 and L2 Regularization
| L1 Regularization (Lasso) | L2 Regularization (Ridge) |
|---|---|
| Uses the absolute values of the coefficients as a penalty term | Uses the squared values of the coefficients as a penalty term |
| Encourages sparsity by driving some coefficients to exactly zero | Reduces the impact of less important features but does not drive them to zero |
| Useful for feature selection and identifying important predictors | Useful for preventing overfitting and handling multicollinearity |
| This may result in models with fewer features | Retains all features but reduces their impact |
| Increases model interpretability | Does not enhance interpretability as strongly as L1 regularization |
70. Describe the process of feature extraction in image analysis.
Feature extraction in image analysis involves extracting relevant information or characteristics from images to represent them in a more compact and meaningful way. It includes techniques like edge detection, corner detection, texture analysis, histogram of gradients (HOG), scale-invariant feature transform (SIFT), or convolutional neural networks (CNNs) for automatic feature extraction. The extracted features are then used as input for various image analysis tasks such as object detection, image classification, or image segmentation.
71. What are some common data visualization techniques used in data science?
Common data visualization techniques include bar charts, line charts, scatter plots, histograms, box plots, heat maps, area charts, pie charts, and maps. Visualization tools like Matplotlib, Seaborn, ggplot, or Tableau can be used to create informative and visually appealing visualizations. Data visualization helps in understanding patterns, relationships, and trends in the data, and it aids in communicating findings to stakeholders effectively.
72. How does the backpropagation algorithm work in neural networks?
Backpropagation is the primary algorithm used to train neural networks. It works by calculating the gradients of the network’s weights with respect to a loss function using the chain rule of calculus. The gradients are then used to update the weights in the network, iteratively minimizing the loss function and improving the network’s performance. The process involves forward propagation (computing the predicted outputs) and backward propagation (computing and updating the gradients).
73. Explain the concept of cross-validation in machine learning.
Cross-validation is a technique used to assess the performance and generalization ability of machine learning models. It involves dividing the data into multiple subsets or folds, training the model on a subset of the data, and evaluating its performance on the remaining fold. This process is repeated multiple times, rotating the folds to ensure that each subset is used for both training and testing. Cross-validation helps in estimating the model’s performance on unseen data and can be used to tune hyperparameters or compare different models.
74. What is the purpose of regularization in machine learning?
Regularization is a technique used to prevent overfitting and improve the generalization ability of machine learning models. It introduces a penalty term to the loss function that discourages overly complex models by imposing constraints on the model’s parameters. Common regularization techniques include L1 regularization (Lasso), L2 regularization (Ridge), and elastic net regularization. Regularization helps to find a balance between fitting the training data well and avoiding overfitting, resulting in models that generalize better to unseen data.
75. Describe the process of feature selection in machine learning.
Feature selection is the process of selecting a subset of relevant features from the original set of variables to improve model performance and interpretability. It can be done through various techniques such as filter methods (based on statistical measures or correlation), wrapper methods (using a specific model’s performance as a criterion), or embedded methods (where feature selection is incorporated into the model training process). The goal is to retain the most informative and discriminative features while removing redundant or irrelevant ones.
76. How do you handle missing data in a dataset?
Missing data can be handled by various methods, depending on the nature and extent of missingness. Some common approaches include removing rows or columns with missing data (listwise deletion), imputing missing values with statistical measures like mean, median, or mode, using advanced imputation methods like multiple imputation or regression imputation, or treating missingness as a separate category. The choice of method depends on the amount of missing data, the underlying mechanism causing missingness, and the impact on the analysis.
77. What is the difference between supervised and unsupervised learning?
Supervised learning is a type of machine learning where the model learns from labeled data, meaning the input features are paired with corresponding target labels or responses. The goal is to learn a mapping between the input features and the target labels, enabling the model to make predictions on unseen data. In unsupervised learning, the model learns from unlabeled data, seeking to discover patterns, structures, or relationships in the data without explicit guidance. Unsupervised learning algorithms aim to find hidden patterns or clusters in the data or reduce the dimensionality of the data. The output of unsupervised learning is typically a representation of the data that captures its inherent structure or relationships.
78. What is the purpose of dimensionality reduction in machine learning?
Dimensionality reduction is a technique used to reduce the number of input features or variables while preserving as much relevant information as possible. It is beneficial in several ways: it helps to alleviate the curse of dimensionality, reduces computational complexity, removes noise or redundant features, and can improve the performance of machine learning models. Dimensionality reduction methods include techniques like Principal Component Analysis (PCA), t-SNE, and Linear Discriminant Analysis (LDA).
79. Describe the process of hyperparameter tuning in machine learning.
Hyperparameter tuning involves finding the optimal values for the hyperparameters of a machine-learning model. Hyperparameters are parameters that are not learned from the data but are set by the user before training the model. The process typically includes defining a search space for the hyperparameters, selecting a search strategy (grid search, random search, Bayesian optimization), evaluating the model’s performance using cross-validation, and selecting the hyperparameter values that yield the best performance. Hyperparameter tuning helps to fine-tune the model and optimize its performance on the given task.
80. How does the gradient descent algorithm work?
Gradient descent is an optimization algorithm used to find the minimum of a loss function in machine learning models. It starts by initializing the model’s parameters with random values and iteratively updates the parameters in the direction of the steepest descent (negative gradient). The update is performed by taking small steps (controlled by the learning rate) proportional to the gradient of the loss function with respect to the parameters. The process continues until convergence is reached or a stopping criterion is met.
81. Explain the concept of ensemble learning.
Ensemble learning is a technique that combines multiple individual models (base models or weak learners) to create a more powerful and accurate model. The individual models can be trained independently or sequentially, and their predictions are combined using methods like voting, averaging, or weighted averaging. Ensemble learning can reduce bias, variance, and improve generalization by leveraging the diversity of the individual models. Popular ensemble learning methods include bagging (e.g., random forests), boosting (e.g., AdaBoost, Gradient Boosting), and stacking.
82. What is the purpose of data augmentation in deep learning?
Data augmentation is a technique used to artificially increase the size and diversity of a training dataset by applying various transformations to the existing data. It helps to reduce overfitting and improve the generalization ability of deep learning models. Data augmentation techniques include image rotation, flipping, scaling, cropping, adding noise, or introducing random variations. By creating variations of the training data, data augmentation provides the model with more examples to learn from and helps it generalize better to unseen data.
83. Describe the process of model deployment in machine learning.
Model deployment involves making a trained machine-learning model available for use in a production environment or real-world applications. The process typically includes converting the trained model into a deployable format, integrating it into an application or system, setting up the necessary infrastructure, and ensuring its scalability, reliability, and security. Model deployment may also involve monitoring the model’s performance, handling input/output interfaces, and implementing mechanisms for model updates or version control.
84. What are some challenges or considerations in deploying machine learning models in production?
Deploying machine learning models in production can involve various challenges and considerations. Some common ones include: managing the infrastructure and resources required for model deployment, ensuring the model’s reliability, scalability, and low latency, handling data preprocessing and input/output interfaces, addressing model drift or concept drift over time, monitoring the model’s performance and detecting anomalies, ensuring data privacy and security, and maintaining version control and reproducibility of the deployed models. Proper planning, testing, and collaboration between data scientists, engineers, and stakeholders are essential for successful model deployment.
85. Explain the concept of generative adversarial networks (GANs) in deep learning.
Generative Adversarial Networks (GANs) are deep learning models that consist of two neural networks: a generator and a discriminator. The generator network learns to generate new samples that resemble the training data, while the discriminator network learns to distinguish between the generated samples and real samples from the training data. The two networks are trained in an adversarial manner, where the generator aims to fool the discriminator, and the discriminator aims to correctly classify the samples. GANs are used for tasks like image synthesis, style transfer, and data augmentation.
86. What is the role of activation functions in neural networks?
Activation functions introduce non-linearities to the output of individual neurons in neural networks. They determine whether the neuron should be activated (fire) or not based on the weighted sum of inputs. Activation functions add non-linearities to the network, enabling it to learn complex relationships and capture non-linear patterns in the data. Popular activation functions include sigmoid, tanh, ReLU (Rectified Linear Unit), and softmax. The choice of activation function depends on the task, network architecture, and the desired properties of the activation function (e.g., differentiability, avoiding vanishing/exploding gradients).
87. What is the difference between bagging and boosting?
Bagging and boosting are ensemble learning techniques, but they differ in how they combine multiple models. Bagging (Bootstrap Aggregating) involves training multiple models independently on different subsets of the training data, often using the same base model. The final prediction is made by averaging or voting over the predictions of individual models. Boosting, on the other hand, trains models sequentially, where each model focuses on correcting the mistakes made by the previous models. The final prediction is a weighted combination of the predictions of all models. Boosting gives more emphasis to challenging instances while bagging treats all instances equally.
88. How does the k-means clustering algorithm work?
The k-means clustering algorithm is an unsupervised learning technique used to partition a dataset into k distinct clusters. It works by iteratively assigning each data point to the nearest centroid and updating the centroids based on the mean of the assigned points. The algorithm begins by randomly initializing k centroids, and in each iteration, it assigns data points to the closest centroid and recalculates the centroids’ positions. This process continues until convergence, where the assignments no longer change significantly. The result is k clusters, with each data point assigned to its nearest centroid.
89. What is the curse of dimensionality?
The curse of dimensionality refers to the challenges and limitations that arise when working with high-dimensional data. As the number of features or dimensions increases, the data becomes more sparse and spread out in the feature space. This leads to several issues such as increased computational complexity, a need for more data to obtain reliable statistics, a higher risk of overfitting, and difficulties in visualizing and interpreting the data. The curse of dimensionality highlights the importance of dimensionality reduction techniques and careful feature selection to mitigate the negative effects of high-dimensional data.
90. Explain the concept of precision and recall in binary classification.
Precision and recall are evaluation metrics used in binary classification tasks. Precision measures the proportion of correctly predicted positive instances out of the total instances predicted as positive. It focuses on the accuracy of positive predictions. Recall, on the other hand, measures the proportion of correctly predicted positive instances out of the total actual positive instances. It focuses on the ability to identify all positive instances. Precision and recall are often traded off against each other, and a balance needs to be struck based on the specific problem requirements. The F1 score is a metric that combines precision and recall into a single measure.
91. What is a cross-entropy loss in machine learning?
Cross-entropy loss is a loss function commonly used in machine learning, particularly in classification tasks. It quantifies the dissimilarity between the predicted probabilities and the true labels. Cross-entropy loss is calculated by taking the negative logarithm of the predicted probability assigned to the true class. It penalizes larger errors more than smaller errors, making it effective for optimizing models that aim to produce accurate probability distributions. Minimizing the cross-entropy loss during training helps the model learn the optimal parameters for predicting the correct classes.
92. Describe the process of feature engineering in data science.
Feature engineering involves creating new features or transforming existing features to improve the performance of machine learning models. It includes tasks such as selecting relevant features, creating interaction or polynomial features, scaling or normalizing features, encoding categorical variables, handling missing values, and applying various mathematical or domain-specific transformations. Feature engineering aims to provide the model with informative and discriminative features that capture the underlying patterns and relationships in the data. It requires a combination of domain knowledge, creativity, and iterative experimentation to identify the most relevant features for the task at hand.
93. How does the Naive Bayes classifier work?
The Naive Bayes classifier is a probabilistic classification algorithm based on Bayes’ theorem. It assumes that the features are conditionally independent given the class label, hence the term “naive.” The classifier calculates the probability of each class given the observed features and assigns the data point to the class with the highest probability. To make predictions, it uses the joint probability distribution of the features and the class labels, along with prior probabilities. Despite the strong assumption of feature independence, Naive Bayes classifiers often perform well and are computationally efficient.
94. What is the purpose of L1 and L2 regularization in machine learning?
L1 and L2 regularization are techniques used to prevent overfitting in machine learning models. L1 regularization, also known as Lasso regularization, adds a penalty term to the loss function that encourages sparsity by promoting feature selection. It tends to drive some feature weights to exactly zero, effectively performing feature selection. L2 regularization, also known as Ridge regularization, adds a penalty term that encourages smaller weights for all features but does not drive them to zero. L2 regularization helps to prevent overfitting by shrinking the weights towards zero, reducing the model’s complexity.
95. Explain the concept of bias-variance trade-off in machine learning.
The bias-variance trade-off is a fundamental concept in machine learning that deals with the relationship between the model’s bias and its variance. Bias refers to the error introduced by approximating a real-world problem with a simplified model, while variance refers to the model’s sensitivity to fluctuations in the training data. Models with high bias tend to underfit the data, while models with high variance tend to overfit the data. Finding the right balance between bias and variance is crucial for building models that generalize well to unseen data. Regularization techniques, ensemble methods, and appropriate model selection can help achieve a good bias-variance trade-off.
96. What are some common preprocessing techniques in data science?
Preprocessing techniques are applied to the data before feeding it into a machine-learning model. Some common preprocessing techniques include handling missing values (imputation or removal), encoding categorical variables (one-hot encoding, label encoding), scaling or normalizing numerical features (min-max scaling, standardization), handling outliers, feature scaling, and dimensionality reduction. Preprocessing techniques help to improve the quality and suitability of the data for modeling, reduce noise or inconsistencies, and ensure compatibility with the chosen algorithms.
97. Describe the difference between overfitting and underfitting in machine learning.
Overfitting and underfitting are two common problems in machine learning related to the model’s ability to generalize to unseen data. Overfitting occurs when the model learns the training data too well, capturing noise or random fluctuations and performing poorly on new data. It usually happens when the model is too complex or when there is insufficient regularization. Underfitting, on the other hand, occurs when the model is too simple or lacks the capacity to capture the underlying patterns in the data. It leads to poor performance on both the training and test data. Finding the right balance is crucial to achieving good generalization performance.
98. What is the purpose of a validation set in machine learning?
A validation set is a subset of the available data that is used to evaluate the performance of a trained machine learning model during training. It is used to tune hyperparameters, compare different models or architectures, and make decisions regarding model selection and optimization. The validation set provides an estimate of how the model is expected to perform on unseen data, helping to assess its generalization ability. By evaluating multiple models on the validation set, one can make informed decisions about the model’s performance and select the best model for deployment or further testing.
99. Describe the concept of reinforcement learning.
Reinforcement learning is a branch of machine learning that involves an agent interacting with an environment to learn a policy that maximizes cumulative rewards. The agent learns through trial and error, receiving feedback in the form of rewards or penalties for its actions. Reinforcement learning is based on the idea of an agent taking actions to transition from one state to another, and receiving rewards or penalties based on those transitions. The agent learns to make optimal decisions by exploring the environment, exploiting learned knowledge, and updating its policy through techniques like Q-learning or policy gradients.
100. What are some challenges in training deep neural networks?
Training deep neural networks can be challenging due to several factors. Some common challenges include vanishing or exploding gradients, where the gradients become too small or too large during backpropagation, leading to slow convergence or unstable training. Overfitting is another challenge, where the model becomes too complex and starts to memorize the training data instead of generalizing. Large-scale datasets may pose challenges in terms of memory and computational resources. Hyperparameter tuning, selecting the appropriate network architecture, and dealing with issues like data imbalance or noisy data are also important considerations in training deep neural networks.
Gaining proficiency in the Top 100 Data Science Interview Questions and Answers can offer job seekers a competitive edge in securing employment and progressing in their Data Science careers. Expand your knowledge and skills by joining us at freshersnow.com, where you can enhance your understanding of the subject.