
| Join Telegram |  |
| Join Whatsapp Groups |  |
Data Structure Interview Questions and Answers – Data Structure is a fundamental concept in computer science and programming, which refers to organizing and storing data in an efficient and optimized manner. With the vast amount of data being generated and processed daily, having a thorough understanding of data structures is essential for developers, software engineers, and other professionals in the field. Now, aspirants looking for Commonly Asked Data Structure Interview Questions can have a look at this article and prepare well for their interview.
Data Structure Technical Interview Questions
Data Structure Interview Questions and Answers provide a valuable way to evaluate your knowledge of this important topic and prepare for technical interviews. In this article, we will discuss the Top 100 Data Structure Interview Questions and Answers to help you in your interview process so that you can succeed in it without any nervousness.
Top 100 Data Structure Interview Questions and Answers
1. What are data structures?
Answer: Data structures are a way of organizing and storing data in a computer so that it can be accessed and used efficiently.
2. What are the different types of data structures?
Answer: The different types of data structures include arrays, linked lists, stacks, queues, trees, graphs, hash tables, and heaps.
3. What is an array?
Answer: An array is a collection of elements of the same data type, which are stored in contiguous memory locations.
4. What is a linked list?
Answer: A linked list is a collection of nodes that contain data and a pointer to the next node in the list.
5. What is a stack?
Answer: A stack is a data structure that stores elements in a last-in, first-out (LIFO) order.
6. What is a queue?
Answer: A queue is a data structure that stores elements in a first-in, first-out (FIFO) order.
7. What is a tree?
Answer: A tree is a data structure that consists of nodes connected by edges. Each node can have zero or more child nodes.
8. What is a graph?
Answer: A graph is a data structure that consists of vertices (nodes) and edges that connect the vertices.
9. What is a hash table?
Answer: A hash table is a data structure that uses a hash function to map keys to values, allowing for fast retrieval of data.
10. What is a heap?
Answer: A heap is a binary tree data structure that satisfies the heap property: the value of each node is greater than or equal to the values of its children.
11. What is the difference between an array and a linked list?
Answer: An array is stored in contiguous memory locations, while a linked list is made up of nodes that are scattered throughout memory.
12. What is the difference between a stack and a queue?
Answer: A stack uses a last-in, first-out (LIFO) order, while a queue uses a first-in, first-out (FIFO) order.
13. What is the difference between a binary tree and a binary search tree?
Answer: A binary tree can have any value in its nodes, while a binary search tree has the property that the value of each node is greater than or equal to the values of its left subtree and less than or equal to the values of its right subtree.
14. What is the time complexity of accessing an element in an array?
Answer: The time complexity of accessing an element in an array is O(1).
15. What is the time complexity of accessing an element in a linked list?
Answer: The time complexity of accessing an element in a linked list is O(n).
16. What is the time complexity of pushing an element onto a stack?
Answer: The time complexity of pushing an element onto a stack is O(1).
17. What is the time complexity of adding an element to a queue?
Answer: The time complexity of adding an element to a queue is O(1).
18. What is the time complexity of searching for an element in a binary search tree?
Answer: The time complexity of searching for an element in a binary search tree is O(log n).
19. What is the time complexity of searching for an element in a hash table?
Answer: The time complexity of searching for an element in a hash table is O(1) on average.
20. What is the time complexity of inserting an element into a heap?
Answer: The time complexity of inserting an element into a heap is O(log n).
21. What is the time complexity of deleting an element from a heap?
Answer: The time complexity of deleting an element from a heap is O(log n).
22. What is the difference between a static and dynamic data structure?
Answer: A static data structure has a fixed size, while a dynamic data structure can grow or shrink as needed.
23. What is the advantage of using a dynamic data structure?
Answer: The advantage of using a dynamic data structure is that it can adapt to the size of the data being stored, resulting in efficient use of memory.
24. What is a Bloom filter, and how does it work?
Answer: A Bloom filter is a probabilistic data structure that is used to test whether an element is a member of a set. It works by using a set of hash functions to generate multiple hash values for each element, and setting the corresponding bits in a bit array. When a query is made, the hash functions are applied to the query element, and the corresponding bits in the bit array are checked to determine if the element is a member of the set.
25. What is a Skip list, and how does it work?
Answer:A Skip list is a data structure that allows for fast search, insertion, and deletion operations with a logarithmic average case time complexity. It works by maintaining a hierarchy of linked lists, where each list contains a subset of the elements in the preceding list. A random decision process determines the number of levels in each list, allowing for efficient search operations without the need for balancing.
26. What is a Fenwick tree, and what are its advantages over other data structures?
Answer:A Fenwick tree, also known as a Binary Indexed Tree, is a data structure that allows for efficient prefix-sum calculations on a dynamic array. It works by storing the cumulative sum of the elements in an array, and updating only the affected nodes when an element is modified. It has the advantage of being more space-efficient and faster than other prefix-sum algorithms like the prefix sum array or segment tree.
27. What is a B-Tree, and how does it differ from a binary search tree?
Answer: A B-Tree is a self-balancing tree data structure that allows for efficient search, insertion, and deletion operations on large data sets. Unlike a binary search tree, a B-Tree node can have more than two children, and its keys are stored in internal nodes instead of leaves. This allows for efficient disk access and reduces the number of disk operations required to perform a search.
28. What is a Treap, and how does it work?
Answer: A Treap is a randomized data structure that combines the properties of a binary search tree and a heap. It works by assigning a random priority value to each node in the tree, and maintaining the binary search tree property using the keys. The heap property is maintained by ensuring that each node has a higher priority than its children.
29. What is a Trie, and what are its advantages over other data structures?
Answer: A Trie is a tree-based data structure used for efficient string searching and prefix matching. It works by storing the characters of a string as a sequence of nodes in a tree, where each node represents a prefix of one or more strings. Tries have the advantage of being more space-efficient and faster than other string matching algorithms like the hash table or binary search tree.
30. What is a Splay Tree, and how does it work?
Answer: A Splay Tree is a self-adjusting binary search tree data structure that reorganizes itself after each access operation, bringing the most recently accessed node to the root. It works by using a combination of rotations and zig-zags to maintain balance, and to ensure that frequently accessed nodes are closer to the root, improving overall access time.
31. What is a Quadtree, and how is it used in computer graphics?
Answer: A Quadtree is a tree-based data structure used for spatial partitioning of two-dimensional space. It works by recursively dividing the space into four quadrants, and storing the data associated with each quadrant in a separate node. Quadtree data structures are commonly used in computer graphics to efficiently represent and process large images, maps, and other graphical data.
32. What is a Radix Tree, and how does it work?
Answer: A Radix Tree, also known as a Patricia Trie, is a tree-based data structure used for efficient string searching and storage. It works by storing strings as a series of nodes, where each node represents a substring of the original string. The nodes are connected using edges that represent a single character, and the tree is constructed in such a way that each node represents a unique substring.
33. What is a Cuckoo Hashing, and how does it work?
Answer: Cuckoo Hashing is a hash-based data structure used for fast key-value lookup. It works by using two hash functions to determine the location of a key in one of two tables. If the location is already occupied, the current key is swapped with the existing one, and the process is repeated until an empty slot is found or a maximum number of swaps is reached. Cuckoo Hashing has the advantage of providing constant-time lookup and insertion, with low overhead and predictable performance.
34. What is the disadvantage of using a dynamic data structure?
Answer: The disadvantage of using a dynamic data structure is that it may require extra overhead to allocate and deallocate memory.
35. What is the difference between a singly linked list and a doubly linked list?
Answer: A singly linked list has nodes that contain a data element and a pointer to the next node, while a doubly linked list has nodes that contain a data element, a pointer to the next node, and a pointer to the previous node.
36. What is the advantage of using a doubly linked list over a singly linked list?
Answer: The advantage of using a doubly linked list is that it allows for efficient traversal in both directions.
37. What is the disadvantage of using a doubly linked list over a singly linked list?
Answer: The disadvantage of using a doubly linked list is that it requires more memory to store the extra pointer for each node.
38. What is a circular linked list?
Answer: A circular linked list is a linked list in which the last node points to the first node, creating a circular structure.
39. What is the advantage of using a circular linked list?
Answer: The advantage of using a circular linked list is that it allows for efficient traversal of the list, as any node can be used as a starting point.
40. What is the disadvantage of using a circular linked list?
Answer: The disadvantage of using a circular linked list is that it can be more complex to implement than a regular linked list.
41. What is a stack frame?
Answer: A stack frame is a block of memory used by a function to store information about its state.
42. What is a call stack?
Answer: A call stack is a stack data structure that stores information about function calls and returns.
43. How is a stack used in recursion?
Answer: In recursion, each recursive call pushes a new stack frame onto the call stack, and each return pops a stack frame off the call stack.
44. What is a postfix expression?
Answer: A postfix expression is an expression in which the operator comes after the operands, such as “3 4 +” instead of “3 + 4”.
45. How can a stack be used to evaluate a postfix expression?
Answer: To evaluate a postfix expression, push each operand onto the stack, and when an operator is encountered, pop the top two operands off the stack, apply the operator, and push the result back onto the stack.
46. What is a queue data structure used for?
Answer: A queue is used to store and retrieve data in a first-in, first-out (FIFO) order.
47. What is a priority queue?
Answer: A priority queue is a data structure that stores elements in a certain order based on their priority.
48. What is the difference between a linear and non-linear data structure?
Answer: A linear data structure has elements that are arranged in a linear sequence, while a non-linear data structure has elements that are not arranged in a linear sequence.
49. What is a binary search algorithm?
Answer: A binary search algorithm is a search algorithm that works by dividing the search space in half at each step, eliminating the half that the target value cannot be in.
50. What is a hash function?
Answer: A hash function is a function that takes a key as input and returns an index into a hash table.
51. What is a collision in a hash table?
Answer: A collision in a hash table occurs when two or more keys are hashed to the same index.
52. How can collisions be resolved in a hash table?
Answer: Collisions can be resolved in a hash table by using a collision resolution strategy, such as chaining or open addressing.
53. What is a binary tree?
Answer: A binary tree is a tree data structure in which each node has at most two children.
54. What is a binary search tree?
Answer: A binary search tree is a binary tree in which the left child of a node contains only values that are less than the node’s value, and the right child of a node contains only values that are greater than the node’s value.
55. What is a balanced tree?
Answer: A balanced tree is a tree in which the heights of the two subtrees of any node differ by at most one.
56. What is a red-black tree?
Answer: A red-black tree is a self-balancing binary search tree in which each node is either red or black, and the root node is always black.
57. What is a B-tree?
Answer: A B-tree is a self-balancing tree data structure that can store large amounts of data on disk or in memory.
58. What is a trie?
Answer: A trie is a tree data structure used to store strings, in which each node represents a prefix or a complete string.
59. What is a graph?
Answer: A graph is a collection of vertices and edges, where the edges connect the vertices.
60. What is a directed graph?
Answer: A directed graph is a graph in which the edges have a direction, from one vertex to another.
61. What is an undirected graph?
Answer: An undirected graph is a graph in which the edges do not have a direction.
62. What is a weighted graph?
Answer: A weighted graph is a graph in which each edge has a weight or cost.
63. What is a breadth-first search (BFS)?
Answer: Breadth-first search is a search algorithm that explores all the vertices in a graph at the current depth before moving on to the vertices at the next depth.
64. What is a depth-first search (DFS)?
Answer: Depth-first search is a search algorithm that explores as far as possible along each branch before backtracking.
65. What is Dijkstra’s algorithm?
Answer: Dijkstra’s algorithm is a shortest path algorithm that finds the shortest path between a source vertex and all other vertices in a weighted graph.
66. What is a minimum spanning tree?
Answer: A minimum spanning tree is a subset of the edges of a weighted, connected graph that connects all the vertices together with the minimum possible total edge weight.
67. What is Kruskal’s algorithm?
Answer: Kruskal’s algorithm is a minimum spanning tree algorithm that finds the minimum spanning tree of a connected, weighted graph.
68. What is Prim’s algorithm?
Answer: Prim’s algorithm is a minimum spanning tree algorithm that finds the minimum spanning tree of a connected, weighted graph.
69. What is a dynamic programming?
Answer: Dynamic programming is a technique used to solve complex problems by breaking them down into smaller, simpler subproblems.
70. What is memoization?
Answer: Memoization is a technique used in dynamic programming to cache the results of expensive function calls and reuse them when the same inputs occur again.
71. What is a divide and conquer algorithm?
Answer: A divide and conquer algorithm is a problem-solving technique that involves breakinga problem down into smaller subproblems, solving each subproblem independently, and then combining the results to solve the original problem.
72. What is the time complexity of merge sort?
Answer: The time complexity of merge sort is O(nlogn).
73. What is the time complexity of quicksort?
Answer: The time complexity of quicksort is O(nlogn) on average and O(n^2) in the worst case.
74. What is the time complexity of binary search?
Answer: The time complexity of binary search is O(logn).
75. What is the time complexity of linear search?
Answer: The time complexity of linear search is O(n).
76. What is a priority queue?
Answer: A priority queue is a data structure that stores elements in a particular order, such that the element with the highest priority is always at the front of the queue.
77. What is a heap?
Answer: A heap is a special type of binary tree that satisfies the heap property, which is that the value of each node is greater than or equal to the values of its children.
78. What is the time complexity of inserting an element into a heap?
Answer: The time complexity of inserting an element into a heap is O(logn).
79. What is the time complexity of deleting the minimum element from a heap?
Answer: The time complexity of deleting the minimum element from a heap is O(logn).
80. In what scenario, Binary Search can be used?
Answer: The Binary Search algorithm is applied to search a pre-sorted list, and it uses a divide and conquer approach as follows
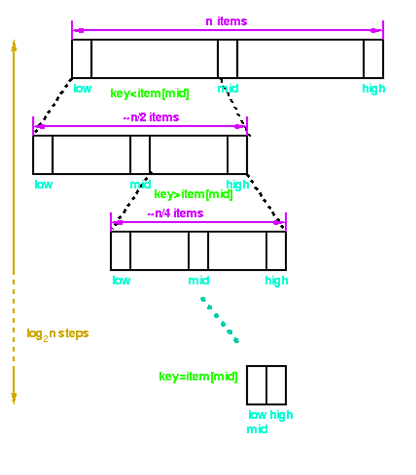
81. What is the differences between B tree and B+ tree?
| Feature | B-trees | B+-trees |
| Leaf nodes | Can contain both keys and data pointers | Only contain keys, with data in the leaves |
| Non-leaf nodes | Can have fewer than the maximum degree | Always have the maximum degree |
| Search | May require traversal of non-leaf nodes | Can often be done with a single traversal |
| Splitting | Splits the node into two new nodes | Splits the node and redistributes its keys |
| Storage | Stores data pointers in the nodes | Stores data only in the leaves |
| Performance | Slower than B+-trees for range queries | Faster than B-trees for range queries |
82. Write a recursive C function to calculate the height of a binary tree.
| int height(struct Node* root) {
// Base case: if the root is null, the height is 0 if (root == NULL) { return 0; } // Recursive case: compute the height of the left and right subtrees int leftHeight = height(root->left); int rightHeight = height(root->right);
// Return the maximum height of the left and right subtrees, plus one for the root return 1 + max(leftHeight, rightHeight); } |
83. Write the C code to perform in-order traversal on a binary tree.
| struct Node {
int data; struct Node* left; struct Node* right; };
void inOrderTraversal(struct Node* root) { if (root != NULL) { inOrderTraversal(root->left); printf(“%d “, root->data); inOrderTraversal(root->right); } } |
84. Define Linked List Data structure
Answer: A linked list is a data structure that consists of a sequence of elements, each containing a reference (or a link) to the next element in the sequence. Unlike arrays, linked lists do not have a fixed size, and the elements are not stored in contiguous memory locations. Instead, each element (or node) in a linked list stores the data and a pointer to the next node. The first node in the list is called the head, and the last node is called the tail, where the tail’s pointer points to NULL. Linked lists are often used in situations where dynamic memory allocation is required, or when it is necessary to insert or delete elements from the list efficiently.
85. What is an AVL tree?
Answer: An AVL tree is a self-balancing binary search tree where the heights of the left and right subtrees of any node differ by at most one. This property is maintained by performing rotations when necessary. AVL trees have a height of O(log n), making them ideal for applications with frequent insertions and deletions. They are also useful in real-time systems where the worst-case time complexity of operations needs to be guaranteed.
86. What is infix, prefix, and postfix in data structure?
Answer:
| Notation | Explanation | Example |
| Infix | The operator is placed in between the operands. This is the most commonly used notation in mathematics. | 5 + 3 * 4 – 2 |
| Prefix | The operator is placed before the operands. Also known as “Polish notation”, it is commonly used in Lisp and other functional programming languages. | – + 5 * 3 4 2 |
| Postfix | The operator is placed after the operands. Also known as “Reverse Polish notation”, it is commonly used in calculators and programming languages such as Forth. | 5 3 4 * + 2 – |
- Infix notation is the most familiar notation, where the operators are placed between the operands, and expressions are evaluated based on operator precedence and associativity rules. In the example 5 + 3 * 4 – 2, the multiplication has higher precedence than addition and subtraction, so the expression is evaluated as (5 + (3 * 4)) – 2.
- Prefix notation, also known as Polish notation, is where the operator is placed before the operands. The expression – + 5 * 3 4 2 is equivalent to 5 + (3 * 4) – 2, where the + operator is applied to the operands 5 and (3 * 4), and then the – operator is applied to the result and 2.
- Postfix notation, also known as Reverse Polish notation, is where the operator is placed after the operands. The expression 5 3 4 * + 2 – is equivalent to 5 + (3 * 4) – 2, where the multiplication operator * is applied to operands 3 and 4, and then the addition operator + is applied to 5 and the result of 3 * 4. Finally, the subtraction operator – is applied to the result of the addition and the operand 2.
87. Explain what is multidimensional arrays?
Answer: Multidimensional arrays employ multiple indices to store data in a database, and they prove useful in situations where data cannot be accommodated with a single dimension index.
88. Explain whether a linked list is considered as a linear or non-linear data structure?
Answer: Whether a linked list is categorized as a linear or non-linear data structure depends entirely on the specific requirements. For instance, if a linked list is employed for storage purposes, it is considered non-linear. However, if it’s used for access strategies, it falls under the category of linear data structures.
89. What is FIFO?
Answer: The term FIFO in data refers to “First in, First Out,” which describes the manner in which data is stored, inserted, and accessed in a queue. In this process, the data inserted at the beginning of the queue is accessed or extracted first before any other data in the queue.
90. Explain what is merge sort and how it is useful?
Answer: A merge sort is a process of dividing and sorting data to achieve a desired end goal. During this process, adjacent elements are merged and sorted to create larger elements, which are then collected to form an even larger list. This iterative process continues until a single, fully sorted list is achieved.
91. Explain the main difference between PUSH and a POP?
Answer: Pushing and Popping are the two primary operations that dictate how data is stored and retrieved in an entity. Pushing refers to the process of adding data to the stack, whereas Popping involves removing data from the stack. During data retrieval, only the topmost available data is considered.
92. What are the applications of a stack in a data structure?
Answer: Here are a few key applications of data structures:
- Evaluating expressions
- Backtracking
- Function calling and return
- Managing memory
- Verifying parenthesis matching in an expression
93. What is the difference between storage structure and file structure?
Answer:
- The fundamental contrast between storage structure and file structure lies in the memory area accessed by each.
- A storage structure refers to a representation of a data structure in the computer’s memory.
- In contrast, a file structure refers to a representation of a storage structure in the auxiliary memory.
94. Name some applications of data structures?
Answer: Here are some common applications of data structures:
- Database management systems
- File systems
- Compilers
- Operating systems
- Network routers
- Artificial intelligence and machine learning algorithms
- Computer graphics and image processing
- Web indexing and searching
- Mathematical analysis and simulations
- Data compression and encryption.
95. What is a doubly-linked list used for?
Answer: A doubly linked list is a more intricate form of a linked list, in which each node contains a pointer to both the previous and the next node in the sequence. It is composed of three elements: node data, a pointer to the next node in the sequence (next pointer), and a pointer to the previous node (previous pointer).
The below diagram depicts the working of doubly linked list:
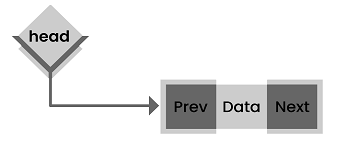
96. What is the difference between stack and heap?
Answer:
- Both stack and heap are utilized for managing memory in computer programs. The stack is typically employed to keep track of method execution order and local variables, and follows a last-in, first-out (LIFO) order.
- In contrast, the heap is used for dynamic allocation and deallocation of memory blocks. It stores objects in Java, and the memory allocated to the heap remains in use until one of the following events occurs: the memory is freed, the program terminates, or the system runs out of memory.
- When dealing with recursive functions, the heap memory tends to be larger compared to the stack, which can quickly fill up the stack memory.
97. Name a few graph data structure applications.
Answer:
- Social networks: Graph data structures can be used to model connections between individuals in social networks such as Facebook, Twitter, and LinkedIn.
- Computer networks: Graph data structures can be used to model network topologies, routing algorithms, and other network-related problems.
- Recommendation systems: Graph data structures can be used to build recommendation systems for e-commerce websites, music streaming services, and other platforms that provide personalized recommendations.
- Geographic information systems (GIS): Graph data structures can be used to model roads, rivers, and other geographic features in GIS applications.
- Image and video processing: Graph data structures can be used to represent visual data such as images and videos, and can be applied in tasks such as object detection, face recognition, and video segmentation.
- Bioinformatics: Graph data structures can be used to represent biological networks such as protein-protein interaction networks and gene regulatory networks.
- Artificial intelligence and machine learning: Graph data structures can be used to model and solve various machine learning problems such as clustering, classification, and recommendation systems.
98. List the types of trees with explanation.
- Binary Tree: A tree data structure where each node can have at most two child nodes.
- Binary Search Tree: A binary tree where the left child node is always smaller than its parent, and the right child node is always greater.
- AVL Tree: A self-balancing binary search tree where the heights of the two child subtrees of any node differ by at most one.
- Red-Black Tree: A self-balancing binary search tree where each node is either red or black, and the root and leaves are always black.
- B-Tree: A tree data structure used for organizing blocks of data where each node can have many child nodes.
- Trie: A tree-like data structure used to store associative arrays where the keys are usually strings.
- Heap: A tree data structure where each parent node is either greater than or less than its child nodes.
- Splay Tree: A self-adjusting binary search tree where the most recently accessed elements are moved to the top of the tree.
- Ternary Tree: A tree data structure where each node has at most three child nodes.
99. Which data structures do you use in DFS and BFS algorithms?
Answer: DFS algorithm utilizes the Stack data structure, whereas the BFS algorithm utilizes the Queue data structure.
100. Can you list the various operations that are available in the stack data structure?
Answer: The stack data structure offers various fundamental operations that facilitate the management of its contents. These operations include:
- Push: This function adds an element to the top of the stack. In the event that the stack is full, this results in an overflow condition.
- Pop: This operation removes the topmost element from the stack. If the stack is empty, a underflow condition occurs.
- Top: This function returns the top element of the stack without modifying the stack itself.
- isEmpty: This function returns a boolean value indicating whether the stack is empty or not.
- Size: This function returns the number of elements currently present in the stack.
After going through these examples of Data Structure Interview Questions, it’s evident that having a strong understanding of essential Data Structures and Algorithms is crucial. You may expect similar questions during your interview, but it’s essential to invest sufficient time in learning and practicing these concepts before attempting such questions. Follow our Freshersnow website for more latest updates on various interview questions.