
| Join Telegram |  |
| Join Whatsapp Groups |  |
Apache Hadoop, an open-source library introduced in 2012 by The Apache Software Foundation (ASF), enables efficient data processing and storage in big data applications. It facilitates parallel analysis of massive datasets, leading to faster insights. Hadoop’s cost-effectiveness stems from storing data on affordable commodity servers functioning as clusters.
We have compiled a comprehensive list of the Top 100 Hadoop Interview Questions and Answers to help you prepare for your upcoming Hadoop Technical Interview.
★★ Latest Technical Interview Questions ★★
Latest Hadoop Interview Questions
Whether you are a fresh graduate or an experienced developer, these Hadoop Interview Questions will help in evaluating your understanding of Hadoop programming concepts, syntax, and best practices. So, let’s explore the realm of Hadoop interview questions and answers and be ready to leave a lasting impression on your interviewer!
Top 100 Hadoop Interview Questions and Answers
1. What is Hadoop and how does it work?
Hadoop is an open-source framework designed for distributed processing and storage of large datasets across clusters of computers. It works by splitting data into smaller chunks and distributing them across multiple nodes in a cluster, allowing for parallel processing and fault tolerance.
2. Explain the key components of Hadoop.
The key components of Hadoop are:
- Hadoop Distributed File System (HDFS): It is a distributed file system that stores data across multiple nodes in a Hadoop cluster.
- Yet Another Resource Negotiator (YARN): It is a resource management framework responsible for managing resources and scheduling tasks in the cluster.
- MapReduce: It is a programming model and processing engine used for distributed processing of large datasets in parallel.
3. Explain the Storage Unit In Hadoop (HDFS).
Hadoop Distributed File System (HDFS) serves as the storage layer for Hadoop. It divides files into data blocks, which are stored across slave nodes in the cluster. The default block size is 128 MB, but it can be adjusted according to specific requirements. HDFS operates under a master-slave architecture and consists of two daemons: DataNodes and NameNode.
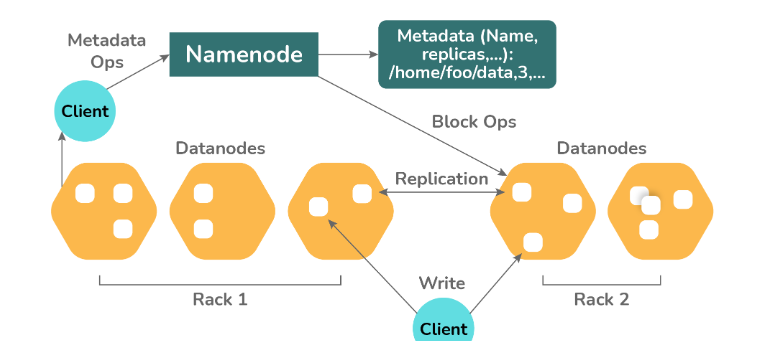
NameNode
The NameNode is the master daemon responsible for managing the filesystem metadata in HDFS. It operates on the master node and stores information such as file names, block data, block locations, permissions, and more. The NameNode also oversees the management of DataNodes, which are responsible for storing the actual data blocks.
DataNode
The DataNodes are slave daemons that operate on the slave nodes within the Hadoop cluster. Their primary role is to store the actual business data. DataNodes handle client read and write requests based on instructions from the NameNode. They store the blocks comprising the files, while the NameNode maintains the metadata such as block locations and permissions.
4. What is the purpose of the Hadoop Distributed File System (HDFS)?
The purpose of HDFS is to provide a scalable and fault-tolerant storage solution for big data. It allows data to be stored across multiple machines in a Hadoop cluster, providing high throughput and reliability.
5. List Hadoop Configuration files.

6. How is data stored in HDFS?
Data is stored in HDFS by breaking it into blocks and distributing these blocks across multiple machines in a Hadoop cluster. Each block is replicated multiple times to ensure fault tolerance.
7. Explain the purpose of the dfsadmin tool?
The dfsadmin tools encompass a specialized set of utilities created to facilitate the retrieval of information about the Hadoop Distributed File System (HDFS). Additionally, these tools offer the capability to perform administrative tasks on HDFS. This combination allows users to gather insights about the file system and carry out necessary administrative operations efficiently.
8. Differences between Hadoop MapReduce and Hadoop Spark
| Hadoop MapReduce | Hadoop Spark | |
|---|---|---|
| Processing Model | Batch processing | Supports both batch and real-time processing |
| Data Processing | Disk-based processing | In-memory processing and caching capabilities |
| Iterative | Not well-suited for iterative algorithms | Efficient iterative processing capabilities |
| Processing Speed | Slower processing speed due to disk access | Faster processing speed with in-memory computing |
| Ease of Use | Simpler programming model | More expressive and user-friendly APIs |
9. What is the role of NameNode in Hadoop?
The NameNode is the central component of HDFS and acts as the master node in a Hadoop cluster. It manages the file system namespace, controls access to files, and keeps track of the metadata for all the files and directories stored in HDFS.
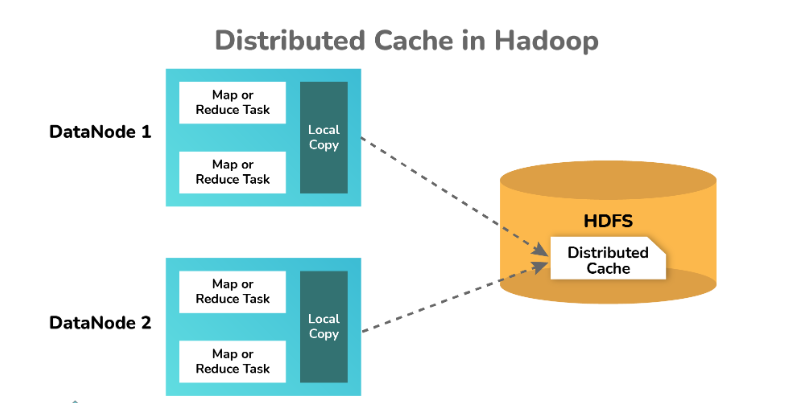
10. Explain the distributed Cache in the MapReduce framework.
The Distributed Cache is a key feature offered by the MapReduce framework in Hadoop, which enables the sharing of files across all nodes in a Hadoop cluster. These files can include various types such as jar files or properties files.
In Hadoop’s MapReduce framework, the Distributed Cache allows the caching and distribution of small to moderate-sized read-only files, such as text files, zip files, and jar files, among others, to all the DataNodes (worker nodes) where MapReduce jobs are executed. Each DataNode receives a local copy of the file, which is transmitted through the Distributed Cache mechanism.
11. What is the role of DataNode in Hadoop?
Data nodes are the worker nodes in a Hadoop cluster that store the actual data. They are responsible for serving read and write requests from clients, as well as performing data block operations like replication and recovery.
12. Differences between Hadoop HDFS and Hadoop MapReduce
| Hadoop HDFS | Hadoop MapReduce | |
|---|---|---|
| Functionality | Distributed file system for storing and managing data | Distributed data processing framework |
| Data Storage | Stores large files in a distributed manner across nodes | Processes data stored in Hadoop HDFS or other sources |
| Data Processing | Primarily handles data storage and retrieval | Processes data using the MapReduce paradigm |
| Scalability | Scales horizontally by adding more DataNodes | Scales horizontally by adding more TaskTrackers |
| Fault Tolerance | Replicates data blocks for fault tolerance | Recovers failed tasks and reassigns them to other nodes |
13. What is MapReduce in Hadoop?
MapReduce is a programming model and processing framework used for distributed processing of large datasets in parallel across a Hadoop cluster. It consists of two main phases: the Map phase, where data is processed in parallel across multiple nodes, and the Reduce phase, where the results from the Map phase are aggregated to produce the final output.
14. How does MapReduce work in Hadoop?
In MapReduce, the input data is divided into smaller chunks, and each chunk is processed independently by the Map tasks running on different nodes in the cluster. The output of the Map tasks is then shuffled and sorted before being passed to the Reduce tasks, which aggregate the results to generate the final output.
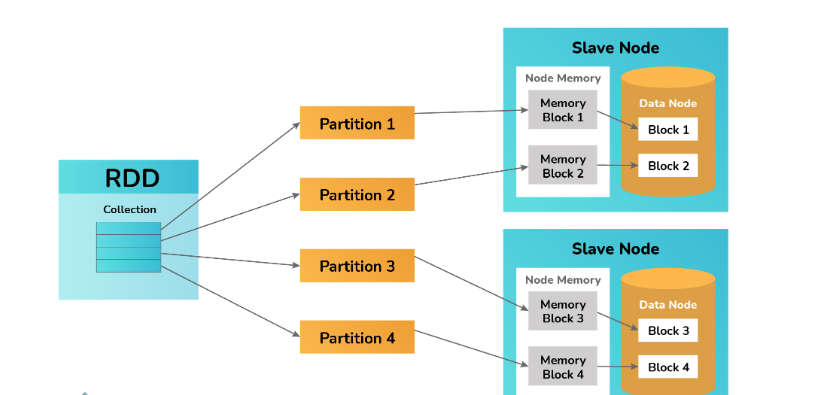
15. Explain the Resilient Distributed Datasets in Spark.
Resilient Distributed Datasets (RDDs) serve as the fundamental data structure in Apache Spark, integrated within the Spark Core. RDDs are immutable and designed to be fault-tolerant. They are created by applying transformations to existing RDDs or by loading external datasets from robust storage systems such as HDFS or HBase. RDDs provide a resilient and distributed approach to processing data in Spark.
16. What are the phases of MapReduce?
The phases of MapReduce are:
- Map phase: In this phase, the input data is divided into smaller chunks and processed independently by the Map tasks.
- Shuffle and Sort phase: In this phase, the intermediate outputs from the Map tasks are collected, sorted, and partitioned before being sent to the Reduce tasks.
- Reduce phase: In this phase, the Reduce tasks receive the intermediate outputs, perform aggregation, and produce the final output.
17. What is the purpose of a combiner in MapReduce?
The purpose of a combiner in MapReduce is to perform local aggregation of the intermediate outputs produced by the Map tasks before sending them to the Reduce tasks. It helps in reducing the amount of data transferred over the network and improves the overall efficiency of the MapReduce job.
18. Differences between Hadoop and traditional relational database systems
| Hadoop | Relational Database Systems | |
|---|---|---|
| Data Structure | Works well with unstructured and semi-structured data | Designed for structured data |
| Scalability | Scales horizontally by adding more nodes | Scales vertically by increasing hardware resources |
| Data Processing | Optimized for batch processing and large-scale analytics | Supports real-time transactional processing |
| Schema Flexibility | The schema-on-read approach allows for flexible data schemas | Schema-on-write approach with fixed schemas |
| Cost | Economical, as it can run on commodity hardware | Requires costly hardware and software licenses |
19. What is the syntax for setting the input and output paths in Hadoop MapReduce?
The syntax for setting input and output paths in Hadoop MapReduce is as follows:
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
20. What is the syntax for running a Hadoop MapReduce job?
The syntax for running a Hadoop MapReduce job is as follows:
hadoop jar <jar_file> <main_class> <input_path> <output_path>
21. What is the syntax for setting the number of reducers in Hadoop MapReduce?
The syntax for setting the number of reducers in Hadoop MapReduce is as follows:
job.setNumReduceTasks(numReducers);
22. What is the syntax for setting the mapper output key and value classes in Hadoop MapReduce?
The syntax for setting the mapper output key and value classes in Hadoop MapReduce is as follows:
job.setMapOutputKeyClass(outputKeyClass); job.setMapOutputValueClass(outputValueClass);
23. Unique features and capabilities that differentiate Apache Hadoop from other big data processing frameworks
| Apache Hadoop | Other Big Data Processing Frameworks | |
|---|---|---|
| Scalability | Designed to scale horizontally by adding more commodity hardware | Offer scalability options, but may vary in implementation |
| Fault Tolerance | Provides built-in fault tolerance through data replication and recovery | Implement fault tolerance mechanisms in different ways |
| Data Processing Paradigm | Primarily based on the MapReduce processing paradigm | Offer a variety of processing paradigms (e.g., Spark, Flink) |
| Ecosystem | Offers a rich ecosystem of related projects and tools | Varies based on the specific framework |
| Data Storage | Provides Hadoop Distributed File System (HDFS) for distributed storage | May use different distributed storage systems |
24. What is the syntax for setting the reducer output key and value classes in Hadoop MapReduce?
The syntax for setting the reducer output key and value classes in Hadoop MapReduce is as follows:
job.setOutputKeyClass(outputKeyClass); job.setOutputValueClass(outputValueClass);
25. What is a partitioner in Hadoop?
A partitioner in Hadoop is responsible for determining which Reducer will receive the output of a particular Map task. It takes the intermediate key-value pairs generated by the Map tasks and assigns them to different Reducers based on a defined logic or algorithm.
26. Explain the concept of InputFormat in Hadoop.
InputFormat in Hadoop defines how to input data is read and split into input splits, which are then assigned to different Map tasks for processing. It determines the logical view of the input data and provides a way to parse and convert it into key-value pairs that can be processed by the Map tasks.
27. What is the significance of the OutputFormat class in Hadoop?
The OutputFormat class in Hadoop defines how the output of a MapReduce job is written to the storage system. It specifies the format and structure of the final output and provides methods to write the output data in the desired format, such as text, sequence files, or custom formats.
28. What are the different types of file formats supported in Hadoop?
Hadoop supports various file formats, including:
- Text file format: Stores data in plain text format.
- Sequence file format: Stores binary key-value pairs.
- Avro file format: Stores data in a compact binary format.
- Parquet file format: Columnar storage format optimized for query performance.
- ORC file format: Optimized Row Columnar format for storing structured data efficiently.
29. What is the difference between InputSplit and Block in Hadoop?
In Hadoop, an InputSplit represents a chunk of input data that is assigned to a Map task for processing. It is a logical division of the input data based on the InputFormat. On the other hand, a block in Hadoop refers to the physical storage division of data in HDFS. It represents a fixed-size portion of a file that is stored on a DataNode.
30. How is data locality achieved in Hadoop?
Data locality in Hadoop refers to the practice of scheduling tasks on nodes that already contain the required data. It is achieved by placing Map tasks closer to the data they need to process, minimizing data transfer over the network. Hadoop achieves data locality by assigning Map tasks to nodes that host the data blocks or replicas of the data being processed.
31. Comparison between Hadoop HDFS and other distributed file systems like Amazon S3 or Google Cloud Storage
| Hadoop HDFS | Amazon S3 | Google Cloud Storage | |
|---|---|---|---|
| Data Storage | Distributed file system | Object storage | Object storage |
| Data Replication | Replicates data blocks for fault tolerance | Offers data replication options | Provides data redundancy mechanisms |
| Consistency Model | Provides strong consistency guarantees | Eventual consistency | Strong consistency guarantees |
| Performance | Optimized for data locality | Scalable and high-performance retrieval | Scalable and high-performance retrieval |
32. What is the role of the Resource Manager in YARN?
The Resource Manager in YARN is responsible for resource allocation and management in a Hadoop cluster. It receives resource requests from applications and schedules them across various nodes in the cluster. The ResourceManager also monitors the health of NodeManagers and tracks the availability of resources.
33. Explain the concept of a container in YARN.
A container in YARN represents a basic unit of resource allocation in a Hadoop cluster. It encapsulates allocated resources (CPU, memory) on a node and provides an execution environment for running application components, such as Map or Reduces tasks.
34. What is the purpose of the NodeManager in YARN?
The NodeManager in YARN is responsible for managing resources on a worker node in a Hadoop cluster. It receives resource allocations from the Resource Manager and monitors resource utilization. The NodeManager also launches and manages containers, running and monitoring the application components assigned to it.
35. Distinctions between Hadoop and Apache Cassandra in terms of data storage and scalability
| Hadoop | Apache Cassandra | |
|---|---|---|
| Data Storage | Distributed file system (HDFS) | Distributed NoSQL database |
| Data Model | Supports structured and unstructured data | Columnar data model |
| Scalability | Scales horizontally by adding more nodes | Linear scalability |
| Consistency Model | Eventual consistency | Tunable consistency levels |
| Query Language | MapReduce, Hive, Pig, Spark, etc. | CQL (Cassandra Query Language) |
| Data Partitioning | Partitioning based on block boundaries | Partitioning based on hash or key range |
36. How does Hadoop handle fault tolerance?
Hadoop handles fault tolerance through various mechanisms:
- Data replication: HDFS replicates data blocks across multiple nodes to ensure data availability in case of node failures.
- Task recovery: If a Map or Reduce task fails, Hadoop reschedules the task on another node to ensure completion.
- Job recovery: If a node fails during a MapReduce job, Hadoop restarts the failed tasks on other nodes to maintain job progress.
37. Explain the concept of speculative execution in Hadoop.
Speculative execution in Hadoop refers to the practice of launching multiple instances of the same task on different nodes to improve job completion time. If a task is progressing slower than others, speculative execution starts additional instances. The instance that completes first is considered the final output, and the others are killed.
38. What is the difference between Hadoop 1. x and Hadoop 2. x?
Hadoop 1. x follows a master-slave architecture, where the JobTracker is the central component for resource management and job scheduling. In contrast, Hadoop 2. x introduces YARN (Yet Another Resource Negotiator) as a separate resource management framework that separates resource management from job scheduling, making it more scalable and flexible.
39. Differentiating characteristics of Hadoop’s data processing framework compared to Apache Flink
| Hadoop | Apache Flink | |
|---|---|---|
| Data Processing Paradigm | Primarily based on MapReduce | Dataflow-based processing |
| Stream Processing | Limited stream processing capabilities | Built-in support for stream processing |
| Event Time Processing | Limited event time processing capabilities | Advanced event time processing features |
| State Management | External state management (e.g., HBase) | Built-in support for distributed state |
| Latency | Higher latency due to batch processing | Lower latency with support for real-time data |
40. What are the limitations of Hadoop?
Some limitations of Hadoop include:
- Hadoop is designed for batch processing and may not be suitable for real-time processing or low-latency requirements.
- Hadoop requires a substantial amount of hardware resources to run efficiently.
- Hadoop’s programming model (MapReduce) may have a steep learning curve for developers accustomed to traditional programming paradigms.
41. How can you monitor Hadoop cluster performance?
Hadoop provides various tools for monitoring cluster performance, including:
- Hadoop Metrics2: A framework for collecting and publishing cluster-wide metrics.
- Hadoop Resource Manager web UI: A web-based interface to monitor cluster resource utilization and job status.
- Hadoop NameNode web UI: Provides information about the health and status of the HDFS.
42. What is the role of Apache ZooKeeper in Hadoop?
Apache ZooKeeper is a centralized coordination service used in Hadoop for distributed systems management. It provides distributed synchronization and coordination services, such as maintaining configuration information, leader election, and distributed locks, which are crucial for the proper functioning of a distributed system like Hadoop.
43. Differences between Hadoop’s data replication approach and redundancy mechanisms in distributed file systems like GlusterFS
| Hadoop | GlusterFS | |
|---|---|---|
| Data Replication | Replicates data blocks across DataNodes | Replicates data across distributed volumes |
| Replication Factor | Typically uses a replication factor of three | Configurable replication factor |
| Fault Tolerance | Provides fault tolerance through data replication | Implements fault tolerance through redundancy mechanisms |
| File System Organization | Organizes data into files and directories | Organizes data into volumes and bricks |
| Scalability | Scales horizontally by adding more nodes | Scales horizontally by adding more storage servers |
44. Explain the concept of data serialization in Hadoop.
Data serialization in Hadoop refers to the process of converting data objects into a binary or text format that can be easily stored, transmitted, and reconstructed later. Hadoop uses serialization frameworks like Apache Avro, Apache Parquet, or Java serialization to serialize data before storing it in HDFS or transferring it between nodes.
45. What is the purpose of a SequenceFile in Hadoop?
A SequenceFile in Hadoop is a binary file format used to store serialized key-value pairs. It provides a compact and efficient way to store large amounts of data, making it suitable for intermediate data storage during MapReduce jobs.
46. How can you configure and manage Hadoop cluster parameters?
Hadoop cluster parameters can be configured and managed through various configuration files, such as core-site.xml, hdfs-site.xml, and yarn-site.xml. These files contain properties that control the behavior of different Hadoop components. By modifying these files, you can customize various aspects of the Hadoop cluster, such as resource allocation, replication factor, and data block size.
47. What is the use of a DistributedCache in Hadoop?
The DistributedCache in Hadoop allows users to cache files (text files, archives, etc.) that are needed by MapReduce tasks. It distributes the cache files to the nodes running the tasks, ensuring that the files are available locally, thereby improving the performance of the tasks that require access to these files.
48. Key distinctions between Hadoop and traditional ETL (Extract, Transform, Load) processes in data integration and analysis
| Hadoop | Traditional ETL | |
|---|---|---|
| Data Processing Paradigm | Primarily designed for batch processing | Supports batch and real-time processing |
| Data Volume | Handles large-scale data processing | Typically handles smaller data volumes |
| Data Variety | Supports structured and unstructured data | Primarily designed for structured data |
| Data Transformation | Enables complex data transformations | Provides extensive data transformation capabilities |
| Scalability | Scales horizontally by adding more nodes | Scalability depends on the underlying ETL tool |
49. Explain the concept of data skew in Hadoop and how to handle it.
Data skew in Hadoop refers to an imbalance in the distribution of data across partitions or reducers, causing some tasks to take significantly longer than others. It can lead to performance degradation. Handling data skew can be done by using techniques such as partitioning strategies, combiners, or custom partitioners to evenly distribute the data and avoid hotspots.
50. What is the purpose of the FairScheduler in YARN?
The FairScheduler in YARN is a pluggable scheduling policy that ensures fair resource allocation among multiple applications running in a Hadoop cluster. It dynamically shares resources based on the configured fair share and priority of each application, allowing for better multi-tenant usage and preventing a single application from monopolizing the resources.
51. Explain the concept of speculative execution in Hadoop reducers.
Speculative execution in Hadoop reducers is the practice of running multiple instances of the same reducer task on different nodes. If a reducer is progressing slower than others, additional instances are launched. The instance that completes first is considered the final output, and the others are killed. This helps to mitigate the impact of slow-running reducers on overall job completion time.
52. What is the role of the ApplicationMaster in YARN?
The ApplicationMaster in YARN is responsible for managing the execution of a specific application or job within the Hadoop cluster. It negotiates resources with the Resource Manager, coordinates the execution of tasks on various nodes, and monitors the progress and health of the application.
53. How does Hadoop handle data integrity?
Hadoop ensures data integrity through various mechanisms:
- Data replication: HDFS replicates data blocks across multiple nodes, and during read operations, it compares the checksum of the data to detect and correct any corruption.
- Checksums: Hadoop computes and verifies checksums for data blocks to ensure their integrity during storage and transmission.
- Data validation: Hadoop provides mechanisms for validating data during processing, such as record-level validation in MapReduce or schema evolution in Hadoop-based data frameworks like Apache Avro or Apache Parquet.
54. What is the significance of speculative execution in Hadoop containers?
Speculative execution in Hadoop containers refers to running multiple instances of the same container on different nodes. It helps mitigate the impact of slow-running containers or nodes by launching additional instances. The instance that completes first is considered the final output, and the others are killed. This improves overall job completion time and resource utilization.
55. Explain how to tune Hadoop for better performance.
To tune Hadoop for better performance, you can consider various factors:
- Adjusting memory settings: Fine-tune the memory allocation for different Hadoop components, such as MapReduce tasks, YARN containers, and JVM heap sizes.
- Optimizing data storage: Configure the replication factor, block size, and compression settings based on the workload characteristics and hardware resources.
- Adjusting parallelism: Modify the number of Map and Reduce tasks, container sizes, and thread settings to match the available resources and workload requirements.
- Utilizing data locality: Optimize data placement and scheduling to maximize data locality, reducing network overhead.
- Monitoring and profiling: Continuously monitor cluster performance, identify bottlenecks, and use profiling tools to analyze and optimize application code.
56. Explain the concept of speculative execution in Hadoop YARN tasks.
Speculative execution in Hadoop YARN tasks involves running multiple instances of the same task on different nodes. It helps mitigate the impact of slow-running tasks by launching additional instances. The instance that completes first is considered the final output, and the others are killed. This improves overall job completion time by preventing a few slow tasks from causing a delay.
57. What is the role of the JobTracker in Hadoop 2. x?
In Hadoop 2. x, the JobTracker has been replaced by the ResourceManager in YARN. The Resource Manager is responsible for resource management and scheduling, whereas the JobTracker was responsible for these tasks in Hadoop 1. x. The Resource Manager handles resource allocation, task scheduling, and job monitoring in a more scalable and flexible manner.
58. How does Hadoop ensure data reliability?
Hadoop ensures data reliability through various mechanisms:
- Replication: HDFS replicates data blocks across multiple nodes, ensuring data availability even if some nodes fail.
- Heartbeat mechanism: Hadoop monitors the health of DataNodes through a heartbeat mechanism. If a DataNode fails to send a heartbeat, it is marked as offline, and its data is replicated to other nodes.
- Data checksums: HDFS computes and verifies checksums for data blocks to detect and correct any corruption during storage or transmission.
59. Explain the concept of job chaining in Hadoop.
Job chaining in Hadoop refers to the practice of running multiple MapReduce jobs in sequence, where the output of one job becomes the input of the next job. It allows for complex data processing workflows by breaking them down into smaller, independent jobs, each performing a specific task. Job chaining enables modular and scalable data processing pipelines in Hadoop.
60. What is the syntax for specifying a custom partitioner in Hadoop MapReduce?
The syntax for specifying a custom partitioner in Hadoop MapReduce is as follows:
< class=”bg-black rounded-md mb-4″>
< class=”p-4 overflow-y-auto”>job.setPartitionerClass(customPartitionerClass);
61. What is the syntax for specifying a custom combiner in Hadoop MapReduce?
The syntax for specifying a custom combiner in Hadoop MapReduce is as follows:
job.setCombinerClass(customCombinerClass);
62. What is the syntax for configuring input and output formats in Hadoop MapReduce?
The syntax for configuring input and output formats in Hadoop MapReduce is as follows:
job.setInputFormatClass(inputFormatClass);
job.setOutputFormatClass(outputFormatClass);
63. How does Hadoop handle data skew in a reduced operation?
Hadoop handles data skew in a reduced operation through techniques such as partitioning, combiners, and custom partitioners. Partitioning ensures that the data is evenly distributed across reducers, avoiding the concentration of a large amount of data in a single reducer. Combiners help reduce the volume of intermediate data by performing local aggregation within each mapper before sending the data to the reducers. Custom partitioners can be implemented to control how data is partitioned based on specific keys or attributes, further optimizing the distribution of data among reducers.
64. What is the role of the Resource Manager in Hadoop YARN?
The Resource Manager in Hadoop YARN is responsible for managing and allocating cluster resources to applications. It receives resource requests from applications and coordinates resource allocation across the cluster. The ResourceManager keeps track of available resources, negotiates resource containers, and schedules tasks on different nodes based on the cluster’s resource availability and allocation policies.
65. What is speculative execution in Hadoop? How does it work?
Speculative execution in Hadoop refers to the process of running duplicate tasks on different nodes simultaneously. It is designed to address the issue of slow-running or straggler tasks that can significantly affect job completion time. Hadoop identifies tasks that are taking longer than average and starts speculative tasks on other nodes. If a speculative task completes first, its output is used, and the output from the slower task is discarded.
66. How does Hadoop ensure fault tolerance in HDFS?
Hadoop ensures fault tolerance in HDFS through data replication and the use of a secondary NameNode. Data replication involves storing multiple copies of each data block on different data nodes. This redundancy allows for data recovery in case of node failures or data corruption. The secondary NameNode periodically checkpoints the primary NameNode’s metadata, providing a backup to restore the file system’s state in the event of a NameNode failure.
67. What is the role of the TaskTracker in Hadoop 1. x?
In Hadoop 1. x, the TaskTracker is responsible for executing tasks on individual nodes in a Hadoop cluster. It receives tasks from the JobTracker, manages their execution, and reports the status and progress back to the JobTracker. The TaskTracker also monitors the health of the node and restarts failed tasks on other nodes if necessary.
68. What is the difference between a block and a file in Hadoop HDFS?
In Hadoop HDFS, a file is divided into multiple blocks, and each block is stored as a separate unit. A block represents a fixed-size chunk of data, typically 64 or 128 megabytes. Files in Hadoop HDFS are not stored as a single continuous unit but are split into blocks and distributed across the cluster’s DataNodes. The file metadata, such as the file name, file size, and block locations, is stored in the NameNode.
69. What is the purpose of the MapReduce framework in Hadoop?
The MapReduce framework in Hadoop is designed for parallel processing and analysis of large datasets. It provides a programming model and execution environment for processing data in a distributed manner across a cluster of nodes. The framework divides the input data into smaller chunks, processes them in parallel using maps and reduce tasks, and produces the final output.
70. How does Hadoop handle data locality optimization?
Hadoop optimizes data locality by scheduling tasks to run on nodes where the data they need is already present or replicated. This minimizes network transfer and improves performance. Hadoop’s scheduler, along with the input split mechanism, ensures that each mapper processes data that is local or nearby, reducing the need to transfer data across the network.
71. What is the purpose of the NameNode in Hadoop HDFS?
The NameNode in Hadoop HDFS is the central component that manages the file system’s metadata. It stores information about the file system’s directory structure, file names, file sizes, and block locations. The NameNode coordinates data access, handles client requests, and ensures data consistency and integrity. It keeps track of the blocks and their locations on DataNodes, enabling efficient data retrieval and fault tolerance.
72. How does Hadoop ensure data reliability in HDFS?
Hadoop ensures data reliability in HDFS through data replication and checksums. Data replication involves storing multiple copies of each data block on different data nodes, typically with a replication factor of three. If a DataNode or block becomes unavailable or corrupted, the replicas can be used to retrieve the data. Additionally, HDFS computes checksums for data blocks during read-and-write operations, allowing for error detection and correction.
73. What is the syntax for setting the Hadoop distributed cache files?
The syntax for setting the Hadoop distributed cache files is as follows:
DistributedCache.addCacheFile(uri, job.getConfiguration());
74. What is the syntax for setting the Hadoop job name?
The syntax for setting the Hadoop job name is as follows:
job.setJobName("job_name");
75. What is the purpose of the Hadoop Distributed File System (HDFS)?
The Hadoop Distributed File System (HDFS) is designed to store and manage large volumes of data across a cluster of commodity hardware. It provides fault tolerance, high throughput, and scalability. HDFS divides data into blocks, replicates them across multiple nodes for reliability, and enables data processing with high aggregate bandwidth.
76. How does Hadoop handle data locality in HDFS?
Hadoop maximizes data locality in HDFS by following the principle of “bring computation to data.” It schedules MapReduce tasks on nodes where the data blocks are stored or replicated, reducing network traffic and improving performance. This locality-aware scheduling ensures efficient data processing by minimizing data transfer across the network.
77. What is speculative execution in the context of MapReduce tasks?
Speculative execution in Hadoop’s MapReduce framework involves running duplicate tasks on different nodes concurrently. If a task is taking longer than expected, additional instances of the same task are launched on different nodes. The task that completes first is considered the valid output, and the others are automatically killed. Speculative execution helps overcome slow or straggler tasks to improve overall job completion time.
78. How does Hadoop handle data processing failures in a MapReduce job?
Hadoop handles data processing failures in a MapReduce job through task retries and task reassignment. If a task fails, Hadoop automatically retries the task on the same node or a different node to ensure successful completion. If a node fails, the tasks running on that node are reassigned to other available nodes to continue the job execution and maintain fault tolerance.
79. What are the different components of Hadoop’s ecosystem?
Hadoop’s ecosystem consists of various components, including:
- Hadoop Distributed File System (HDFS): A distributed file system that stores data across a cluster.
- MapReduce: A programming model and processing framework for distributed data processing.
- YARN: Yet Another Resource Negotiator, a framework for resource management and job scheduling.
- Hive: A data warehouse infrastructure that provides a SQL-like interface for querying and analyzing data stored in Hadoop.
- Pig: A high-level scripting language and platform for analyzing large datasets.
- Spark: A fast and general-purpose cluster computing system for big data processing.
80. Explain the concept of data replication in Hadoop’s HDFS.
Data replication in HDFS is a mechanism to ensure data reliability and fault tolerance. HDFS divides data into blocks, typically 128 MB or 256 MB in size, and replicates each block across multiple nodes in the cluster. By default, the replication factor is set to three, meaning each block is stored on three different nodes. This replication strategy allows data to be available even if some nodes fail and provides high data availability and durability.
81. What is the purpose of a combiner in Hadoop?
A combiner in Hadoop is a mini-reducer that operates on the output of a mapper before sending the data to the reducers. It performs local aggregation and reduces the amount of data transferred across the network, improving the overall efficiency of the MapReduce job. Combiners help to reduce network congestion and enhance the performance of data-intensive operations.
82. How can you control the level of parallelism in Hadoop MapReduce?
The level of parallelism in Hadoop MapReduce can be controlled through the configuration of the number of map tasks and reduced tasks. By adjusting the number of map tasks, you can control the parallel processing of input data. Similarly, by setting the number of reduced tasks, you can determine the parallelism in the output processing phase. Fine-tuning these parameters can optimize the performance and resource utilization of the MapReduce job.
83. What is the purpose of speculative execution in Hadoop MapReduce tasks?
Speculative execution in Hadoop MapReduce tasks is a mechanism to handle slow-running tasks or tasks that are lagging behind others. When speculative execution is enabled, Hadoop starts additional instances of the same task on different nodes. If any of these speculative tasks complete faster than the original task, the output of the fastest task is used, and the others are killed. Speculative execution helps to mitigate the impact of straggler tasks and improve job completion time.
84. Explain the role of a NameNode in Hadoop’s HDFS architecture.
The NameNode is a crucial component of Hadoop’s HDFS architecture. It is responsible for maintaining the metadata about the file system, including file locations, directory structure, and block information. The NameNode keeps the file system namespace and coordinates data read and write operations. It does not store the actual data but keeps track of which data nodes hold the data blocks. The NameNode ensures data consistency, reliability, and high availability in HDFS.
85. How does Hadoop ensure fault tolerance in HDFS?
Hadoop ensures fault tolerance in HDFS through data replication and the use of a secondary NameNode. Data replication involves storing multiple copies of each data block on different data nodes. This redundancy ensures that if a node fails or a block becomes corrupted, the data can be retrieved from the replicas. The secondary NameNode periodically checkpoints the metadata from the primary NameNode, providing a backup in case of NameNode failure.
86. What is the role of a Resource Manager in Hadoop YARN?
The Resource Manager is responsible for resource allocation and management in Hadoop YARN. It receives resource requests from applications, such as MapReduce or Spark, and determines how to allocate resources among different applications and their tasks. The Resource Manager also keeps track of the available resources in the cluster, schedules tasks on various nodes, and monitors their progress.
87. How does Hadoop handle data skew in a MapReduce job?
Hadoop handles data skew in a MapReduce job by using techniques such as combiners, partitioning, and secondary sorting. Combiners help to reduce the size of intermediate data by performing local aggregation, reducing the impact of skewed data. Partitioning ensures that data is evenly distributed across reducers, preventing a single reducer from processing significantly more data than others. Secondary sorting allows for fine-grained sorting within a reducer, helping to balance the workload.
88. What is the purpose of a TaskTracker in Hadoop 1. x?
In Hadoop 1. x, a TaskTracker is responsible for executing tasks on individual nodes in a Hadoop cluster. It communicates with the JobTracker to receive tasks, manages the execution of map and reduce tasks, and reports the status and progress back to the JobTracker. The TaskTracker also monitors the health of the node and restarts failed tasks on other nodes if necessary.
89. Explain the concept of data locality in Hadoop.
Data locality in Hadoop refers to the proximity of data to the computation. It is a key principle in Hadoop’s design, aiming to minimize data transfer over the network. When processing data, Hadoop attempts to schedule tasks on nodes where the data is already present or replicated. This reduces the network overhead and improves performance by utilizing the available data on local disks, resulting in faster processing times.
90. What is the role of the JobHistory Server in Hadoop?
The JobHistory Server in Hadoop is responsible for maintaining information about completed MapReduce jobs. It collects and stores job-level information, including job configuration, counters, and task-level details. The JobHistory Server allows users to access and analyze the historical data of completed jobs, providing insights into job performance, resource utilization, and debugging.
91. How can you optimize data compression in Hadoop?
To optimize data compression in Hadoop, you can consider the following:
- Selecting the appropriate compression codec based on the data characteristics and access patterns. Codecs like Snappy or LZO offer fast compression and decompression, while codecs like Gzip or Bzip2 provide higher compression ratios.
- Tuning the compression level to balance between compression ratio and processing speed. Higher compression levels result in better compression but may increase processing overhead.
- Compressing intermediate data in MapReduce jobs to reduce the amount of data transferred across the network.
- Considering the trade-off between storage savings and CPU utilization when choosing compression options.
92. What is the purpose of a speculative TaskTracker in Hadoop?
A speculative TaskTracker in Hadoop is a backup TaskTracker launched for speculative execution. When Hadoop detects a slow-running task, it launches a speculative task on a different TaskTracker. If the speculative task completes faster, its output is used, and the output from the slow-running task is discarded. Speculative TaskTrackers help to mitigate the impact of straggler tasks and improve job completion time.
93. Explain the role of a Secondary NameNode in Hadoop HDFS.
The Secondary NameNode in Hadoop HDFS assists the primary NameNode in maintaining metadata and provides fault tolerance. It periodically checkpoints the primary NameNode’s metadata and creates a new checkpoint file, combining it with the previous checkpoints. In the event of a primary NameNode failure, the Secondary NameNode can be used to recover the file system’s metadata and restore it to a consistent state.
94. How can you monitor and manage Hadoop cluster performance?
You can monitor and manage Hadoop cluster performance through various tools and techniques:
- Hadoop cluster monitoring tools like Ambari, Cloudera Manager, or Ganglia provide insights into resource utilization, job performance, and health of individual nodes.
- Logging and log analysis can help identify performance bottlenecks and errors in the Hadoop ecosystem components.
- Profiling and performance analysis tools like Hadoop Performance Monitor (HPM) or Apache HTrace can be used to identify resource-intensive tasks, analyze data flows, and optimize job execution.
- Capacity planning and resource management techniques, such as adjusting the number of nodes, memory allocation, and scheduling policies, help optimize resource utilization and prevent bottlenecks.
- Benchmarking and load testing can be performed to assess the cluster’s performance under different workloads and identify areas for improvement.
95. What is speculative execution in Hadoop MapReduce?
Speculative execution in Hadoop MapReduce involves running multiple instances of the same task on different nodes simultaneously. The idea is to have backup or speculative tasks in case the original task is running slower than expected. If a speculative task completes faster, its output is used, and the output from the slower task is discarded. Speculative execution helps to improve job completion time by mitigating the impact of slow-running tasks.
96. How does Hadoop handle data replication across multiple data nodes?
Hadoop handles data replication by dividing data into blocks and storing multiple copies of each block on different data nodes. The replication factor determines the number of copies, typically set to three. Hadoop ensures that these replicas are stored on different racks to ensure fault tolerance. If a DataNode fails or becomes unavailable, the replicas can be accessed from other nodes, ensuring data availability and reliability.
97. What are the benefits of using Hadoop for big data processing?
The benefits of using Hadoop for big data processing include:
- Scalability: Hadoop enables the processing and storage of large volumes of data by distributing the workload across a cluster of commodity hardware.
- Fault tolerance: Hadoop’s distributed nature and data replication ensures high availability and fault tolerance, as data can be recovered from replicas if a node fails.
- Cost-effectiveness: Hadoop utilizes affordable commodity hardware and open-source software, making it a cost-effective solution for big data processing.
- Flexibility: Hadoop supports various data types and can handle structured, semi-structured, and unstructured data, providing flexibility in data processing and analysis.
98. How does Hadoop handle data processing failures in a MapReduce job?
Hadoop handles data processing failures in a MapReduce job through task retries and fault tolerance mechanisms. If a task fails, Hadoop automatically retries the task on the same node or a different node to ensure successful completion. If a node fails, the tasks running on that node are reassigned to other available nodes to continue the job execution. Data replication ensures that even if a node fails, the data can be accessed from other replicas, maintaining data availability and job integrity.
99. Explain the concept of data partitioning in Hadoop MapReduce.
Data partitioning in Hadoop MapReduce refers to the process of dividing the input data into logical partitions based on certain criteria, such as keys or ranges. Each partition is processed independently by a separate reducer, enabling parallel processing. Partitioning allows for efficient data distribution and load balancing across reducers, ensuring that related data is processed by the same reducer and minimizing data transfer across the network.
100. What is the role of a JobTracker in Hadoop 1. x?
In Hadoop 1. x, the JobTracker is responsible for resource management and job scheduling in a Hadoop cluster. It receives job submissions, assigns tasks to available TaskTrackers, monitors task progress, and handles task failures or reassignments. The JobTracker maintains overall control and coordination of the MapReduce jobs, ensuring efficient resource utilization and job completion.
If you’re seeking to excel in technical interviews for Hadoop positions, freshersnow.com offers an extensive collection of the Top 100 Hadoop Questions and Answers. Stay updated and enhance your knowledge by accessing their valuable insights and Hadoop Interview Questions for Freshers.