
| Join Telegram |  |
| Join Whatsapp Groups |  |
Machine Learning Technical Interview Questions: If you’re looking to land a job in the field of Machine Learning, you need to be well-prepared for the interview process. Whether you’re a fresher or an experienced professional, having a good understanding of the latest Machine Learning interview questions and answers is essential. In this article, we have compiled the Top 100 Machine Learning Interview Questions and Answers, which covers a range of Machine Learning technical interview questions that are commonly asked in interviews.
★★ Latest Technical Interview Questions ★★
Machine Learning Interview Questions and Answers
This comprehensive list of Machine Learning interview questions for freshers and experienced professionals will help you to prepare for your next Machine Learning job interview and boost your chances of getting hired.
Top 100 Machine Learning Interview Questions and Answers
1. What is Machine Learning?
Ans: Machine Learning is the field of study that gives computers the ability to learn from data, without being explicitly programmed.
2. What are the different types of Machine Learning?
Ans: There are three types of Machine Learning:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning.
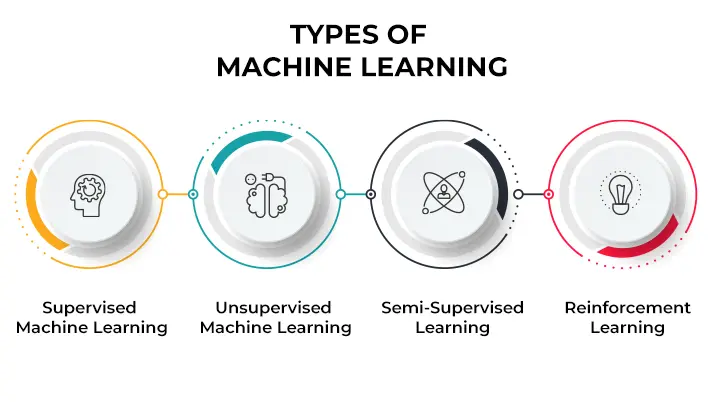
3. What is Supervised Learning?
Ans: Supervised Learning is a type of Machine Learning where the algorithm learns from labeled data, meaning that the data set has predefined labels or outcomes.
4. What is Unsupervised Learning?
Ans: Unsupervised Learning is a type of Machine Learning where the algorithm learns from unlabeled data, meaning that the data set has no predefined labels or outcomes.
5. What is Reinforcement Learning?
Ans: Reinforcement Learning is a type of Machine Learning where the algorithm learns by interacting with an environment, by taking actions and receiving rewards or penalties.
6. What is the difference between supervised and unsupervised learning?
Ans: Supervised Learning involves the use of labeled data to train a model, while Unsupervised Learning involves the use of unlabeled data to train a model.
7. What is Overfitting?
Ans: Overfitting occurs when a model is too complex and fits the training data too well, but fails to generalize well to new data.
8. What is Underfitting?
Ans: Underfitting occurs when a model is too simple and fails to capture the underlying patterns in the data, resulting in poor performance on both the training and test data.
9. What is Bias-Variance Tradeoff?
Ans: Bias-Variance Tradeoff is a key concept in Machine Learning, which refers to the tradeoff between the model's ability to fit the training data and its ability to generalize to new data.
10. What is Cross-Validation?
Ans: Cross-Validation is a technique used to evaluate the performance of a Machine Learning model by dividing the data set into multiple parts and using each part for both training and testing.
11. What is Regularization?
Ans: Regularization is a technique used to prevent overfitting by adding a penalty term to the loss function of the model.
12. What is Gradient Descent?
Ans: Gradient Descent is an optimization algorithm used to find the optimal parameters of a model by minimizing the cost or loss function.
13. What is the syntax for splitting data into training and testing sets in scikit-learn?
Ans:
| from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) |
14. What is a Neural Network?
Ans: A Neural Network is a type of Machine Learning model that is inspired by the structure and function of the human brain, consisting of interconnected nodes or neurons that process and transmit information.
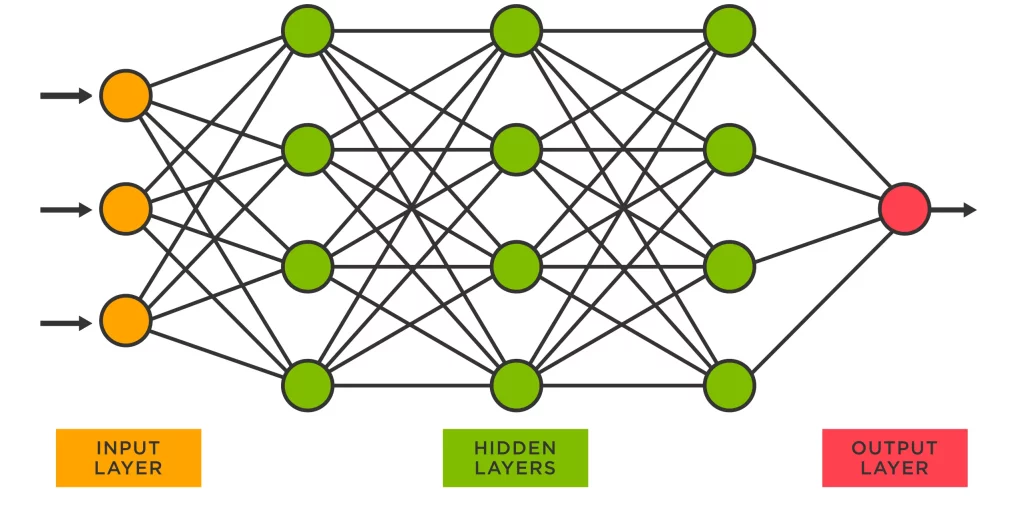
15. What is Deep Learning?
Ans: Deep Learning is a subfield of Machine Learning that uses Neural Networks with multiple layers to learn hierarchical representations of data.
16. What are the differences between Machine Learning and Deep Learning?
Ans: Here are the some of major differences between Machine Learning and Deep Learning.
| Parameter | Machine Learning | Deep Learning |
|---|---|---|
| Definition | ML is Subset of AI that uses algorithms to learn patterns from data | DL is Subset of Machine Learning that uses neural networks to learn patterns from data |
| Data Requirements | ML Needs structured data | DL Can work with both structured and unstructured data |
| Feature Engineering | Requires significant feature engineering | Can automatically learn features from data |
| Training Time | Faster training time | Longer training time due to more complex models |
| Hardware Requirements | ML can work on standard hardware | Requires specialized hardware such as GPUs or TPUs |
| Interpretability | More interpretable as models are simpler | Less interpretable as models are more complex |
| Use Cases | Commonly used in areas such as fraud detection, recommendation systems, and natural language processing | Commonly used in areas such as image and speech recognition, autonomous driving, and robotics |
| Examples | Decision Trees, Random Forest, Naive Bayes, Support Vector Machines (SVM) | Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Deep Belief Networks (DBN) |
17. What is a Convolutional Neural Network?
Ans: A Convolutional Neural Network is a type of Neural Network that is designed for image processing, by using convolutional layers that learn local features of the image.
18. What is a Recurrent Neural Network?
Ans: A Recurrent Neural Network is a type of Neural Network that is designed for sequential data, by using recurrent layers that learn temporal dependencies in the data.
19. What is a Generative Adversarial Network?
Ans: A Generative Adversarial Network is a type of Neural Network that consists of two models, a generator that generates new data, and a discriminator that distinguishes between real and fake data.
20. What is Transfer Learning?
Ans: Transfer Learning is a technique used in Deep Learning, where a pre- trained model is used as a starting point for a new task, by fine -tuning or adapting the model to the new task with a smaller dataset.
21. What is Data Preprocessing?
Ans: Data Preprocessing is a crucial step in Machine Learning, which involves cleaning, transforming, and organizing the data before training the model.
22. What are the different techniques used in Data Preprocessing?
Ans: The different techniques used in Data Preprocessing are Data Cleaning, Data Transformation, and Data Integration.
23. What is Data Cleaning?
Ans: Data Cleaning is the process of identifying and correcting or removing errors, inconsistencies, and missing values from the data.
24. What is Data Transformation?
Ans: Data Transformation is the process of converting the data into a format suitable for Machine Learning, by applying scaling, normalization, and feature selection techniques.
25. What is Data Integration?
Ans: Data Integration is the process of combining multiple data sources into a single, unified format that can be used for Machine Learning.
26. What is Feature Engineering?
Ans: Feature Engineering is the process of selecting, creating, and transforming features or variables in the data to improve the performance of the model.
27. What are the different types of Feature Engineering?
Ans: The different types of Feature Engineering are Feature Scaling, Feature Selection, Feature Extraction, and Feature Construction.
28. What is Feature Scaling?
Ans: Feature Scaling is the process of transforming the values of the features into a similar range to avoid bias towards certain features during model training.
29. What is Feature Selection?
Ans: Feature Selection is the process of selecting the most relevant features for the model to improve its performance and reduce the computational complexity.
30. What is Feature Extraction?
Ans: Feature Extraction is the process of extracting relevant features from the raw data, by applying techniques such as Principal Component Analysis (PCA) or Singular Value Decomposition (SVD).
31. What is Feature Construction?
Ans: Feature Construction is the process of creating new features from existing features, by combining or transforming them in a meaningful way.
32. What is a Decision Tree?
Ans: A Decision Tree is a type of Machine Learning model that uses a tree-like structure to represent a sequence of decisions and their possible consequences.
33. What is Random Forest?
Ans: Random Forest is an ensemble learning method that uses multiple Decision Trees to improve the accuracy and robustness of the model.
34. What is Support Vector Machine?
Ans: Support Vector Machine is a type of Machine Learning model that is used for classification and regression analysis, by finding the optimal hyperplane that separates the data into different classes.
35. What is Naive Bayes?
Ans: Naive Bayes is a probabilistic Machine Learning model that uses Bayes' theorem to predict the probability of a certain event, based on the evidence provided by the data.
36. What is K-Nearest Neighbors?
Ans: K-Nearest Neighbors is a simple Machine Learning model that uses the distance between data points to classify new data points, by finding the k- nearest neighbors.
37. What is Clustering?
Ans: Clustering is a technique used in Unsupervised Learning, where the algorithm groups similar data points together into clusters, based on their similarities or dissimilarities.
38. What is Dimensionality Reduction?
Ans: Dimensionality Reduction is a technique used to reduce the number of features or variables in the data, by selecting the most relevant features or creating new features that capture the underlying patterns in the data.
39. What are the different techniques used in Dimensionality Reduction?
Ans: The different techniques used in Dimensionality Reduction are Principal Component Analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), Linear Discriminant Analysis (LDA), and Autoencoders.
40. What is Principal Component Analysis (PCA)?
Ans: Principal Component Analysis (PCA) is a technique used in Dimensionality Reduction, where the data is transformed into a lower-dimensional space, while preserving the maximum variance in the data.
41. What is t-Distributed Stochastic Neighbor Embedding (t-SNE)?
Ans: t-Distributed Stochastic Neighbor Embedding (t-SNE) is a technique used in Dimensionality Reduction, where the high-dimensional data is mapped onto a two- or three-dimensional space, while preserving the local structure of the data.
42. What is the syntax for fitting a model to training data in scikit-learn?
Ans:
| model.fit(X_train, y_train) |
43. What are Autoencoders?
Ans: Autoencoders are a type of neural network that can be used for Dimensionality Reduction, by learning to encode and decode the data in a lower-dimensional space.
44. What is Overfitting?
Ans: Overfitting occurs when a model is too complex and fits the training data too closely, resulting in poor generalization to new, unseen data.
45. What is Underfitting?
Ans: Underfitting occurs when a model is too simple and fails to capture the underlying patterns in the data, resulting in poor performance on both the training and test data.
46. What is Regularization?
Ans: Regularization is a technique used to prevent overfitting by adding a penalty term to the loss function, which discourages the model from fitting the training data too closely.
47. What are the different types of Regularization?
Ans: The different types of Regularization are L1 Regularization, L2 Regularization, and Dropout.
48. What is L1 Regularization?
Ans: L1 Regularization is a technique used to add a penalty term to the loss function, which encourages the model to use only a subset of the features, resulting in a sparse solution.
49. What is L2 Regularization?
Ans: L2 Regularization is a technique used to add a penalty term to the loss function, which encourages the model to use all the features, but with smaller weights, resulting in a smoother solution.
50. What is Dropout?
Ans: Dropout is a technique used to prevent overfitting by randomly dropping out a fraction of the neurons during training, which forces the remaining neurons to learn more robust features.
51. What is Gradient Descent?
Ans: Gradient Descent is an optimization algorithm used to minimize the loss function by iteratively adjusting the weights of the model in the direction of the negative gradient of the loss function.
52. What are the different variants of Gradient Descent?
Ans: The different variants of Gradient Descent are Batch Gradient Descent, Stochastic Gradient Descent, and Mini-Batch Gradient Descent.
53. What is Batch Gradient Descent?
Ans: Batch Gradient Descent is a variant of Gradient Descent that updates the weights of the model using the gradient of the loss function computed over the entire training dataset.
54. What is Stochastic Gradient Descent?
Ans: Stochastic Gradient Descent is a variant of Gradient Descent that updates the weights of the model using the gradient of the loss function computed on a single training example at a time.
55. What is Mini-Batch Gradient Descent?
Ans: Mini-Batch Gradient Descent is a variant of Gradient Descent that updates the weights of the model using the gradient of the loss function computed on a small batch of training examples at a time.
56. What is Backpropagation?
Ans: Backpropagation is an algorithm used to compute the gradient of the loss function with respect to the weights of the model, by propagating the error backwards through the network.
57. What is a Convolutional Neural Network (CNN)?
Ans: A Convolutional Neural Network (CNN) is a type of neural network that is particularly well-suited for image recognition tasks, by using convolutional layers to extract local features from the input image.
58. What is a Recurrent Neural Network (RNN)?
Ans: A Recurrent Neural Network (RNN) is a type of neural network that is particularly well-suited for sequence prediction tasks, by using recurrent layers to maintain a state that captures the context of the input sequence.
59. What is Transfer Learning?
Ans: Transfer Learning is a technique used to leverage pre-trained models for a new task, by reusing the learned features of the pre-trained model and fine-tuning the model on the new task.
60. What is a Generative Adversarial Network (GAN)?
Ans: A Generative Adversarial Network (GAN) is a type of neural network that can be used to generate new data samples that are similar to the training data, by training two models: a generator model that produces fake data samples, and a discriminator model that tries to distinguish between the fake and real data samples. The two models are trained together in an adversarial manner, where the generator tries to fool the discriminator and the discriminator tries to correctly classify the fake and real data samples.
61. What is the difference between supervised and unsupervised learning?
Ans:
- Supervised learning involves training a model on labeled data, where the correct output is known, while unsupervised learning involves training a model on unlabeled data, where the correct output is not known.
- Supervised learning can be used for tasks such as classification and regression, while unsupervised learning can be used for tasks such as clustering and dimensionality reduction.
62. What is semi-supervised learning?
Ans:
- Semi-supervised learning is a type of learning where a model is trained on a combination of labeled and unlabeled data.
- This approach can be useful in cases where obtaining labeled data is expensive or time-consuming.
63. What is reinforcement learning?
Ans:
- Reinforcement learning is a type of learning where a model learns to make decisions by interacting with an environment and receiving rewards or punishments based on its actions.
- This approach can be useful in cases where the optimal action may not be immediately apparent, and the model must learn through trial and error.
64. What is the difference between regression and classification?
- Regression is a type of supervised learning task where the goal is to predict a continuous output, while classification is a type of supervised learning task where the goal is to predict a discrete output.
- In regression, the model outputs a continuous value, while in classification, the model outputs a class label.
65. What is the bias-variance tradeoff?
Ans:
- The bias-variance tradeoff is a fundamental concept in machine learning that refers to the tradeoff between a model’s ability to fit the training data (bias) and its ability to generalize to new, unseen data (variance).
- A model with high bias may underfit the data, while a model with high variance may overfit the data.
66. What is the syntax for creating a random forest classifier in scikit-learn?
Ans:
| from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() |
67. What is the curse of dimensionality?
Ans:
- The curse of dimensionality is a phenomenon that occurs when the number of features or dimensions in a dataset increases, making it increasingly difficult for a model to learn the underlying patterns in the data.
- This can lead to issues such as overfitting and increased computational complexity.
68. What is the difference between parametric and non-parametric models?
Ans:
- Parametric models make assumptions about the distribution of the data, and the model parameters are fixed regardless of the size of the dataset.
- Non-parametric models do not make assumptions about the distribution of the data, and the model parameters can vary depending on the size of the dataset.
69. What is ensemble learning?
Ans:
- Ensemble learning is a technique where multiple models are combined to improve the overall performance of the system.
- This can involve techniques such as bagging, boosting, and stacking.
70. What is bagging?
Ans:
- Bagging is a technique in ensemble learning where multiple models are trained on different subsets of the data and the final prediction is made by averaging the outputs of the individual models.
- This approach can help to reduce the variance of the model and improve its overall performance.
71. What is boosting?
Ans:
- Boosting is a technique in ensemble learning where multiple weak models are combined to create a strong model.
- This approach involves iteratively training the model, giving more weight to the samples that were misclassified in the previous iterations.
72. What is stacking?
Ans:
- Stacking is a technique in ensemble learning where the predictions of multiple models are used as input to a meta-model that makes the final prediction.
- This approach can help to combine the strengths of multiple models and improve the overall performance of the system.
73. What is a decision tree?
Ans:
- A decision tree is a type of model that uses a tree-like structure to make decisions based on the values of the input features.
- Each internal node of the tree represents a decision based on a feature, and each leaf node represents a class label or a numerical value.
74. What is a random forest?
Ans:
- A random forest is an ensemble learning technique that uses multiple decision trees to make a prediction.
- This approach can help to reduce the variance of the model and improve its overall performance.
75. What is a neural network?
Ans:
- A neural network is a type of model that is inspired by the structure and function of the human brain.
- It consists of layers of interconnected nodes, or neurons, that process and transmit information.
76. What is deep learning?
Ans:
- Deep learning is a type of machine learning that uses neural networks with many layers to learn hierarchical representations of the data.
- This approach has been particularly successful in areas such as image recognition and natural language processing.
77. What is a convolutional neural network (CNN)?
Ans:
- A convolutional neural network is a type of neural network that is particularly well-suited for image recognition tasks.
- It uses convolutional layers to extract features from the input image, and pooling layers to reduce the spatial dimensions of the features.
78. What is a recurrent neural network (RNN)?
Ans:
- A recurrent neural network is a type of neural network that is particularly well-suited for sequence prediction tasks.
- It uses recurrent layers to maintain a state that captures the context of the input sequence.
79. What is the syntax for saving a trained model in scikit-learn?
Ans:
| import joblib joblib.dump(model, ‘model.pkl’) |
80. What is computer vision?
Ans:
- Computer vision is a subfield of machine learning that focuses on the analysis and interpretation of visual data, such as images and videos.
- It has applications in areas such as object detection, facial recognition, and autonomous driving.
81. What is transfer learning?
Ans:
- Transfer learning is a technique used to leverage pre-trained models for a new task, by reusing the learned features of the pre-trained model and fine-tuning the model on the new task.
- This approach can help to reduce the amount of data and computation required to train a model from scratch.
82. What is reinforcement learning?
Ans:
- Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or punishments based on its actions.
- This approach has applications in areas such as robotics, game playing, and autonomous driving.
83. What is adversarial training?
Ans:
- Adversarial training is a technique used to improve the robustness of a machine learning model to adversarial attacks, by training the model on examples generated by an adversary.
- This approach can help to improve the generalization of the model and make it more resistant to attacks.
84. What is active learning?
Ans:
- Active learning is a technique used to improve the efficiency of the training process by selecting the most informative samples for labeling.
- This approach can help to reduce the amount of labeled data required to train a model while maintaining a high level of accuracy.
85. What is unsupervised feature learning?
Ans:
- Unsupervised feature learning is a technique used to learn representations of the input data without the need for labeled examples.
- This approach can be useful in scenarios where labeled data is scarce or expensive to obtain.
86. What is the curse of dimensionality?
Ans:
- The curse of dimensionality refers to the problem of high-dimensional data, where the number of features exceeds the number of samples.
- This problem can lead to overfitting, poor generalization, and increased computational complexity.
87. What is cross-validation?
Ans:
- Cross-validation is a technique used to evaluate the performance of a model by dividing the data into multiple subsets and using each subset as a validation set in turn.
- This approach can help to estimate the generalization performance of the model and avoid overfitting.
88. What is hyperparameter tuning?
Ans:
- Hyperparameter tuning is the process of selecting the optimal values for the hyperparameters of a machine learning model.
- This process can be performed using techniques such as grid search, random search, and Bayesian optimization.
89. What is the difference between classification and regression?
Ans:
- Classification is a type of supervised learning where the goal is to predict a discrete label or category for the input data.
- Regression is a type of supervised learning where the goal is to predict a continuous numerical value for the input data.
90. What is the syntax for creating a linear regression model in scikit-learn?
Ans:
| from sklearn.linear_model import LinearRegression model = LinearRegression() |
91. What is Stochastic Gradient Descent?
Ans: Stochastic Gradient Descent is a variant of Gradient Descent that uses a random subset of the training data to update the parameters of the model.
92. What is the syntax for creating a decision tree classifier in scikit-learn?
Ans:
| from sklearn.tree import DecisionTreeClassifier model = DecisionTreeClassifier() |
93. What is Linear Discriminant Analysis (LDA)?
Ans: Linear Discriminant Analysis (LDA) is a technique used in Dimensionality Reduction, where the data is projected onto a lower-dimensional space while preserving class-discriminatory information.
94. What is the syntax for making predictions with a trained model in scikit-learn?
Ans:
| y_pred = model.predict(X_test) |
95. What is the syntax for evaluating the performance of a classification model in scikit-learn?
Ans:
| from sklearn.metrics import accuracy_score accuracy = accuracy_score(y_test, y_pred) |
96. What is the syntax for scaling data using the StandardScaler in scikit-learn?
Ans:
| from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) |
97. What is feature engineering?
Ans:
- Feature engineering is the process of selecting, transforming, and creating features from raw data to improve the performance of a machine learning model.
- This process can involve techniques such as scaling, normalization, and one-hot encoding.
98. What is the syntax for performing k-fold cross-validation in scikit-learn?
Ans:
| from sklearn.model_selection import cross_val_score scores = cross_val_score(model, X, y, cv=5) |
99. What is natural language processing (NLP)?
Ans:
- Natural language processing is a subfield of machine learning that focuses on the analysis and generation of human language.
- It has applications in areas such as text classification, sentiment analysis, and machine translation.
100. What is the syntax for creating a decision tree in Machine Learning?
Ans: The syntax for creating a decision tree in Machine Learning depends on the programming language and library being used. For example, in Python with the scikit-learn library, the syntax for creating a decision tree classifier is as follows:
| from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier() |
The Top 100 Machine Learning Interview Questions and Answers is a valuable resource for candidates to prepare for their Machine Learning job interviews. It offers an extensive list of technical questions to enhance their understanding of the subject and increase their chances of success. Kindly follow us on freshersnow.com to broaden your knowledge.