
| Join Telegram |  |
| Join Whatsapp Groups |  |
MongoDB Interview Questions and Answers: MongoDB has quickly become one of the most popular NoSQL databases in the world. It is a document-based database that provides high performance, scalability, and flexibility. If you’re preparing for an interview in the field of web development, it’s essential to have a good understanding of MongoDB.
★★ Latest Technical Interview Questions ★★
MongoDB Technical Interview Questions
To help you prepare for your next interview, we’ve compiled a list of the top 100 MongoDB interview questions and answers. This list includes the latest MongoDB Interview Questions for Freshers. In this article, we’ll cover everything you need to know about MongoDB to help you ace your next interview.
Top 100 MongoDB Interview Questions and Answers
1. What is MongoDB?
Answer: MongoDB is a popular NoSQL database that is open-source and implemented in C++. It utilizes JSON-like documents that can be schema-less if desired. With its inherent scalability and cross-platform capabilities, MongoDB has become a preferred choice among developers. It is based on the concepts of collections and documents, and can support secondary indexes, range queries, sorting, aggregations, and geospatial indexes. MongoDB was developed by MongoDB Inc. and is licensed under the Server Side Public License (SSPL).
2. What are the key features of MongoDB?
Answer:
- Document-oriented data model
- Dynamic schema
- Scalability and flexibility
- High availability and automatic sharding
- Ad-hoc queries
- Indexing and aggregation
3. How does MongoDB differ from SQL databases?
Answer: MongoDB is a NoSQL database system, while SQL databases use a relational data model. MongoDB also uses dynamic schema, while SQL databases require a predefined schema.
4. What are the different types of NoSQL databases?
Answer: There are four types of NoSQL databases:
- Document Oriented
- Key Value
- Graph
- Column Oriented
5. What are the benefits of using MongoDB?
Answer:
- Scalability
- Performance
- Flexibility
- High availability and automatic sharding
- Easy integration with other technologies
- Open source
6. What is a document in MongoDB?
Answer: A document is a basic unit of data in MongoDB. It is a data structure composed of field-value pairs.
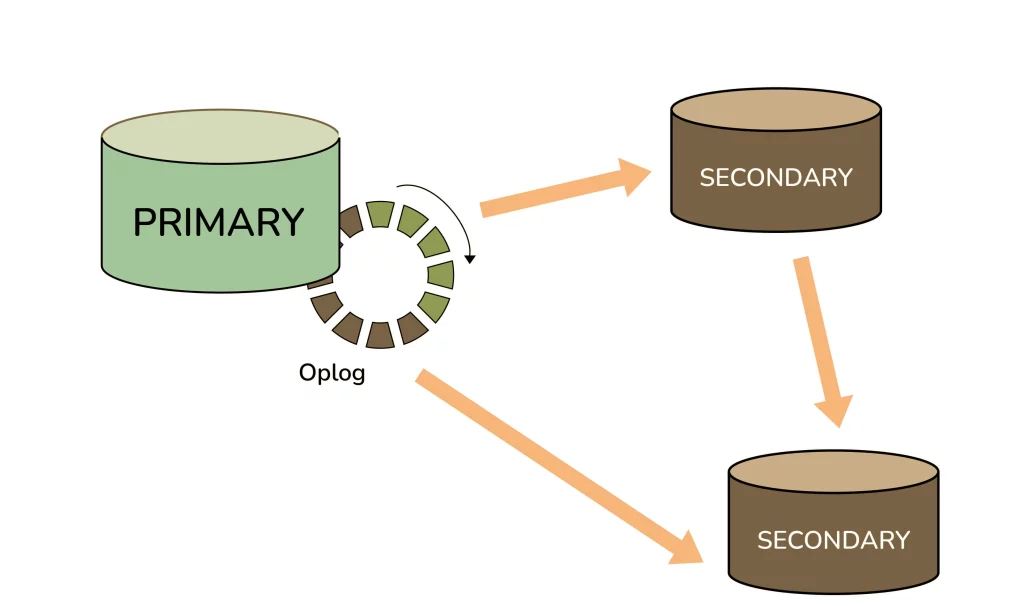
7. Explain the Replication Architecture in MongoDB.
Answer:
- The replica set cluster architecture has a primary node and two secondary nodes.
- The primary node receives write operations from database clients and saves data changes in the Oplog.
- Oplog entries are sequential and saved in the order they are received and executed.
- The secondary nodes query the primary node for new changes in the Oplog.
- If there are any changes, Oplog entries are copied from primary to secondary as soon as they are created on the primary node.
- The secondary node applies changes from the Oplog to its own datafiles in the same order they were inserted in the log.
- As a result, datafiles on the secondary nodes are kept in sync with changes on the primary node.
- Sometimes a secondary node can replicate data from another secondary node, which is called Chained Replication.
- Chained replication is a two-step process that is useful in certain replication topologies and is enabled by default in MongoDB.
8. How does MongoDB ensure high availability?
Answer: MongoDB uses replication to ensure high availability. This means that multiple copies of data are maintained across multiple servers.
9. What is sharding in MongoDB?
Answer: Sharding is a process of dividing large amounts of data across multiple servers. This allows MongoDB to scale horizontally.
10. Which languages can be used with MongoDB?
Answer: At present, MongoDB offers official driver support for several programming languages, including C, C++, C#, Java, Node.js, Perl, PHP, Python, Ruby, Scala, Go, and Erlang. This means that MongoDB can be readily used with any of these programming languages, as the necessary drivers are officially provided by MongoDB. Although some other community-supported drivers are also available, the drivers mentioned above are all officially supported by MongoDB.
11. What are indexes in MongoDB?
Answer: Indexes are data structures that allow MongoDB to perform queries faster. They are created on fields in a collection.
12. What is aggregation in MongoDB?
Answer: Aggregation is a process of performing analysis on data in MongoDB. It allows for complex data analysis using a pipeline of operations.
13. What is the difference between a collection and a table in MongoDB?
Answer: A collection in MongoDB is similar to a table in SQL databases. However, a collection can have dynamic schema, while a table has a predefined schema.
14. What is the difference between an embedded document and a reference in MongoDB?
Answer: An embedded document is a document that is contained within another document. A reference is a field in a document that references another document.
15. What is the difference between update and save in MongoDB?
Answer: Update is used to modify existing documents in a collection. Save is used to insert new documents or update existing ones.
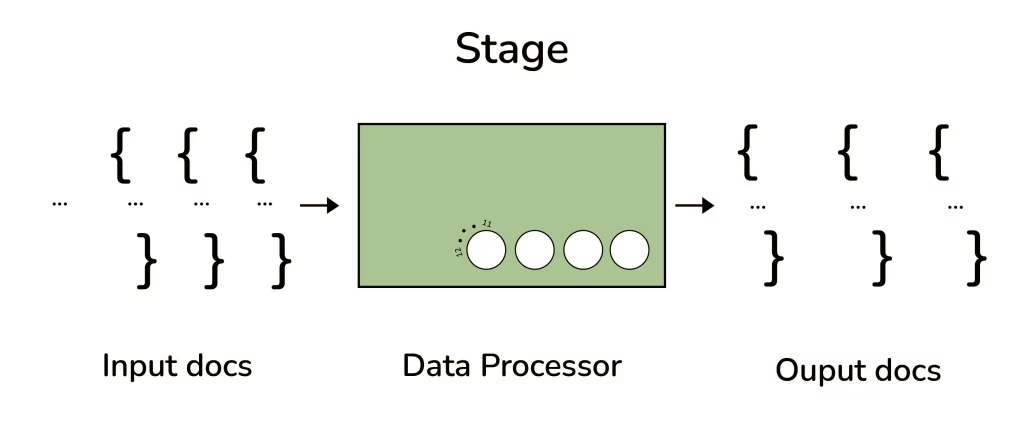
16. Explain the concept of pipeline in the MongoDB aggregation framework.
Answer:
- A stage in the aggregation pipeline is a unit of data processing.
- It receives a stream of input documents one at a time and processes each document individually.
- The output of each stage is also a stream of documents, produced one at a time.
- The entire pipeline is made up of multiple stages, each performing a specific operation on the input documents.
- The output of one stage becomes the input of the next stage in the pipeline.
- This process continues until the final stage produces the output of the entire pipeline.
17. How do you ensure data consistency in MongoDB?
Answer: MongoDB uses a two-phase commit protocol to ensure data consistency. This involves a coordinator node that coordinates transactions across multiple servers.
18. What is MapReduce in MongoDB?
Answer: MapReduce is a process of performing data analysis on large data sets in MongoDB. It allows for parallel processing of data.
19. What is the role of a replica set in MongoDB?
Answer: A replica set is a group of MongoDB servers that maintain multiple copies of data. It is used to ensure high availability and automatic failover.
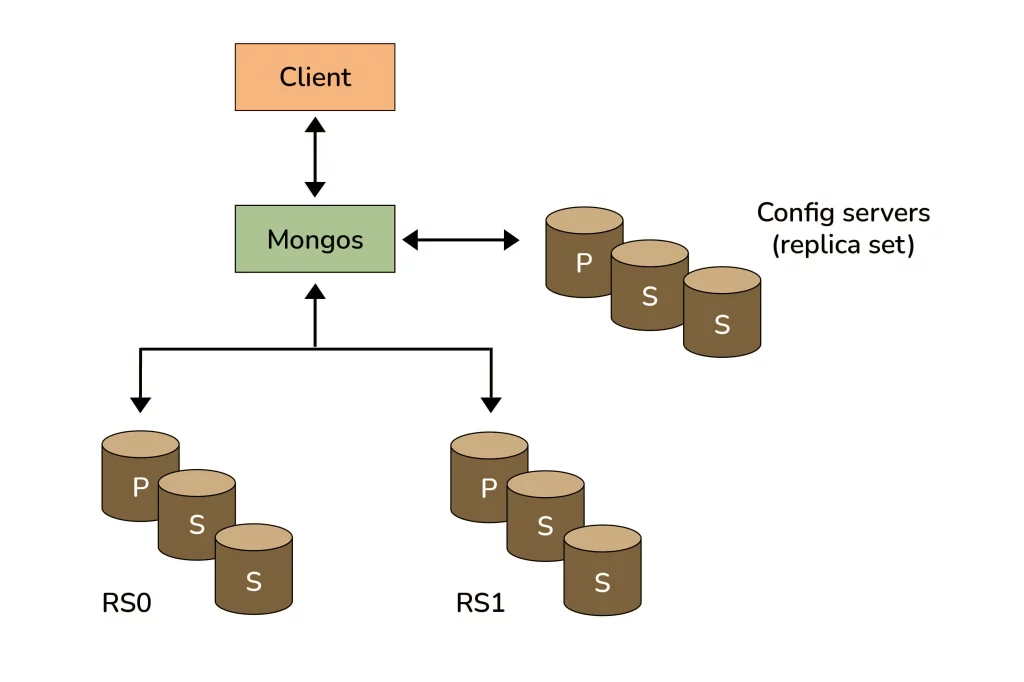
20. Explain the process of Sharding.
- Sharding, also known as partitioning, is the process of distributing data across multiple machines.
- By doing so, we can store more data and handle more load without requiring larger or more powerful machines.
- MongoDB’s sharding feature enables you to create a cluster of many machines, which are called shards.
- A collection can be broken up across these shards, with a subset of data being stored on each shard.
- This allows your application to scale beyond the resource limits of a standalone server or replica set.
- In the figure below, RS0 and RS1 represent shards that hold a subset of data from the collection.
21. What is MongoDB Atlas?
Answer: MongoDB Atlas is a cloud-based database service that provides scalable, secure, and highly available MongoDB instances.
22. How do you perform backups in MongoDB?
Answer: Backups can be performed using the mongodump and mongorestore tools provided by MongoDB.
23. What is the difference between MongoDB and Couchbase?
Answer: Couchbase is a key-value and document-oriented NoSQL database system, while MongoDB is a document-oriented NoSQL database system.
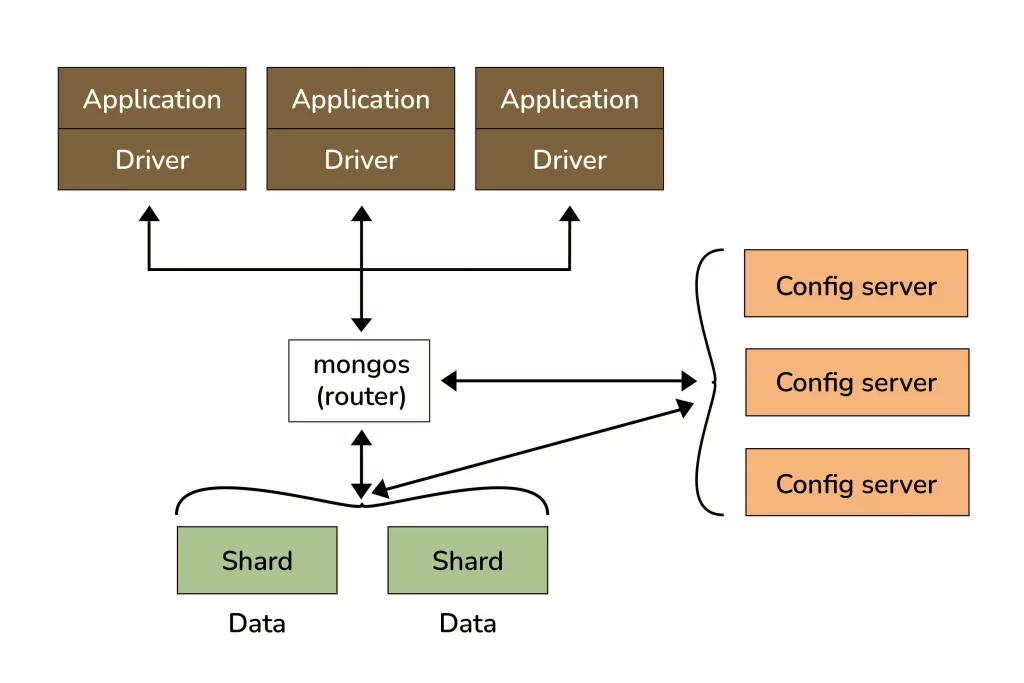
24. How does Scale-Out occur in MongoDB?
- MongoDB’s document-oriented data model makes it simpler to split data across multiple servers.
- Balancing and loading data across a cluster is handled automatically by MongoDB, which also redistributes documents as needed.
- The mongos acts as a query router that connects client applications to the sharded cluster.
- Config servers are responsible for storing metadata and configuration settings for the cluster.
- MongoDB uses the config servers to manage distributed locks, which are necessary for maintaining consistency across the cluster.
- Each sharded cluster requires its own set of config servers.
25. What is the difference between MongoDB and Cassandra?
Answer: Cassandra is a column-family NoSQL database system, while MongoDB is a document-oriented NoSQL database system.
26. How do you install MongoDB?
Answer: MongoDB can be installed on various platforms, such as Windows, Mac, and Linux. The installation process varies depending on the platform, but MongoDB provides detailed instructions on their website.
27. What is the Aggregation Framework in MongoDB?
- The aggregation framework is a collection of analytics tools in MongoDB designed for analyzing documents in one or more collections.
- This framework is built around the concept of a pipeline. In an aggregation pipeline, documents from a MongoDB collection are passed through one or more stages, each of which performs a distinct operation on the inputs (refer to figure below).
- Each stage takes the output produced by the preceding stage as its input, and both inputs and outputs for every stage are documents, which form a stream of documents.
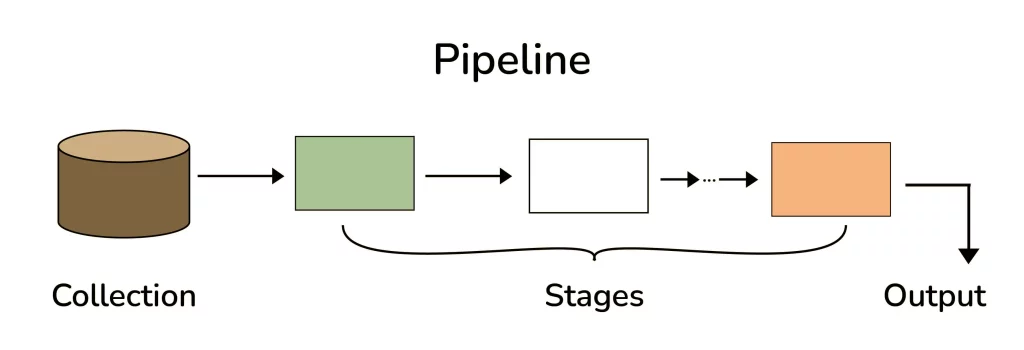
28. What is the difference between a primary and secondary node in a replica set?
Answer: A primary node is the main node in a replica set that handles all writes and reads. A secondary node is a backup node that maintains a copy of data and can take over as the primary node in case of a failure.
29. What is the syntax for inserting a document in MongoDB?
Answer: To insert a document in MongoDB, you use the insertOne() method.
For example:
| db.collection.insertOne({field1: value1, field2: value2}) |
30. How do you update a document in MongoDB?
Answer: To update a document in MongoDB, you use the updateOne() method.
For example:
| db.collection.updateOne({field: value}, {$set: {newField: newValue}}) |
31. What is the syntax for deleting a document in MongoDB?
Answer: To delete a document in MongoDB, you use the deleteOne() method.
For example:
| db.collection.deleteOne({field: value}) |
32. What is the difference between find() and findOne() in MongoDB?
Answer: find() returns a cursor to all documents that match a query, while findOne() returns only the first document that matches a query.
33. What is the $in operator in MongoDB?
Answer: The $in operator in MongoDB allows you to specify an array of values that you want to match against a field.
For example:
| db.collection.find({field: {$in: [value1, value2, value3]}}) |
34. What is the $gt operator in MongoDB?
Answer: The $gt operator in MongoDB allows you to find documents where a field is greater than a specified value.
For example:
| db.collection.find({field: {$gt: value}}) |
35. What is the $lt operator in MongoDB?
Answer: The $lt operator in MongoDB allows you to find documents where a field is less than a specified value.
For example:
| db.collection.find({field: {$lt: value}}) |
36. What is the $and operator in MongoDB?
Answer: The $and operator in MongoDB allows you to specify multiple conditions that must be true for a document to be returned.
For example:
| db.collection.find({$and: [{field1: value1}, {field2: value2}]}) |
37. What is the $or operator in MongoDB?
Answer: The $or operator in MongoDB allows you to specify multiple conditions where at least one condition must be true for a document to be returned.
For example:
| db.collection.find({$or: [{field1: value1}, {field2: value2}]}) |
38. What is a projection in MongoDB?
Answer: A projection in MongoDB is a way to limit the fields that are returned in a query
For example:
| db.collection.find({field: value}, {field1: 1, field2: 1, _id: 0}) |
39. What is an upsert in MongoDB?
Answer: An upsert in MongoDB is a combination of an insert and update operation. If a document does not exist, it is inserted. If it exists, it is updated.
For example:
| db.collection.updateOne({field: value}, {$set: {newField: newValue}}, {upsert: true}) |
40. What is a compound index in MongoDB?
Answer: A compound index in MongoDB is an index that is created on multiple fields in a collection. This can improve query performance when searching on multiple fields.
41. How do you create an index in MongoDB?
Answer: To create an index in MongoDB, you use the createIndex() method.
For example:
| db.collection.createIndex({field1: 1, field2: -1}) |
42. How do you enable sharding in MongoDB?
Answer: To enable sharding in MongoDB, you need to perform the following steps:
- Start a MongoDB instance as a config server
- Start one or more MongoDB instances as shard servers
- Use the mongos tool to connect to the config server and configure the shards
43. What is a shard key in MongoDB?
Answer: A shard key in MongoDB is a field or combination of fields that determine how data is partitioned across shards in a sharded cluster.
44. What is the maximum size of a MongoDB document?
Answer: The maximum size of a MongoDB document is 16 megabytes.
45. What is the maximum size of a MongoDB database?
Answer: The maximum size of a MongoDB database is 32 terabytes.
46. What is a capped collection in MongoDB?
Answer: A capped collection in MongoDB is a collection with a fixed size that automatically overwrites old documents as new documents are inserted.
47. What is the $group stage in the aggregation framework?
Answer: The $group stage in the aggregation framework allows you to group documents by a specified field and perform operations on the grouped data such as summing, averaging, and counting.
48. What is the $match stage in the aggregation framework?
Answer: The $match stage in the aggregation framework allows you to filter documents based on a specified condition.
49. What is the $project stage in the aggregation framework?
Answer: The $project stage in the aggregation framework allows you to reshape the output of a query by specifying which fields to include or exclude.
50. What is the $sort stage in the aggregation framework?
Answer: The $sort stage in the aggregation framework allows you to sort the output of a query based on one or more fields.
51. What is the $lookup stage in the aggregation framework?
Answer: The $lookup stage in the aggregation framework allows you to perform a left outer join between two collections based on a specified condition.
52. What is the $unwind stage in the aggregation framework?
Answer: The $unwind stage in the aggregation framework allows you to break up an array field into multiple documents, one for each element of the array.
53. What is the difference between the $push and $addToSet operators in the aggregation framework?
Answer: The $push operator adds a specified value to an array field, even if the value already exists in the array. The $addToSet operator adds a specified value to an array field only if the value does not already exist in the array.
54. What is a change stream in MongoDB?
Answer: A change stream in MongoDB allows you to monitor changes to a collection in real-time by opening a cursor that receives notifications for each change.
55. How do you create a change stream in MongoDB?
Answer: To create a change stream in MongoDB, you can use the watch() method on a collection.
For example:
| const cursor = db.collection(‘myCollection’).watch() cursor.on(‘change’, (change) => { console.log(change) }) |
56. What is the purpose of the $out operator in the aggregation framework?
Answer: The $out operator in the aggregation framework allows you to write the results of an aggregation pipeline to a new collection.
57. What is a geospatial index in MongoDB?
Answer: A geospatial index in MongoDB is an index that allows you to perform geospatial queries on a collection. It indexes location data in a collection using either point or polygon data.
58. What is a TTL index in MongoDB?
Answer: A TTL (time-to-live) index in MongoDB is an index that automatically removes documents from a collection after a specified amount of time has passed.
59. How do you create a TTL index in MongoDB?
Answer: To create a TTL index in MongoDB, you need to specify the expireAfterSeconds option when creating the index.
For example:
| db.myCollection.createIndex({ createdAt: 1 }, { expireAfterSeconds: 3600 }) |
This creates a TTL index on the createdAt field that removes documents from the collection after one hour.
60. What is the difference between a replica set and a sharded cluster in MongoDB?
Answer: A replica set in MongoDB is a group of MongoDB instances that maintain the same data set for high availability and fault tolerance. A sharded cluster in MongoDB is a group of replica sets that shard data across multiple servers for improved scalability and performance.
61. What is a MongoDB Atlas cluster?
Answer: MongoDB Atlas is a fully managed cloud database service for MongoDB that provides automatic scaling, backup, and recovery.
62. How do you connect to a MongoDB Atlas cluster?
Answer: To connect to a MongoDB Atlas cluster, you need to provide your connection string in your MongoDB client. You can find your connection string in the MongoDB Atlas dashboard.
For example:
| mongodb+srv://<username>:<password>@<cluster>.mongodb.net/<database> |
Replace <username> and <password> with your MongoDB Atlas credentials, <cluster> with the name of your cluster, and <database> with the name of your database.
63. What is the difference between a primary and secondary node in a MongoDB replica set?
Answer: In a MongoDB replica set, the primary node receives all write operations, while secondary nodes replicate the data from the primary node and are available for read operations. If the primary node fails, one of the secondary nodes is automatically elected as the new primary.
64. How do you add a new node to a MongoDB replica set?
Answer: To add a new node to a MongoDB replica set, you can use the rs.add() method on an existing node.
For example:
| rs.add(‘newNode.example.com’) |
Replace ‘newNode.example.com’ with the hostname or IP address of the new node.
65. What is the oplog in MongoDB?
Answer: The oplog (short for operation log) in MongoDB is a special collection that records all write operations that are performed on a MongoDB instance. It allows MongoDB to replicate data between nodes in a replica set and to recover from failures.
66. How do you optimize a MongoDB query?
Answer: To optimize a MongoDB query, you can use techniques such as creating indexes on frequently queried fields, using the explain() method to analyze query performance, and using the $lookup operator to avoid multiple queries.
67. What is the difference between a sparse index and a dense index in MongoDB?
Answer: A sparse index in MongoDB only indexes documents that have a non-null value for the indexed field. A dense index indexes all documents, regardless of whether they have a null value for the indexed field.
68. How do you back up a MongoDB database?
Answer: To back up a MongoDB database, you can use the mongodump command-line tool.
For example:
| mongodump –host myHost –port 27017 –db myDatabase –out /my/backup/directory/ |
69. What is the difference between a hot backup and a cold backup in MongoDB
Answer: A hot backup of a MongoDB database is taken while the database is running, while a cold backup is taken while the database is offline. A hot backup is typically faster and less disruptive, but may not be as consistent as a cold backup.
70. What is the MongoDB Connector for BI?
Answer: The MongoDB Connector for BI is a tool that allows you to use MongoDB as a data source for popular business intelligence tools such as Tableau and Power BI.
71. How do you use the MongoDB Connector for BI with a tool like Tableau or Power BI?
Answer: To use the MongoDB Connector for BI with a tool like Tableau or Power BI, you need to install the appropriate connector and configure it with your MongoDB connection string. Once the connector is installed and configured, you can use it to query MongoDB data in your business intelligence tool.
72. What is the difference between a single-threaded and multi-threaded MongoDB server?
Answer: A single-threaded MongoDB server can only process one request at a time, while a multi-threaded server can process multiple requests simultaneously. Multi-threading can improve performance for high-traffic applications, but may also require more system resources.
73. How do you secure a MongoDB instance?
Answer: To secure a MongoDB instance, you can use techniques such as enabling authentication, restricting network access to the instance, enabling encryption in transit and at rest, and following best practices for password and user management.
74. What is the role of the MongoDB Compass tool?
Answer: MongoDB Compass is a graphical user interface for MongoDB that allows you to view and interact with your data, manage your databases and collections, and create and run queries.
75. What is the aggregation framework in MongoDB?
Answer: The aggregation framework in MongoDB is a set of operators that allow you to perform complex queries and transformations on your data. It includes operators for grouping, filtering, sorting, projecting, and more.
76. What is the difference between an embedded document and a referenced document in MongoDB?
Answer: An embedded document is a document that is nested within another document, while a referenced document is a separate document that is referenced by another document through a foreign key or other identifier. Embedded documents can be more efficient for read-heavy workloads, while referenced documents can be more flexible for write-heavy workloads.
77. How do you set up sharding in MongoDB?
Answer: To set up sharding in MongoDB, you need to create a sharded cluster consisting of one or more shard nodes, one or more mongos routers, and one or more config servers. You can then enable sharding on one or more databases or collections by specifying a shard key and distributing the data across multiple shards.
78. What is the role of the config server in a sharded MongoDB cluster?
Answer: The config server in a sharded MongoDB cluster stores metadata about the distribution of data across shards. It allows mongos routers to route queries to the appropriate shard and to rebalance data when necessary.
79. What is the difference between a replica set and a sharded cluster in MongoDB?
Answer: A replica set in MongoDB is a set of one or more nodes that replicate data to provide high availability and fault tolerance. A sharded cluster is a set of nodes that distribute data across multiple shards for scalability and performance.
80. How do you use the $text operator in MongoDB?
Answer: The $text operator in MongoDB allows you to perform full-text search queries on text fields. To use the $text operator, you need to create a text index on one or more fields using the createIndex() method with the ‘text’ option.
81. What is the difference between a join and a $lookup in MongoDB?
Answer: A join in MongoDB is a manual process of combining data from multiple collections using application logic. A $lookup in MongoDB is an aggregation pipeline stage that allows you to perform a left outer join between two collections. $lookup is more flexible and can handle more complex joins than a manual join.
82. What is the difference between a capped collection and a regular collection in MongoDB?
Answer: A capped collection in MongoDB is a fixed-size collection that automatically overwrites the oldest documents when the collection reaches its maximum size. A regular collection is an unbounded collection that stores documents without any size or document count limits. Capped collections can be useful for storing log data or other time-series data where old data can be discarded after a certain period of time.
83. How do you create a capped collection in MongoDB?
Answer: To create a capped collection in MongoDB, you can use the createCollection() method with the ‘capped’ option set to true, along with the ‘size’ and/or ‘max’ options to specify the maximum size and number of documents in the collection.
For example:
| db.createCollection(“myCappedCollection”, { capped: true, size: 100000, max: 1000 } ) |
This creates a capped collection named ‘myCappedCollection’ with a maximum size of 100,000 bytes and a maximum of 1,000 documents.
84. What is a covered query in MongoDB?
Answer: A covered query in MongoDB is a query that can be fully satisfied by using only the index without having to fetch any documents from the collection. This can be more efficient than queries that require fetching documents from disk, especially for large collections.
85. How do you perform a covered query in MongoDB?
Answer: To perform a covered query in MongoDB, you need to create an index that covers all the fields in the query. You can then use the explain() method to verify that the query is covered.
For example:
| db.myCollection.createIndex( { name: 1, age: 1 } ) db.myCollection.find( { name: “John”, age: { $gt: 30 } }, { _id: 0, name: 1, age: 1 } ).explain(“executionStats”) |
This creates an index on the ‘name’ and ‘age’ fields of the ‘myCollection’ collection and performs a covered query to find all documents where the name is “John” and the age is greater than 30, returning only the name and age fields.
86. What is the role of the WiredTiger storage engine in MongoDB?
Answer: The WiredTiger storage engine is the default storage engine in MongoDB 3.2 and later versions. It provides features such as document-level concurrency control, compression, and encryption, as well as improved performance for write-heavy workloads.
87. What is the difference between the MMAPv1 and WiredTiger storage engines in MongoDB?
Answer: The MMAPv1 storage engine in MongoDB is an older storage engine that uses memory-mapped files to store data. The WiredTiger storage engine is a newer storage engine that uses a more advanced storage architecture optimized for modern hardware. WiredTiger offers better compression, more efficient write operations, and improved concurrency control compared to MMAPv1.
88. How do you choose a storage engine in MongoDB?
Answer: You can choose a storage engine in MongoDB by specifying the ‘storageEngine’ option when creating a new replica set or shard. You can also change the storage engine for an existing MongoDB deployment by performing a rolling upgrade to a version that supports the desired storage engine.
89. How do you use the $lookup stage in an aggregation pipeline in MongoDB?
Answer: To use the $lookup stage in an aggregation pipeline in MongoDB, you need to specify the name of the collection to join with, the local field that corresponds to the foreign key, the foreign field that corresponds to the local key, and any optional pipeline stages to apply to the joined collection.
For example:
| db.orders.aggregate([ { $lookup: { from: “products”, localField: “productId”, foreignField: “_id”, as: “product” } } ]) |
This performs a left outer join between the ‘orders collection and the ‘products’ collection based on the ‘productId’ field, and stores the joined documents in an array called ‘product’.
90. How do you perform text search in MongoDB?
Answer: To perform text search in MongoDB, you can use the $text operator in a query, along with an index on the fields to be searched.
For example:
| db.myCollection.createIndex( { name: “text”, description: “text” } ) db.myCollection.find( { $text: { $search: “coffee” } } ) This creates a text index on the ‘name’ and ‘description’ fields of the ‘myCollection’ collection, and performs a text search for the term ‘coffee’. |
91. What is the difference between a sharded cluster and a replica set in MongoDB?
Answer: A replica set in MongoDB is a group of MongoDB servers that maintain the same data set, providing redundancy and high availability. A sharded cluster, on the other hand, is a group of replica sets that partition data across multiple servers, allowing for horizontal scalability and improved performance.
92. How do you create a sharded cluster in MongoDB?
Answer: To create a sharded cluster in MongoDB, you need to set up a configuration server, one or more shards (each containing a replica set), and one or more mongos routers to route client requests to the appropriate shards. You can use the mongod and mongos commands to start the necessary processes.
93. How do you add a shard to a sharded cluster in MongoDB?
Answer: To add a shard to a sharded cluster in MongoDB, you need to start a new replica set, and then use the sh.addShard() method to add the replica set as a shard.
This adds a new shard consisting of the replica set named ‘rs1’ with members at the specified hostnames and ports.
94. How do you balance data across shards in a sharded cluster in MongoDB?
Answer: To balance data across shards in a sharded cluster in MongoDB, you can use the sh.enableSharding() method to enable sharding for a database, and then use the sh.shardCollection() method to shard a collection based on a shard key. The cluster will automatically balance data across the available shards based on the shard key values.
95. How do you back up data in MongoDB?
Answer: To back up data in MongoDB, you can use the mongodump command to create a binary dump of the data in a specified database or collection. You can then use the mongorestore command to restore the dump to a new instance of MongoDB. Alternatively, you can use a cloud-based MongoDB service that provides automatic backups.
96. How do you secure MongoDB?
Answer: To secure MongoDB, you can use features such as authentication, authorization, encryption, and network security. You can enable authentication by creating user accounts and passwords, and enabling access control. You can use TLS/SSL encryption to secure network communication, and use file system or database-level encryption to protect data at rest.
97. How do you enable authentication in MongoDB?
Answer: To enable authentication in MongoDB, you need to start the mongod or mongos process with the –auth option, and then create user accounts with the necessary roles using the db.createUser() method.
For example:
| mongod –auth –port 27017 –dbpath /data/db db.createUser( { user: “myUser”, pwd: “myPassword”, roles: [ { role: “readWrite”, db: “myDatabase” } ] } ) |
This starts the mongod process with authentication enabled on port 27017 and data stored in /data/db, and creates a user account named ‘myUser’ with the password ‘myPassword’ and read/write access to the ‘myDatabase’ database.
98. How do you grant roles to user accounts in MongoDB?
Answer: To grant roles to user accounts in MongoDB, you can use the db.grantRolesToUser() method.
For example:
| db.grantRolesToUser( “myUser”, [ { role: “readWrite”, db: “myDatabase” }, { role: “dbAdmin”, db: “myDatabase” } ] ) |
This grants the ‘myUser’ account read/write access and the ‘dbAdmin’ role for the ‘myDatabase’ database.
99. How do you create an index in MongoDB?
Answer: To create an index in MongoDB, you can use the createIndex() method on a collection object.
For example:
| db.myCollection.createIndex( { name: 1 } ) |
This creates an ascending index on the ‘name’ field of the ‘myCollection’ collection.
100. How do you drop an index in MongoDB?
Answer: To drop an index in MongoDB, you can use the dropIndex() method on a collection object.
For example:
| db.myCollection.dropIndex( { name: 1 } ) |
This drops the index on the ‘name’ field of the ‘myCollection’ collection.
A comprehensive list of the top 100 MongoDB interview questions and answers covers the latest technical questions and those suitable for freshers, helping you prepare for your next interview. Please follow us at freshersnow.com to expand your knowledge.