
| Join Telegram |  |
| Join Whatsapp Groups |  |
Apache Spark is a fast, open-source computation technology built on Hadoop and MapReduce. It supports various techniques for efficient processing and is known for its in-memory cluster computation. Developed by Matei Zaharia at UC Berkeley in 2009, Spark became a top-level Apache project in 2014. We have put together a comprehensive list of the Top 100 Spark Interview Questions and Answers to assist you in preparing for your upcoming Spark Technical Interview Questions.
★★ Latest Technical Interview Questions ★★
Spark Technical Interview Questions
If you’re preparing for a Spark interview, this list of Top 100 Spark Interview Questions and Answers covers both beginner and advanced topics. Whether Spark Interview Questions for Freshers or an experienced developer, these interview questions will help you excel. From the Latest Spark Interview Questions developments, this resource has covered.
Top 100 Spark Interview Questions and Answers
1. What is Apache Spark and how does it differ from Hadoop?
Apache Spark is an open-source distributed computing system designed for big data processing and analytics. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Unlike Hadoop, which primarily focuses on batch processing, Spark supports both batch processing and real-time stream processing, making it more versatile.
2. Explain the concept of RDD (Resilient Distributed Dataset) in Spark.
RDD (Resilient Distributed Dataset) is a fundamental data structure in Spark. It represents an immutable distributed collection of objects that can be processed in parallel. RDDs are fault-tolerant and can be stored in memory, which allows for faster data processing. They are the building blocks of Spark computations and provide the ability to recover lost data partitions.
3. What do you understand by Shuffling in Spark?
Shuffling or repartitioning is the process of redistributing data across different partitions, which may involve moving data across JVM processes or executors on separate machines. A partition represents a smaller logical division of data. During shuffling, Spark rearranges the data to ensure that related data elements are grouped together in the desired partitions, enabling efficient parallel processing and subsequent operations on the data.
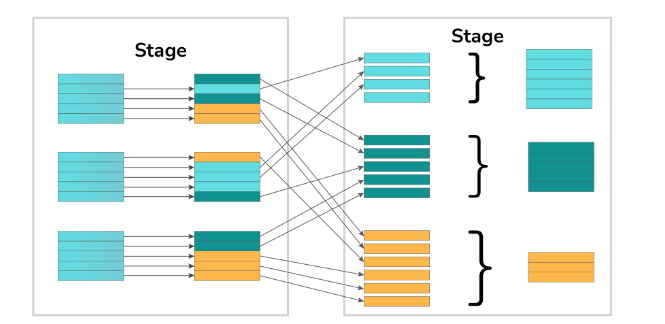
4. What are the different transformations and actions in Spark?
Spark provides two types of operations on RDDs: transformations and actions. Transformations are operations that produce a new RDD from an existing one, such as map, filter, and join. They are lazy evaluations, meaning the execution is deferred until an action is called. Actions, on the other hand, return a value or write data to an external storage system, triggering the execution of transformations. Examples of actions include counting, collecting, and saving.
5. How does Spark handle data skewness in aggregations?
Spark provides various strategies to handle data skewness in aggregations. One common approach is called “skew join” or “skew handling”. In this approach, Spark identifies the skewed partitions based on the size of the data in each partition. It then performs an additional step to redistribute the data within the skewed partitions, effectively balancing the load. This can be done by splitting the skewed partition into multiple smaller partitions or by replicating the data in the skewed partition across multiple nodes. By doing so, the workload is evenly distributed across the cluster, mitigating the impact of data skewness.
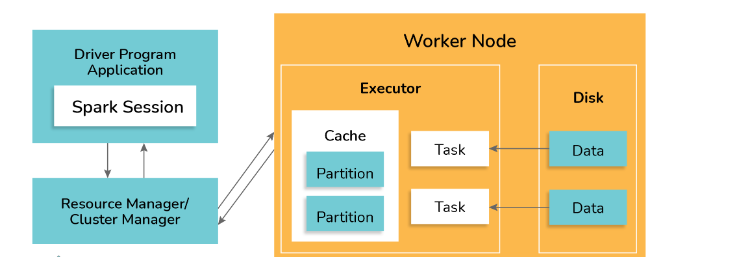
6. Explain the working of Spark with the help of its architecture.
Spark applications operate as independent processes coordinated by the Driver program through a SparkSession object. The cluster manager or resource manager in Spark assigns tasks for executing Spark jobs to worker nodes, following the principle of one task per partition. Iterative algorithms are often used in Spark, where datasets are cached across iterations. Each task applies its set of operations to the dataset within its partition, generating a new partitioned dataset. The results are then sent back to the main driver application for further processing or storage.
7. Difference between batch processing and real-time processing in Apache Spark
| Batch Processing | Real-time Processing |
|---|---|
| Processes data in fixed batches | Processes data in near real-time |
| Suitable for processing large | Suitable for processing streaming |
| volumes of data | data in real-time |
| Typically used for offline | Typically used for online |
| analytics and data transformations | analytics and continuous processing |
| Examples: ETL jobs, | Examples: Real-time monitoring, |
| batch aggregations | fraud detection |
8. What is the working of DAG in Spark?
A DAG (Directed Acyclic Graph) represents a logical execution plan in Apache Spark. It consists of vertices representing RDDs and edges representing sequential operations on RDDs. The DAG is submitted to the DAG Scheduler, which splits it into stages of tasks based on data transformations. The stage view provides details about the RDDs in each stage.
The working of DAG in spark is defined as per the workflow diagram below:
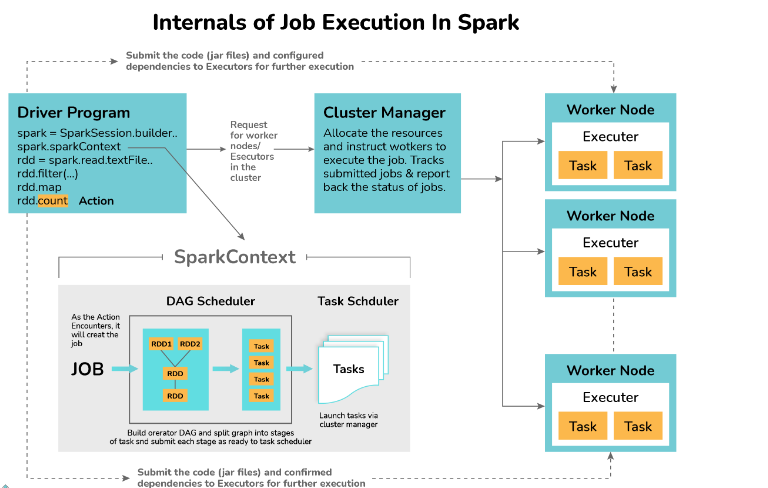
- Code is interpreted by the Scala interpreter (if using Scala) or an appropriate interpreter for the chosen programming language.
- Spark creates an operator graph based on the entered code.
- When an action is called on a Spark RDD, the operator graph is submitted to the DAG Scheduler.
- The DAG Scheduler divides the operators into stages of tasks.
- Each stage represents a sequence of step-by-step operations on the input data, and the operators within a stage are pipelined together.
- The stages are then passed to the Task Scheduler.
- The Task Scheduler launches the tasks independently on worker nodes via the cluster manager.
- The worker nodes execute the tasks without dependencies between stages.
9. Explain the concept of Spark’s broadcast joins
.Broadcast join is a technique used in Spark to optimize join operations between small and large datasets. In a broadcast join, the smaller dataset is broadcasted to all the worker nodes in the cluster, eliminating the need for shuffling or data movement. This is possible because the smaller dataset can fit entirely in memory on each node. By broadcasting the smaller dataset, Spark avoids the costly network transfer and leverages the memory of each worker node for faster join processing. It improves performance by reducing the data movement and network overhead associated with traditional joint operations.
10. What is the role of a Catalyst optimizer in Spark?
Catalyst is Spark’s query optimizer and execution engine. It plays a crucial role in transforming and optimizing the user’s high-level query expressions into an optimized execution plan. Catalyst performs a series of optimization techniques such as predicate pushdown, column pruning, join reordering, and expression simplification. It also applies advanced optimizations like predicate pushdown through joins, constant folding, and code generation to improve query performance. Catalyst uses an extensible rule-based framework to apply these optimizations and generate an efficient execution plan for the given query.
11. How does Spark handle dynamic resource allocation?
Spark supports dynamic resource allocation to efficiently manage cluster resources based on the workload. It utilizes a feature called Dynamic Resource Allocation (DRA) to automatically adjust the number of executor instances based on the workload. When enabled, Spark’s DRA continuously monitors the resource usage of the application and adds or removes executor instances as needed. This helps in maximizing resource utilization and reducing resource wastage. By dynamically allocating resources, Spark can adapt to varying workloads and optimize cluster utilization.
12. What module is used for implementing SQL in Apache Spark?
Spark SQL is a powerful module in Apache Spark that combines relational data processing with the functional programming capabilities of Spark. It supports both SQL and Hive Query Language for data processing. The module consists of four major libraries: Data Source API, DataFrame API, Interpreter & Catalyst Optimizer, and SQL Services.
Spark SQL provides several features and benefits for working with structured and semi-structured data:
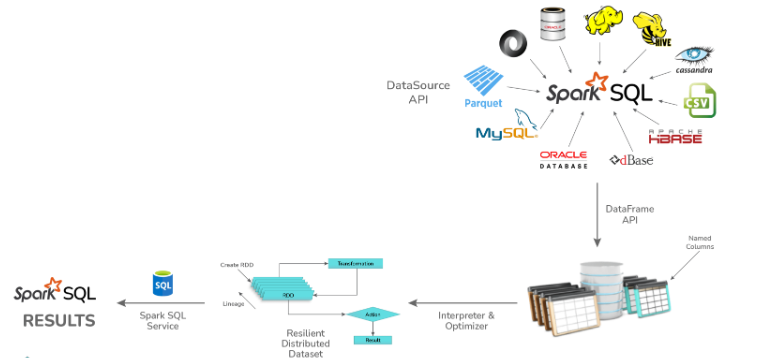
- DataFrame abstraction: Spark supports the DataFrame abstraction in Python, Scala, and Java, providing efficient optimization techniques for data processing.
- Data source support: SparkSQL allows reading and writing data in various structured formats such as JSON, Hive, Parquet, and more.
- Querying capabilities: SparkSQL enables data querying within Spark programs and through external tools via JDBC/ODBC connections.
- Integration with Spark applications: It is recommended to use SparkSQL within Spark applications, as it allows developers to easily load data, query databases, and write results to desired destinations.
13. Explain the concept of Spark’s block manager.
Spark’s block manager is a component responsible for managing data blocks in memory and on disk across the cluster. It plays a vital role in caching and efficient data storage for RDDs (Resilient Distributed Datasets) and data frames. The block manager stores the data blocks in a serialized form and keeps track of their location and status. It manages the movement of data blocks between memory and disk, as well as data replication for fault tolerance. The block manager also facilitates data sharing among tasks within the same executor, promoting data locality and reducing network overhead.
14. Difference between Spark Streaming and Spark Structured Streaming
| Spark Streaming | Spark Structured Streaming |
|---|---|
| Micro-batch processing model | Continuous processing model |
| Processes data in small time windows | Processes data as a continuous stream |
| Uses discretized streams (DStreams) | Uses DataFrames and Datasets |
| No fault-tolerance guarantees | End-to-end fault-tolerance guarantees |
| Limited support for structured data | Native support for structured data |
| Limited integration with Spark SQL | Tight integration with Spark SQL |
15. What are the different deployment modes of Spark on YARN?
When deploying Spark on YARN (Yet Another Resource Negotiator), you can choose from three different deployment modes:
- Client Mode: In this mode, the Spark driver runs on the client machine that initiates the Spark application. The client is responsible for communicating with the cluster’s Resource Manager and application master.
- Cluster Mode: In cluster mode, the Spark driver runs within a YARN container. The driver is launched and managed by the ApplicationMaster, which is responsible for resource negotiation and task scheduling.
- Cluster Mode with Client Interaction: This mode is similar to cluster mode, but it allows the Spark driver to interact with the client machine. The client can monitor the application, view logs, and interact with the running Spark application.
16. How does Spark handle data caching and persistence?
Spark provides data caching and persistence capabilities to optimize performance. It allows users to persist RDDs or DataFrames in memory or on disk, reducing the need to recompute them. Caching is useful when multiple actions need to be performed on the same dataset. Spark automatically manages the data eviction from memory based on memory usage and storage level settings.
17. Difference between RDDs and DataFrames in Spark
| RDDs (Resilient Distributed Datasets) | DataFrames |
|---|---|
| Low-level distributed data structure | High-level distributed data structure |
| Provides a fault-tolerant collection | Provides a distributed collection |
| Supports only unstructured data | Supports structured and semi- |
| structured data | |
| Offers limited optimizations | Offers advanced optimizations |
| No built-in schema enforcement | Enforces schema and data integrity |
| More suitable for complex computations | More suitable for SQL-like operations |
18. What is the significance of Spark’s in-memory computation?
Spark’s in-memory computation is significant because it enables faster data processing compared to traditional disk-based processing models like MapReduce. By keeping the data in memory, Spark minimizes disk I/O operations, which are typically slower than in-memory operations. This improves the overall performance and speed of data processing.
19. Difference between Spark SQL and Hive
| Spark SQL | Hive |
|---|---|
| Part of the Apache Spark ecosystem | Part of the Apache Hadoop ecosystem |
| Provides SQL and DataFrame APIs | Provides SQL-like HiveQL and HCatalog |
| Optimized for in-memory processing | Primarily works with disk-based storage |
| Supports both batch and real-time | Primarily used for batch processing |
| processing | |
| Offers better performance | May suffer from latency issues due to |
| disk I/O | |
| Supports various data sources | Focuses on Hadoop-based data sources |
20. How does Spark utilize parallel processing to improve performance?
Spark utilizes parallel processing to improve performance by dividing data and computations across multiple worker nodes in a cluster. It leverages the concept of data partitioning, where data is divided into smaller partitions that can be processed independently. Spark performs operations in parallel on these partitions, allowing for distributed and efficient processing. Additionally, Spark optimizes data locality by scheduling tasks on nodes where data is already stored, minimizing network transfer overhead.
21. Describe the Spark execution model.
The Spark execution model is based on directed acyclic graphs (DAGs). It consists of a sequence of transformations and actions applied to RDDs, forming a logical execution plan. When an action is triggered, Spark optimizes the plan and schedules tasks to be executed on worker nodes. The execution is pipelined, meaning the output of one stage becomes the input of the next stage without unnecessary data shuffling.
22. What are the advantages of using Spark over traditional MapReduce?
Spark offers several advantages over traditional MapReduce:
- Faster processing: Spark performs computations in memory, which significantly speeds up data processing compared to disk-based processing in MapReduce.
- Versatility: Spark supports batch processing, real-time stream processing, machine learning, and graph processing, while MapReduce primarily focuses on batch processing.
- Interactive data analysis: Spark allows for interactive and iterative data analysis by caching intermediate results in memory, reducing the need for disk I/O.
- Rich API: Spark provides a comprehensive set of high-level APIs in multiple programming languages like Scala, Python, and Java, making it more developer-friendly compared to MapReduce.
23. Difference between map() and flatMap() transformations in Spark
| map() transformation | flatMap() transformation |
|---|---|
| Transforms each input element into | Transforms each input element into |
| a single output element | Zero or more output elements |
| Produces a one-to-one mapping | Produces a one-to-many mapping |
| Retains the original structure of the RDD | Flattens the output by removing |
| any intermediate layers | |
| Useful for simple transformations and | Useful for transformations that require |
| aggregations | exploding or splitting elements |
24. Explain the syntax for creating a Spark DataFrame from a CSV file in Python
To create a data frame from a CSV file in Python, you can use the following syntax:
python df = spark.read.csv("file.csv", header=True, inferSchema=True)
25. What is the syntax to filter rows in a Spark DataFrame based on a specific condition in Scala?
To filter rows in a Spark DataFrame using a condition in Scala, you can use the filter method with the following syntax:
scala val filteredDF = df.filter(df("column_name") > 10)
26. How does Spark handle data partitioning?
Spark handles data partitioning by breaking the dataset into multiple partitions, which are distributed across the nodes in a cluster. Each partition contains a subset of the data, and Spark processes these partitions in parallel across the cluster. Spark provides various partitioning strategies, such as hash partitioning and range partitioning, to determine how data is divided among partitions.
27. Difference between MLlib and ML packages in Apache Spark
| MLlib (Machine Learning Library) | ML (Machine Learning) |
|---|---|
| Original machine learning library in | A newer machine learning library introduced |
| Spark, now in maintenance mode | in Spark, recommended for new projects |
| Provides RDD-based APIs | Provides DataFrame-based APIs |
| Offers a wider range of algorithms | Focuses on simplified, streamlined API |
| Supports both batch and real-time | Primarily designed for batch processing |
| processing |
28. What is lazy evaluation in Spark?
Lazy evaluation in Spark refers to the strategy of postponing the execution of transformations on a dataset until an action is triggered. Instead of immediately executing the transformations, Spark builds a logical execution plan called a lineage graph. This allows Spark to optimize and combine multiple transformations before actually executing them, resulting in efficient query execution.
29. Explain the concept of lineage in Spark.
Lineage in Spark refers to the logical execution plan that captures the dependencies between RDDs (Resilient Distributed Datasets) or DataFrames. It represents the sequence of transformations applied to create a particular RDD or data frame from its source data. Lineage information enables Spark to recover lost data by recomputing the lost partitions based on the available lineage information, making the data processing pipeline fault-tolerant.
30. How does Spark optimize query execution?
Spark optimizes query execution through various techniques such as predicate pushdown, column pruning, and cost-based optimization. It leverages Catalyst, the built-in query optimizer, to analyze and optimize the logical and physical execution plans. Catalyst performs operations like predicate pushdown (pushing filters close to the data source), expression evaluation, and reordering of operations to minimize data shuffling and improve performance.
31. Difference between Spark’s local mode and cluster mode
| Local Mode | Cluster Mode |
|---|---|
| Runs Spark on a single machine | Runs Spark on a cluster of machines |
| Suitable for local development, testing, | Suitable for production deployments |
| and small-scale data processing | and large-scale data processing |
| Utilizes the resources of a single | Utilizes the resources of multiple |
| machine | machines |
| No distributed coordination required | Requires coordination among cluster nodes |
| Limited scalability | Offers high scalability and fault tolerance |
| No external resource manager required | Requires an external resource manager |
32. What is the significance of Spark SQL?
Spark SQL is a module in Spark that provides a programming interface for querying structured and semi-structured data using SQL, HiveQL, or DataFrame API. It allows seamless integration of SQL queries with Spark’s distributed computing capabilities, enabling users to process structured data alongside unstructured data. Spark SQL also provides optimizations and performance improvements, making it a powerful tool for data exploration and analysis.
33. Provide the syntax to perform a groupBy operation on a Spark DataFrame in SQL.
To perform a groupBy operation on a Spark DataFrame using SQL syntax, you can use the following syntax:
sql SELECT column1, aggregate_function(column2) FROM table_name GROUP BY column1
34. How does Spark handle data serialization?
Spark handles data serialization by using Java’s default serialization mechanism or by using the more efficient and customizable Kryo serialization library. When data needs to be sent over the network or stored in memory, Spark serializes the objects into a compact binary format. This serialization process allows Spark to efficiently transmit data between nodes in a cluster and perform various operations on the data.
35. What is the role of SparkContext in Spark?
SparkContext is the entry point and the main interface between a Spark application and the Spark cluster. It represents the connection to a Spark cluster and serves as a handle for creating RDDs (Resilient Distributed Datasets) and performing operations on them. SparkContext is responsible for coordinating the execution of tasks, managing the cluster resources, and handling the communication between the application and the cluster.
36. Difference between GraphX and GraphFrames libraries in Spark
| GraphX Library | GraphFrames Library |
|---|---|
| Graph processing library in Spark | Graph processing library in Spark |
| Based on RDDs | Based on DataFrames and Datasets |
| Provides lower-level APIs for building | Offers higher-level APIs for building and |
| and manipulating graphs | manipulating graphs |
| Supports parallel graph computation | Supports parallel graph computation |
| Limited support for structured data | Native support for structured data |
37. Explain the concept of broadcast variables in Spark.
Broadcast variables are read-only variables that are cached on each worker node in a Spark cluster, rather than being sent over the network with each task. They are used to efficiently share large read-only data structures across all the nodes in a cluster. By broadcasting the variables, Spark avoids sending the data multiple times and reduces the overhead of network communication.
38. How does Spark handle memory management?
Spark manages memory using a combination of storage memory and execution memory. Storage memory is used to cache data that is expected to be reused across multiple stages of a Spark application. Execution memory is used to store data structures and intermediate results during the execution of tasks. Spark employs a unified memory management system that dynamically allocates and shares memory between these two regions based on the workload and user configuration.
39. What are the different cluster deployment modes in Spark?
Spark supports various cluster deployment modes, including:
- Local mode: Spark runs on a single machine with a single JVM (Java Virtual Machine).
- Standalone mode: Spark runs on a cluster of machines managed by a standalone Spark cluster manager.
- Apache Mesos: Spark runs on a Mesos cluster, which provides resource isolation and sharing across applications.
- Hadoop YARN: Spark runs on a Hadoop YARN cluster, leveraging YARN’s resource management capabilities.
- Kubernetes: Spark runs on a Kubernetes cluster, using Kubernetes as the cluster manager.
40. How does Spark integrate with other big data tools and frameworks?
Spark provides integration with various big data tools and frameworks through its ecosystem and APIs. Some notable integrations include:
- Hadoop: Spark can read and process data from Hadoop Distributed File System (HDFS) and interact with Hadoop components such as Hive, HBase, and Pig.
- Apache Kafka: Spark can consume data from Apache Kafka, a distributed streaming platform, and perform real-time processing on the streaming data.
- Apache Cassandra: Spark can read and write data from/to Apache Cassandra, a highly scalable and distributed NoSQL database.
- Apache Hive: Spark can query and process data stored in Hive tables using Hive’s query language (HiveQL).
- Machine Learning Frameworks: Spark provides integration with popular machine learning frameworks like TensorFlow and sci-kit-learn to perform distributed machine learning tasks.
41. Difference between RDD-based and DataFrame-based APIs in Spark
| RDD-based APIs | DataFrame-based APIs |
|---|---|
| Provides a low-level API for distributed | Provides a high-level API for distributed |
| data processing and transformations | data processing and transformations |
| Supports unstructured and semi-structured | Supports structured and semi-structured |
| data | data |
| Offers more control and flexibility | Offers optimizations and query optimization |
| May require an explicit schema definition | Enforces schema and data integrity |
42. What is the purpose of Spark’s accumulator variables?
Spark’s accumulator variables are used for aggregating values across multiple tasks in a distributed computation. They are read-only variables that can only be added to, typically used for tasks such as counting or summing elements. Accumulator variables are automatically shared across all the nodes in a cluster and can be efficiently updated in a distributed manner without requiring explicit data shuffling.
43. How do you specify the number of partitions when reading a file in Spark using the DataFrame API?
To specify the number of partitions when reading a file in Spark using the DataFrame API, you can use the coalesce method with the following syntax:
scala val df = spark.read.csv("file.csv").coalesce(numPartitions)
44. Explain the syntax for performing a join operation between two Spark DataFrames in Python.
To perform a join operation between two Spark DataFrames in Python, you can use the join method with the following syntax:
python joinedDF = df1.join(df2, df1.column_name == df2.column_name, "join_type")
45. Explain the difference between DataFrame and RDD in Spark.
DataFrame and RDD (Resilient Distributed Dataset) are two fundamental abstractions in Spark:
- RDD represents an immutable distributed collection of objects, partitioned across multiple nodes. It offers low-level transformations and actions and requires manual schema management and explicit coding for optimization.
- DataFrame is a distributed collection of data organized into named columns. It provides a higher-level API with optimizations through Catalyst’s query optimizer. DataFrames support a rich set of built-in functions and offer seamless integration with Spark SQL, enabling SQL-like queries and efficient data processing.
46. How does Spark Streaming work?
Spark Streaming enables real-time processing of live data streams. It breaks the input data stream into small batches and processes each batch as an RDD or data frame. It uses a micro-batching approach, where each batch is treated as a mini-batch and processed using Spark’s standard batch processing techniques. This allows Spark Streaming to leverage the fault-tolerance and scalability of Spark while achieving near-real-time processing of streaming data.
47. What are the key components of Spark MLlib?
Spark MLlib, the machine learning library in Spark, consists of the following key components:
- Transformers: These are algorithms or processes that transform one data frame into another, such as feature extraction or normalization.
- Estimators: These are algorithms that can be fit on a data frame to produce a model.
- Pipelines: Pipelines allow the chaining and organization of multiple Transformers and Estimators into a single workflow.
48. What is the syntax to sort a Spark DataFrame in descending order based on a specific column in Scala?
To sort a Spark DataFrame in descending order based on a specific column in Scala, you can use the sort method with the following syntax:
scala val sortedDF = df.sort(df("column_name").desc)
49. Explain the concept of a Spark driver program.
The Spark driver program is the main program that defines the SparkContext, which represents the entry point to interact with Spark. It is responsible for creating RDDs, defining transformations and actions, and orchestrating the execution of tasks on a cluster. The driver program runs the user’s application code and coordinates with the cluster manager to allocate resources and execute tasks.
50. What is the role of a Spark executor?
A Spark executor is a worker process responsible for executing tasks on behalf of the Spark driver program. Executors are launched on worker nodes in a Spark cluster and are responsible for managing and executing tasks assigned to them. They store data in memory or on disk as directed by the driver program and provide the necessary resources for task execution, such as CPU and memory.
51. How does Spark handle fault tolerance?
Spark provides fault tolerance through RDDs. RDDs are designed to be resilient, meaning they can recover lost data partitions due to failures. Spark achieves fault tolerance by tracking the lineage of RDDs, which is the sequence of transformations applied to the base data. If a partition is lost, Spark can recompute it based on the lineage. Additionally, Spark replicates the data across multiple nodes to ensure data availability in case of failures.
52. What is the purpose of a Spark cluster manager?
A Spark cluster manager is responsible for managing resources in a Spark cluster. It allocates resources, such as CPU and memory, to Spark applications and coordinates the execution of tasks across worker nodes. Spark supports multiple cluster managers, such as Apache Mesos, Hadoop YARN, and Spark’s standalone cluster manager. The cluster manager ensures efficient utilization of cluster resources and handles fault tolerance by monitoring and restarting failed tasks or nodes.
53. Provide the syntax to perform a distinct operation on a Spark DataFrame in SQL.
To perform a distinct operation on a Spark DataFrame using SQL syntax, you can use the following syntax:
sql SELECT DISTINCT column1, column2 FROM table_name
54. How do you add a new column to a Spark DataFrame using the DataFrame API in Python?
To add a new column to a Spark DataFrame using the DataFrame API in Python, you can use the withColumn method with the following syntax:
python newDF = df.withColumn("new_column", expression)
55. Explain the concept of Spark’s checkpointing.
Checkpointing in Spark is a mechanism to persist RDDs (Resilient Distributed Datasets) or DStreams (Discretized Streams) to a stable storage system like Hadoop Distributed File System (HDFS). It is primarily used for fault tolerance by allowing the recovery of lost data or partial computation in case of failures.
Checkpointing involves materializing the RDD/DStream to a reliable storage system, which can be expensive in terms of I/O and storage resources. It is typically used in scenarios where lineage information becomes too long or where iterative computations are performed, as it allows lineage to be truncated and saves the intermediate results.
56. How does Spark handle data compression?
Spark provides built-in support for data compression. It supports various compression codecs, including Gzip, Snappy, LZO, and Deflate. When storing data or transmitting data over the network, Spark can automatically compress the data using these codecs to reduce storage space and network bandwidth usage.
Spark allows you to specify the compression codec when reading or writing data using the appropriate APIs, such as spark.read or spark.write. The chosen compression codec is applied during data serialization and deserialization, reducing the size of the data while preserving its integrity.
57. What is the role of SparkSession in Spark?
SparkSession is the entry point for working with structured data in Spark 2. x and above. It provides a single point of entry to interact with various Spark functionalities, including Dataset and DataFrame APIs, SQL queries, and the Spark execution environment.
SparkSession encapsulates the configuration, runtime environment, and services necessary for data processing. It internally creates and manages SparkContext, which is the interface to the underlying Spark cluster and provides access to Spark’s core functionality.
58. Explain the syntax for performing aggregation on a Spark DataFrame in Scala.
To perform an aggregation on a Spark DataFrame in Scala, you can use the groupBy and agg methods with the following syntax:
scala val aggregatedDF = df.groupBy("column_name").agg(functions)
59. What are the key components of Spark MLlib?
- Transformers: Transformers are algorithms or functions that transform one data frame into another, typically by adding or modifying columns. They are used for data preprocessing, feature engineering, and data transformation.
- Estimators: Estimators are algorithms or functions that can be fit on a data frame to produce a model (Transformer). They are used for training machine learning models on data.
- Pipelines: Pipelines are a sequence of stages (transformers and estimators) that are chained together to form an ML workflow. Pipelines simplify the process of building, evaluating, and deploying machine learning models by encapsulating the data transformation and model training steps.
- Models: Models are the result of fitting an estimator on a data frame. They are transformers that can transform new data or make predictions based on the learned patterns from the training data.
60. What is the purpose of Spark GraphX?
Spark GraphX is a graph processing library built on top of Spark, designed for efficient and scalable graph computation. It provides an API for expressing graph computation and a set of optimized graph algorithms. With GraphX, users can perform operations on graphs, such as vertex and edge transformations, graph joins, and graph aggregations.
61. Explain the concept of Spark’s shuffle operation.
Shuffle is an important operation in Spark that occurs when data needs to be redistributed across partitions during a stage boundary. It typically happens when data needs to be grouped, aggregated or joined across different partitions. Shuffle involves shuffling data between nodes in a cluster, which incurs network transfer and disk I/O overhead.
62. How does Spark handle skewed data?
Spark provides mechanisms to handle skewed data, such as skewed join optimization. Skewed data occurs when the distribution of data across partitions is highly imbalanced, leading to performance bottlenecks. Skewed join optimization in Spark identifies skewed keys and applies different strategies to handle them, such as using map-side joins for skewed keys or dynamically repartitioning data to balance the workload. This helps in mitigating the impact of skewed data on query performance.
63. What are the different types of joins supported in Spark?
Spark supports several types of joins, including:
- Inner Join Returns only the matching records from both DataFrames based on the join condition.
- Outer Join: Returns all records from both DataFrames, combining the matching records and null values for non-matching records.
- Left Join: Returns all records from the left DataFrame and the matching records from the right DataFrame. Null values are filled for non-matching records.
- Right Join: Returns all records from the right DataFrame and the matching records from the left DataFrame. Null values are filled for non-matching records.
- Cross Join: Returns the Cartesian product of both DataFrames, resulting in all possible combinations of records.
- Semi Join: Returns only the records from the left DataFrame that have a match in the right DataFrame.
- Anti Join: Returns only the records from the left DataFrame that do not have a match in the right DataFrame.
64. What is the syntax to write a Spark DataFrame to a Parquet file in Scala?
To write a Spark DataFrame to a Parquet file in Scala, you can use the write method with the following syntax: scala df.write.parquet("output.parquet")
65. How does Spark handle data consistency in streaming applications?
Spark ensures data consistency in streaming applications through “exactly-once” semantics using checkpointing and write-ahead logs (WALs).
66. What are the different types of machine learning algorithms supported by Spark MLlib?
Spark MLlib supports various machine learning algorithms, including classification, regression, clustering, recommendation, dimensionality reduction, and survival analysis.
67. Explain the concept of Spark’s columnar storage.
Spark’s columnar storage stores data column-wise, optimizing compression, and query performance, and enabling efficient column pruning and vectorized operations.
68. What is the purpose of Spark’s dynamic resource allocation?
Spark’s dynamic resource allocation allows efficient management of cluster resources based on workload, maximizing resource utilization and system efficiency.
69. How does Spark handle data skewness in machine learning algorithms?
Spark handles data skewness by employing techniques such as salting, bucketing, skewed join optimization, and sampling to distribute and handle skewed data.
70. What is the significance of Spark’s checkpointing in fault tolerance?
Spark’s checkpointing feature provides fault tolerance for streaming applications and iterative machine learning algorithms by saving the application state to a reliable storage system.
71. Explain the concept of Spark’s broadcast variable optimizations.
Spark’s broadcast variable optimizations efficiently distribute read-only data to worker nodes, reducing network overhead and improving performance.
72. What are the different types of data sources supported by Spark?
Spark supports various data sources such as HDFS, Amazon S3, Apache Cassandra, Apache Kafka, JDBC databases, and more.
73. How does Spark handle data replication for fault tolerance?
Spark achieves fault tolerance by replicating data across multiple nodes, allowing for data recovery in case of node failures.
74. What is the purpose of Spark’s partitioning strategies?
Spark’s partitioning strategies determine how data is divided across worker nodes, enabling parallel processing and efficient data locality.
75. How does Spark handle data serialization and deserialization?
Spark uses efficient serialization formats like Java Serialization, Kryo, or Avro to serialize data for distributed processing and deserialize it for computation.
76. Explain the concept of Spark’s shuffle file formats.
Spark’s shuffle file formats determine how data is organized and stored during shuffling operations, impacting performance and disk I/O. Common formats include sort-based shuffle and hash-based shuffle.
77. Explain the concept of Spark’s UDF (User Defined Function).
UDFs enable users to perform complex transformations or computations on the data using their own code logic. By registering a UDF, users can use it as a built-in function within Spark, making it easy to apply the custom logic across large-scale distributed datasets.
78. What is the role of Spark’s DAG scheduler?
The DAG (Directed Acyclic Graph) scheduler is a critical component of Spark’s execution engine. Its role is to transform the high-level logical execution plan, represented as a sequence of transformations on RDDs (Resilient Distributed Datasets) or DataFrames, into a physical execution plan. The DAG scheduler analyzes dependencies between transformations and stages, optimizes their execution order, and generates a DAG of stages. It then submits the stages to the cluster manager for execution.
79. How does Spark handle data skewness in groupBy operations?
Data skewness in groupBy operations refers to an imbalance in the distribution of data among the groups. To mitigate data skewness, Spark provides a feature called “skew join,” which applies to operations like groupBy and join. When data skew is detected, Spark dynamically identifies the skewed keys and partitions them separately. It uses a technique called “map-side aggregation” to pre-aggregate skewed data before the shuffle, reducing the impact of skew on performance.
80. What are the different storage levels supported by Spark?
Spark supports various storage levels for caching and persisting RDDs, DataFrames, or Datasets. The supported storage levels include:
- MEMORY_ONLY: Stores the data in memory as deserialized Java objects.
- MEMORY_AND_DISK: Stores the data in memory and spills to disk if the memory is insufficient.
- MEMORY_ONLY_SER: Stores the data in memory as serialized objects.
- MEMORY_AND_DISK_SER: Stores the data in memory and spills to disk as serialized objects.
- DISK_ONLY: Stores the data on disk only.
- OFF_HEAP: Stores the data off-heap, outside of the JVM heap memory.
81. How does Spark handle schema evolution in structured streaming?
Schema evolution refers to the ability to handle changes in the schema of streaming data over time. Spark’s structured streaming supports schema evolution by providing a concept called “schema inference” or “schema evolution rules.” When reading streaming data, Spark can automatically infer the schema from the incoming data and evolve the existing schema accordingly. It can handle additions, removals, and modifications of columns in the streaming data, ensuring compatibility with the evolving schema.
82. Explain the concept of Spark’s ML Pipelines.
Spark’s ML Pipelines provide a high-level API for building and deploying machine learning workflows. The pipelines consist of a sequence of stages, including transformers, estimators, and model selectors. Transformers transform input data, estimators fit models to the data, and model selectors automatically choose the best model based on evaluation metrics. The pipelines simplify the process of building end-to-end machine learning workflows and enable easy experimentation and model deployment at scale.
83. What is the purpose of Spark’s YARN client mode?
Spark’s YARN client mode is a deployment mode used when running Spark applications on a YARN (Yet Another Resource Negotiator) cluster. In client mode, the Spark driver runs on the client machine and communicates with the YARN Resource Manager to request cluster resources. The client machine needs to be running throughout the application’s execution. YARN client mode is suitable for interactive or debugging scenarios where the client needs to have control over the application execution.
84. What are the key features of Spark’s structured streaming?
- Integration with Spark’s batch processing engine, allowing developers to write streaming queries using the same DataFrame/Dataset API.
- Support for event-time and processing-time-based operations, enabling time-based windowing and aggregations.
- Automatic handling of data late arrival and out-of-order events.
- Fault-tolerance and exactly-once semantics using Spark’s checkpointing mechanism.
- Compatibility with various data sources, including Kafka, HDFS, S3, and more.
- Seamless integration with Spark’s machine learning and graph processing libraries.
85. How does Spark handle data consistency in distributed computations?
Spark ensures data consistency in distributed computations by using a combination of fault-tolerant storage, RDD lineage, and lazy evaluation. It keeps track of the lineage of transformations applied to RDDs, which enables it to recompute lost partitions based on the lineage graph. This lineage information is stored in a fault-tolerant storage system (e.g., HDFS), ensuring that data can be recovered and computations can be retried in case of failures.
86. What is the role of Spark’s task scheduler?
The task scheduler in Spark is responsible for assigning tasks to individual executor nodes in a cluster. It determines the optimal task placement based on factors such as data locality, available resources, and task dependencies. The task scheduler aims to achieve high resource utilization and minimize data movement across the network by scheduling tasks on nodes that have the required data already cached in memory.
87. Explain the concept of Spark’s lineage graph in fault tolerance.
Spark’s lineage graph is a directed acyclic graph (DAG) that represents the dependencies between RDDs and the transformations applied to them. In fault tolerance, the lineage graph plays a crucial role in recovery and recomputation. When a partition of an RDD is lost due to a node failure, Spark can use the lineage graph to identify the transformations that led to the lost partition and recompute it from the available data. By tracing back the lineage, Spark ensures fault tolerance and recovers lost data without needing to rerun the entire computation.
88. What are the different ways to optimize resource utilization in Spark?
- Partitioning: Properly partitioning data can improve parallelism and reduce data skewness.
- Caching and Persistence: Caching frequently accessed data in memory or on disk can significantly speed up subsequent computations.
- Shuffle optimization: Minimizing data shuffling between nodes by using appropriate transformations and aggregations.
- Dynamic resource allocation: Allocating resources dynamically based on the workload to achieve better utilization and avoid underutilization or resource contention.
- Coalescing and repartitioning: Adjusting the number of partitions to balance the workload and optimize data placement.
89. How does Spark handle data skewness in streaming applications?
Spark provides several techniques to handle data skewness in streaming applications:
- Key shuffling: By applying a hash-based partitioning scheme, Spark can distribute data evenly across partitions and reduce skewness.
- Adaptive query execution: Spark can monitor the data distribution and dynamically adjust the execution plan to mitigate skewness.
- Dynamic load balancing: Spark can dynamically move tasks and data across nodes to achieve load balancing and reduce the impact of data skew.
- Sampling and stratified sampling: By sampling the data, Spark can estimate the skewness and apply appropriate transformations to handle it effectively.
90. What is the purpose of Spark’s block size configuration?
The block size configuration in Spark refers to the size of data blocks when reading or writing data to/from storage systems like HDFS. It determines the amount of data that Spark reads or writes in a single I/O operation. Configuring an appropriate block size is important for optimizing data transfer efficiency and minimizing I/O overhead.
91. Explain Spark Driver.
In Apache Spark, the driver is the program that runs the main function and coordinates the execution of tasks across the cluster. It splits the Spark application into tasks and schedules them on the worker nodes. The driver also maintains the SparkContext, which is the entry point for interacting with Spark and managing the cluster resources.
92. How can you store the data in Spark?
Spark provides various ways to store data, including in-memory storage, file systems (like HDFS, and S3), databases (such as Apache Hive, and Apache HBase), and external data sources (Apache Kafka, Apache Cassandra, etc.). These storage options allow Spark to read and write data from different sources and provide flexibility in handling large-scale datasets.
93. Explain the use of File System API in Apache Spark.
The File System API in Spark provides a unified interface to interact with different file systems. It allows reading, writing, and manipulating files stored in various file systems like HDFS, S3, local file systems, and more. The File System API abstracts the underlying file system details and provides a consistent way to access and operate on files, directories, and partitions.
94. What is the task of Spark Engine?
The Spark engine is responsible for executing Spark applications. It includes several components, such as cluster manager integration, DAG scheduler, task scheduler, memory management, and I/O management. The engine handles resource acquisition, task scheduling, memory management, and data processing operations to execute Spark applications efficiently.
95. What is the user of SparkContext?
The user of SparkContext is the application developer or the user who interacts with Spark to create and control Spark applications. SparkContext is the entry point for the user to interact with Spark and represents a connection to a Spark cluster. It allows the user to create RDDs, broadcast variables, and accumulators, as well as perform actions and transformations on distributed datasets.
96. Can you do real-time processing with Spark SQL?
Yes, Spark SQL allows real-time processing of structured and semi-structured data. It provides a programming interface to perform real-time data querying, analysis, and processing using SQL queries, DataFrame API, and Datasets. Spark SQL can process real-time data streams using integration with other streaming technologies like Apache Kafka, Apache Flink, and more. It enables continuous data ingestion, processing, and analysis with low latency.
97. Explain partitions.
Partitions are the fundamental units of parallelism in Spark. They represent smaller chunks of data that can be processed independently by different worker nodes in a distributed computing environment. Spark divides datasets into partitions, allowing parallel execution of tasks on multiple partitions across the cluster. Partitions enable efficient data processing by enabling parallelism and minimizing data movement between nodes.
98. Define the term ‘Lazy Evaluation’ with reference to Apache Spark.
Lazy evaluation is a strategy used by Apache Spark to optimize the execution of transformations on distributed datasets (RDDs). Instead of immediately executing each transformation when called, Spark delays the execution until an action is triggered. This allows Spark to optimize the execution plan by combining multiple transformations into efficient stages and minimizing data shuffling. Lazy evaluation helps Spark to avoid unnecessary computations and improve overall performance.
99. How can you use Akka with Spark?
Akka is a popular open-source toolkit and runtime for building highly concurrent and distributed applications in the Java Virtual Machine (JVM) ecosystem. It provides a message-passing concurrency model and actors for building distributed systems. Akka can be integrated with Apache Spark to enhance its fault tolerance, scalability, and concurrency.
100. Can you use Spark for ETL processes?
Yes, Spark is widely used for ETL (Extract, Transform, Load) processes. Spark’s ability to handle large-scale data processing, its rich set of APIs, and its support for various data sources make it a powerful tool for ETL pipelines. Spark can extract data from different sources, perform transformations on the data using its DataFrame and Dataset APIs, and load the processed data into target systems or storage. Spark’s distributed processing capabilities enable efficient and scalable ETL workflows.
The Top 100 Spark Interview Questions and Answers provide comprehensive information on Spark technical interview questions, covering everything from installation to advanced concepts. For additional insightful content and information, we recommend following freshersnow.com.