
| Join Telegram |  |
| Join Whatsapp Groups |  |
SQL Interview Questions and Answers: If you’re preparing for an upcoming SQL technical interview, you may be wondering what types of questions you’ll encounter. Fortunately, there are a plethora of resources available to help you prepare, including the latest SQL interview questions and answers. In this article, we’ll be discussing the top 100 SQL interview questions and answers, covering everything from basic SQL concepts to more complex topics.
★★ Latest Technical Interview Questions ★★
SQL Technical Interview Questions
Whether you’re a seasoned SQL professional or a fresher just starting out, this guide is designed to help you ace your next SQL interview. So, let’s dive into the most commonly asked SQL interview questions for freshers and experienced professionals alike.
Top 100 SQL Interview Questions and Answers
Begin exploring this section immediately to familiarize yourself with the Top SQL Interview Questions and Answers available.
1. What is SQL, and how is it used in database management systems?
- SQL stands for Structured Query Language, a programming language used for managing relational databases.
- SQL allows users to create, modify, and query databases using a standard syntax.
- SQL is used in many database management systems, including MySQL, PostgreSQL, Oracle, and Microsoft SQL Server.
2. What are some common SQL commands for retrieving data from a database?
- SELECT: retrieves data from one or more tables in a database.
- WHERE: filters data based on a specified condition.
- ORDER BY: sorts data in ascending or descending order.
- LIMIT: limits the number of rows returned by a query.
- JOIN: combines data from two or more tables based on a specified condition.
3. How do you create a table in SQL, and what are the different data types that you can use to define columns?
To create a table in SQL, you can use the CREATE TABLE statement followed by the table name and column definitions. The column definitions specify the column name, data type, and any constraints.
Example:
| CREATE TABLE employees ( employee_id INT, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(100), hire_date DATE, salary DECIMAL(10, 2) ); |
Some of the data types that you can use to define columns include:
- INT: integer
- VARCHAR: variable-length character string
- DATE: date
- DECIMAL: decimal number
- BOOLEAN: true/false value
4. How do you define a primary key in a SQL table, and why is it important?
- A primary key is a unique identifier for each row in a table.
- To define a primary key in a SQL table, use the PRIMARY KEY constraint on one or more columns.
- It is important to have a primary key in a table because it ensures that each row can be uniquely identified and that data is consistent across the table. It also allows for efficient data retrieval and indexing.
5. What is the difference between a join and a subquery in SQL, and when would you use one over the other?
- A join combines data from two or more tables based on a specified condition, while a subquery is a query within a query that retrieves data based on a specified condition.
- Joins are used when data from multiple tables needs to be combined in a single query, while subqueries are used when a query needs to be executed based on the results of another query.
- Joins are generally faster than subqueries for large datasets, but subqueries can be more flexible and easier to read and maintain.
6. How do you use the GROUP BY clause in SQL, and what does it do?
- The GROUP BY clause is used to group rows in a table based on a specified column or columns.
- It is used with aggregate functions such as SUM, COUNT, AVG, MIN, and MAX to perform calculations on each group of rows.
- The GROUP BY clause is useful for generating summary reports and analyzing data based on different categories.
7. What is the difference between a WHERE clause and a HAVING clause in SQL, and when would you use one over the other?
| WHERE Clause | HAVING Clause |
| Used with SELECT, UPDATE, and DELETE statements | Used with SELECT statements |
| Filters data based on conditions in a single table | Filters data based on conditions that involve aggregate functions |
| Cannot be used with aggregate functions | Can only be used with aggregate functions |
| Applied before the GROUP BY clause | Applied after the GROUP BY clause |
You would use a WHERE clause when you want to filter data based on conditions in a single table, and a HAVING clause when you want to filter data based on conditions that involve aggregate functions.
8. What is the difference between the HAVING clause and the WHERE clause in SQL?
- The WHERE clause is used to filter rows based on a specified condition.
- The HAVING clause is used to filter groups based on a specified condition.
- The WHERE clause is used with the SELECT, UPDATE, and DELETE statements, while the HAVING clause is used with the GROUP BY clause.
9. How do you create a new table in SQL, and what are some common data types that can be used for columns?
- To create a new table in SQL, use the CREATE TABLE statement followed by the table name and column definitions.
- Common data types that can be used for columns include INT (integer), VARCHAR (variable-length string), DATE (date), and BOOLEAN (true/false).
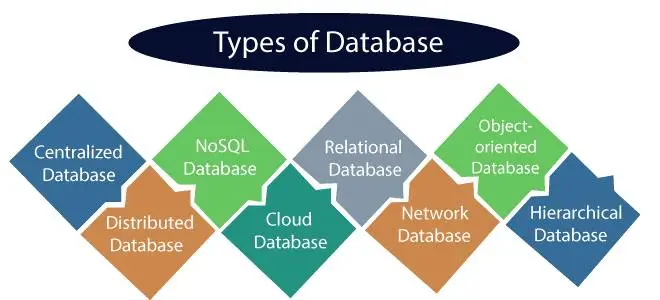
10. What do you mean by DBMS? What are its different types?
DBMS stands for Database Management System, which is a software system that enables users to create, manage, and access databases. It provides an interface between the user and the database, allowing users to interact with the database in a controlled manner.
There are different types of DBMS, including:
- Relational Database Management System (RDBMS): This type of DBMS is based on the relational model and stores data in the form of tables or relations. RDBMSs are the most common type of DBMS and are used in various applications.
- Object-Oriented Database Management System (OODBMS): This type of DBMS is based on the object-oriented programming paradigm and stores data in the form of objects. OODBMSs are mainly used in applications that involve complex data structures.
- Hierarchical Database Management System (HDBMS): This type of DBMS stores data in a hierarchical structure, where each record is linked to one or more parent records. HDBMSs are mainly used in applications that involve storing data in a tree-like structure.
- Network Database Management System (NDBMS): This type of DBMS stores data in a network structure, where each record can have multiple parent and child records. NDBMSs are mainly used in applications that involve complex relationships between data elements.
- NoSQL Database Management System: This type of DBMS is designed to handle large volumes of unstructured data, such as social media data, text, and multimedia content. NoSQL DBMSs are used in applications that require scalability, performance, and high availability.
- Cloud-Based Database Management System: This type of DBMS is a cloud-based service that provides users with access to a database hosted on a cloud infrastructure. Cloud-based DBMSs are used in applications that require scalability, flexibility, and low operational costs.
- Distributed Database Management System (DDBMS): This type of DBMS is a centralized system that manages multiple databases located on different sites. DDBMSs are used in applications that require data to be shared and accessed from multiple locations.
- Time Series Database Management System (TSDBMS): This type of DBMS is designed to handle time-series data, such as sensor data, financial data, and logs. TSDBMSs are used in applications that require efficient storage and retrieval of time-series data.
The type of DBMS used in an application depends on various factors, such as the size of the data, the complexity of the data structure, the performance requirements, and the cost constraints.
11. How do you modify an existing table in SQL, and what are some common commands for doing so?
- To modify an existing table in SQL, use the ALTER TABLE statement followed by the table name and the desired modification.
- Common commands for modifying tables include ADD COLUMN (adding a new column), DROP COLUMN (removing a column), and ALTER COLUMN (modifying the data type or constraints of a column).
12. What is the difference between the INNER JOIN and OUTER JOIN keywords in SQL, and when would you use one over the other?
| INNER JOIN | OUTER JOIN |
| Returns only the rows that have matching values in both tables | Returns all the rows from one or both tables, depending on the type of outer join |
| Can be used with other types of joins | Can be left, right, or full |
| Only returns rows that have a match in both tables | Returns all rows from one table and any matching rows from the other table, or all rows from both tables with nulls in the columns that don’t match |
| Used when you only want to retrieve data that has matching values in both tables | Used when you want to retrieve data that may or may not have matching values in both tables |
You would use an INNER JOIN when you only want to retrieve data that has matching values in both tables, and an OUTER JOIN when you want to retrieve data that may or may not have matching values in both tables.
13. How do you insert data into a table in SQL, and what are the different ways to insert multiple rows at once?
To insert data into a table in SQL, you can use the INSERT INTO statement followed by the table name and the values to be inserted. You can insert data into all columns or specify the columns to be inserted into.
Example:
| INSERT INTO employees (employee_id, first_name, last_name, email, hire_date, salary) VALUES (1, ‘John’, ‘Doe’, ‘johndoe@example.com’, ‘2020-01-01’, 50000.00); |
To insert multiple rows at once, you can use the VALUES clause with multiple sets of values.
Example:
| INSERT INTO employees (employee_id, first_name, last_name, email, hire_date, salary) VALUES (2, ‘Jane’, ‘Doe’, ‘janedoe@example.com’, ‘2020-02-01’, 60000.00), (3, ‘Bob’, ‘Smith’, ‘bobsmith@example.com’, ‘2020-03-01’, 70000.00); |
14. What is normalization in SQL, and why is it important for database design?
- Normalization is the process of organizing data in a database to reduce redundancy and dependency.
- It is important for database design because it ensures that data is stored in a consistent and efficient manner, which can improve performance, reduce errors, and simplify queries.
15. How do you insert new data into a SQL table, and what are some common errors that can occur during this process?
- To insert new data into a SQL table, use the INSERT INTO statement followed by the table name and column values.
- Common errors that can occur during this process include duplicate key values, data type mismatches, and constraint violations.
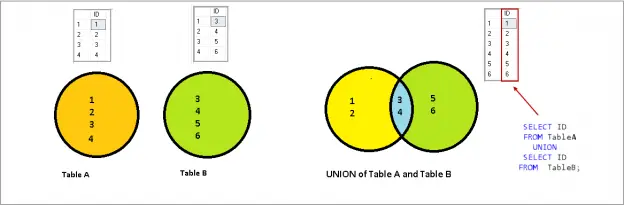
16. What is the difference between the UNION and UNION ALL operators in SQL, and when would you use one over the other?
| UNION | UNION ALL |
| Combines the results of two or more SELECT statements into a single result set | Combines the results of two or more SELECT statements into a single result set, including duplicates |
| Removes duplicate rows from the result set | Includes duplicate rows in the result set |
| Slower than UNION ALL because it has to check for and remove duplicates | Faster than UNION because it doesn’t have to check for duplicates |
You would use a UNION when you want to combine the results of two or more SELECT statements into a single result set without including duplicates, and a UNION ALL when you want to combine the results of two or more SELECT statements into a single result set and include duplicates.
17. What is the difference between an inner join and an outer join in SQL, and when would you use one over the other?
- An inner join returns only the rows that have matching values in both tables.
- An outer join returns all the rows from one table and the matching rows from the other table.
- Use an inner join when you only want to retrieve data that exists in both tables, and use an outer join when you want to retrieve all data from one table and matching data from the other table.
18. How do you use the UNION operator in SQL, and what does it do?
- The UNION operator is used to combine the results of two or more SELECT statements into a single result set.
- The columns in each SELECT statement must have the same data type and order.
- The UNION operator removes any duplicate rows from the result set.
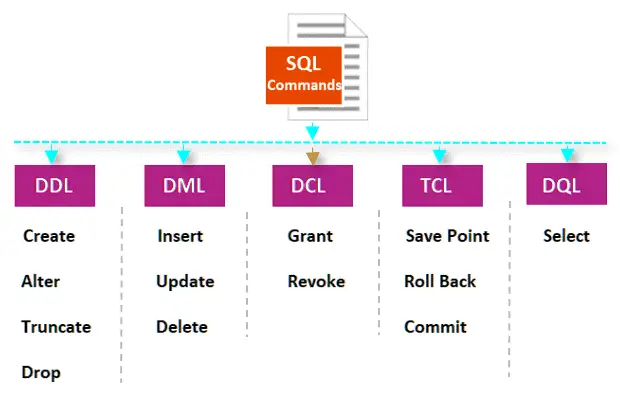
19. Explain the different types of SQL commands.
SQL (Structured Query Language) has several different types of commands that are used to perform different operations on a relational database. These commands can be categorized into four main types:
- Data Definition Language (DDL): DDL commands are used to define, modify, and delete the structure of a database and its objects, such as tables, views, indexes, and constraints. The commonly used DDL commands are CREATE, ALTER, and DROP.
- Data Manipulation Language (DML): DML commands are used to manipulate the data stored in a database. The commonly used DML commands are SELECT, INSERT, UPDATE, and DELETE.
- Data Control Language (DCL): DCL commands are used to control the access and permissions of the database users. The commonly used DCL commands are GRANT and REVOKE.
- Transaction Control Language (TCL): TCL commands are used to manage transactions in a database. Transactions are a group of database operations that are executed as a single unit of work. The commonly used TCL commands are COMMIT, ROLLBACK, and SAVEPOINT.
Some databases may also include additional commands, such as analytical functions, that allow you to perform complex analysis on the data stored in a database.
In summary, the different types of SQL commands are used to define the structure of a database, manipulate the data stored in the database, control access and permissions of users, and manage transactions.
20. How do you use the LIKE operator in SQL, and what are some common wildcards that can be used with it?
- The LIKE operator is used to match patterns in a column.
- Common wildcards that can be used with the LIKE operator include % (matches any string of zero or more characters), _ (matches any single character), and [] (matches any character within the specified range).
21. What is the difference between a primary key and a foreign key in SQL, and when would you use one over the other?
| Primary Key | Foreign Key |
| Unique identifier for a table | References the primary key in another table |
| Must be unique and not null | Can be null or have duplicate values |
| Used to enforce entity integrity | Used to enforce referential integrity |
| Only one primary key per table | Multiple foreign keys can be used in a table |
| Used to establish relationships between tables | Used to establish relationships between tables |
You would use a primary key when you want to uniquely identify each row in a table and enforce entity integrity, and a foreign key when you want to establish a relationship between two tables and enforce referential integrity.
22. How do you use the BETWEEN operator in SQL, and what does it do?
- The BETWEEN operator is used to retrieve values that are within a specified range.
- It is inclusive, meaning that it includes the values at both ends of the range.
- Use the BETWEEN operator after the column name, followed by the lower and upper bounds of the range.
23. What is the difference between the IN and NOT IN operators in SQL, and when would you use one over the other?
- The IN operator is used to retrieve data that matches any value in a list or subquery.
- The NOT IN operator is used to retrieve data that does not match any value in a list or subquery.
- Use the IN operator when you want to retrieve data that matches any value in a list, and use the NOT IN operator when you want to retrieve data that does not match any value in a list.
24. How do you update data in a table in SQL, and what is the difference between the UPDATE and MERGE statements?
To update data in a table in SQL, you can use the UPDATE statement followed by the table name and the new values to be updated. You can update one or more columns at once.
Example:
| UPDATE employees SET salary = 55000.00 WHERE employee_id = 1; |
The MERGE statement is used to combine data from two tables and update or insert data into a target table. It is similar to the UPDATE statement, but it can update or insert data based on a condition.
Example:
| MERGE INTO employees e USING ( SELECT employee_id, salary FROM employee_updates ) u ON (e.employee_id = u.employee_id) WHEN MATCHED THEN UPDATE SET e.salary = u.salary WHEN NOT MATCHED THEN INSERT (employee_id, salary) VALUES (u.employee_id, u.salary); |
25. How do you use the CASE statement in SQL, and what does it do?
- The CASE statement is used to perform conditional logic in SQL.
- It allows you to return different values based on different conditions.
- Use the CASE statement after the SELECT statement, followed by the conditions and values you want to return.
26. Can you explain the difference between UNION and UNION ALL in SQL, and in what scenarios would you use each one?
- UNION and UNION ALL are two SQL set operators used to combine the results of two or more SELECT statements. The main difference between the two is that UNION removes duplicates from the result set, while UNION ALL does not.
- When using UNION, the result set will only contain distinct rows. For example, if two tables have overlapping rows with the same values, the UNION operator will return only one of those rows. This can be useful when combining data from different sources that may contain duplicate data.
- On the other hand, UNION ALL does not remove duplicates, meaning it will return all the rows from all the tables, including any duplicates. This is useful when you need to combine data from multiple sources and want to include all the data, even if there are duplicates.
- The choice between UNION and UNION ALL depends on the specific needs of the query. If duplicate rows are not needed, then UNION is the appropriate operator. If duplicates are desired or if there is no risk of duplicates, then UNION ALL can be used for better performance since it doesn’t have to perform the extra step of removing duplicates.
- In summary, UNION and UNION ALL are SQL operators used to combine data from two or more tables. UNION removes duplicates from the result set, while UNION ALL includes all rows from all tables, including duplicates. The choice between the two depends on the specific requirements of the query.
27. What is the difference between the COUNT and SUM aggregate functions in SQL, and when would you use one over the other?
| COUNT | SUM |
| Returns the number of rows in a result set | Returns the total sum of values in a column |
| Can be used with any data type | Can only be used with numeric data types |
| Includes null values in the count | Ignores null values |
| Does not require a column to be specified | Requires a column to be specified |
| Used to determine the size of a result set | Used to determine the total value of a column |
You would use COUNT when you want to determine the size of a result set, including null values, and SUM when you want to determine the total value of a column, excluding null values. Additionally, COUNT can be used with any data type, while SUM can only be used with numeric data types.
28. How do you use the ORDER BY clause in SQL, and what does it do?
- The ORDER BY clause is used to sort the results of a query in ascending or descending order.
- Use the ORDER BY clause after the SELECT statement, followed by the column(s) you want to sort by.
- By default, it sorts in ascending order, but you can use the DESC keyword to sort in descending order.
29. What is a trigger in SQL, and how do you create one?
- A trigger is a special type of stored procedure that is automatically executed when a certain event occurs.
- It can be used to perform actions such as inserting, updating, or deleting data.
- Use the CREATE TRIGGER statement to create a new trigger, followed by the SQL statements you want to include in the trigger.
30. What is the difference between a view and a table in SQL, and when would you use one over the other?
- A table is a physical object in the database that stores data, while a view is a virtual table that is based on a query.
- Views do not store data themselves but rather display data from one or more tables.
- Use a table when you need to store data, and use a view when you want to simplify complex queries or restrict access to certain columns or rows.
31. How do you use the MAX() and MIN() functions in SQL, and what do they do?
- The MAX() function returns the maximum value from a column in a table, while the MIN() function returns the minimum value.
- Use the MAX() or MIN() function after the SELECT statement, followed by the column you want to retrieve the maximum or minimum value from.
32. How do you delete data from a table in SQL, and what is the difference between the DELETE and TRUNCATE statements?
To delete data from a table in SQL, you can use the DELETE statement followed by the table name and a condition that specifies which rows to delete.
Example:
| DELETE FROM employees WHERE employee_id = 1; |
The TRUNCATE statement is used to delete all data from a table. It is faster than the DELETE statement because it does not log individual row deletions, but it also cannot be undone.
Example:
| TRUNCATE TABLE employees; |
33. How do you use the COUNT() function in SQL, and what does it do?
- The COUNT() function is used to retrieve the number of rows in a table or the number of rows that match a specific condition.
- Use the COUNT() function after the SELECT statement, followed by the column you want to count, or use the asterisk (*) to count all rows.
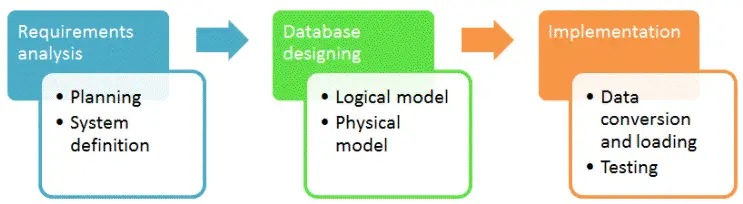
34. How would you approach designing a database schema for a new project, and what factors would you consider when making decisions about the structure of the database?
Designing a database schema for a new project is a critical task, as it lays the foundation for the entire project. The following are some key factors that should be considered when designing a database schema:
- Identify the objectives and requirements of the project: Before designing a database schema, it is important to clearly identify the objectives and requirements of the project. This includes understanding what data needs to be stored, how it will be used, and who will be using it.
- Normalize the data: Normalization is the process of organizing data in a database to reduce redundancy and dependency. A well-normalized database schema can help to minimize data duplication and improve data consistency, accuracy, and reliability.
- Determine the data relationships: Data relationships describe how different pieces of data are related to each other. Understanding the relationships between data entities can help to design an efficient and effective database schema.
- Consider data access patterns: The database schema should be designed with data access patterns in mind. This includes understanding how frequently data will be read, updated, and deleted, and designing the schema accordingly.
- Consider scalability and performance: The database schema should be designed with scalability and performance in mind. This includes considering the number of users, the size of the data set, and the frequency of data access, and designing the schema to handle these factors.
- Choose appropriate data types: The database schema should use appropriate data types for each field to ensure that data is stored efficiently and accurately.
- Define constraints: Constraints define rules that must be followed when inserting or updating data in the database. Constraints can help to ensure data integrity and consistency.
In summary, designing a database schema for a new project requires careful consideration of the project’s objectives and requirements, data normalization, data relationships, data access patterns, scalability and performance, appropriate data types, and constraints.
35. How do you use the SUM() function in SQL, and what does it do?
- The SUM() function is used to retrieve the sum of values in a column in a table.
- Use the SUM() function after the SELECT statement, followed by the column you want to sum.
36. How do you use the AVG() function in SQL, and what does it do?
- The AVG() function is used to retrieve the average value of a column in a table.
- Use the AVG() function after the SELECT statement, followed by the column you want to average.
37. How do you use the NULL keyword in SQL, and what does it signify?
- The NULL keyword is used to represent a missing or unknown value in a column of a table.
- It signifies that the value is unknown, unavailable, or not applicable.
- How do you use the EXISTS operator in SQL, and what does it do?
- The EXISTS operator is used to check if a subquery returns any rows.
- It returns a boolean value of true or false, depending on whether the subquery returns any rows.
38. How do you join two or more tables in SQL, and what are the different types of joins that you can use?
To join two or more tables in SQL, you can use the JOIN keyword followed by the table name and the ON clause, which specifies the condition for joining the tables.
Example:
| SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e JOIN departments d ON e.department_id = d.department_id; |
There are several types of joins that you can use in SQL:
- INNER JOIN: returns only the rows that have matching values in both tables
- LEFT JOIN: returns all the rows from the left table and the matching rows from the right table
- RIGHT JOIN: returns all the rows from the right table and the matching rows from the left table
- FULL OUTER JOIN: returns all the rows from both tables, with NULL values in the columns where there is no match
Example:
| SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e FULL OUTER JOIN departments d ON e.department_id = d.department_id; |
39. What is a temporary table in SQL, and how is it different from a regular table?
- A temporary table is a table that is created and used for a temporary purpose within a session.
- It is different from a regular table in that it is not stored permanently in the database, and it is automatically dropped when the session ends.
40. What are the advantages and disadvantages of using stored procedures in SQL, and in what scenarios would you recommend their use?
Stored procedures are pre-written database programs that can be executed from within an application or directly from a database management system. While they offer a number of benefits, such as improved performance and better security, there are also some drawbacks to consider.
Advantages of using stored procedures in SQL:
- Improved performance: Stored procedures can significantly improve database performance by reducing the amount of data transmitted between the database and application. Because the code is already compiled and stored in the database, it can be executed much faster than dynamic SQL statements.
- Better security: Stored procedures can help improve database security by limiting the access that application users have to the underlying data. By granting users permission to execute a stored procedure, but not to access the underlying tables directly, you can limit the potential for security breaches.
- Easier maintenance: Because stored procedures are stored in the database, they can be easily updated and maintained without affecting the application code. This makes it easier to modify the database schema without breaking any existing code.
- Code reusability: Stored procedures can be called from multiple applications, allowing for code reusability and standardization across different applications.
Disadvantages of using stored procedures in SQL:
- Increased complexity: Stored procedures can add complexity to the database design, as well as to the application code that calls them. This can make it more difficult to develop and maintain applications.
- Limited portability: Stored procedures are typically specific to a particular database management system and may not be easily portable to other systems. This can limit the ability to migrate applications to new platforms or to support multiple database systems.
- Debugging difficulties: Debugging stored procedures can be more difficult than debugging application code, as there is often less visibility into the code as it executes.
- Additional overhead: Stored procedures can add additional overhead to the database system, particularly during development and testing.
When to use stored procedures in SQL:
Stored procedures are well-suited for scenarios where performance is critical and where security is a concern. They are also useful in situations where code reusability is important, such as in a multi-application environment. Additionally, stored procedures can be useful in situations where complex business logic needs to be implemented in the database.
However, stored procedures may not be the best choice in all scenarios. They may add unnecessary complexity to simple database applications or when there is limited need for performance optimization or security restrictions.

41. How do you use the LIMIT keyword in SQL, and what does it do?
- The LIMIT keyword is used to limit the number of rows returned by a query.
- Use the LIMIT keyword after the SELECT statement, followed by the number of rows you want to retrieve.
42. What is the difference between SQL and MySQL?
| SQL | MySQL |
|---|---|
| SQL stands for Structured Query Language, which is a standard language used for managing relational databases. | MySQL is a popular open-source relational database management system (RDBMS) that uses SQL as its language. |
| SQL is a language that can be used to communicate with various RDBMSs, such as MySQL, Oracle, Microsoft SQL Server, and PostgreSQL. | MySQL is a specific RDBMS that uses SQL as its primary language. |
| SQL is used to create, modify, and delete tables and data, as well as perform operations such as searching, sorting, and filtering data. | MySQL is used to store and manage data in a relational database. It allows users to create, modify, and delete tables, as well as insert, update, and delete data. |
| SQL has several standards, such as SQL-92, SQL-99, and SQL:2003. | MySQL is compliant with the SQL-92 standard, but also has its own extensions and features. |
| SQL can be used to create complex queries and perform advanced operations, such as joins, subqueries, and aggregations. | MySQL supports various types of joins, subqueries, and aggregations, as well as other advanced features such as transactions, stored procedures, and triggers. |
| SQL is a language that can be used by developers, database administrators, and data analysts to interact with databases. | MySQL is an RDBMS that is commonly used by web developers and businesses to store and manage data. |
| SQL is widely used in various industries, such as finance, healthcare, and e-commerce. | MySQL is particularly popular for web applications and websites due to its ease of use, scalability, and cost-effectiveness. |
43. What is the difference between a clustered and a non-clustered index in SQL, and when would you use one over the other?
- A clustered index determines the physical order of data in a table, while a non-clustered index uses a separate structure to store the index data.
- A table can have only one clustered index, while it can have multiple non-clustered indexes.
- A clustered index is typically used for columns that are frequently used for sorting or searching, while non-clustered indexes are used for other columns.
- When deciding between a clustered and non-clustered index, consider the size of the table, the frequency of data modification, and the types of queries that will be performed.
44. How do you use the ALTER TABLE statement in SQL, and what are some common modifications you can make to a table using it?
- ALTER TABLE statement is used to modify the structure of an existing table in SQL.
- Common modifications include adding or dropping columns, changing the data type of columns, and renaming columns or the table itself.
- You can also add constraints like primary keys or foreign keys to a table using the ALTER TABLE statement.
45. What is a foreign key in SQL, and how do you use it to establish relationships between tables?
- A foreign key is a column in a table that references the primary key of another table, establishing a relationship between the two tables.
- The foreign key ensures that data in the referencing table (child table) is consistent with data in the referenced table (parent table).
- To create a foreign key, you specify the column in the child table that references the primary key in the parent table using the FOREIGN KEY constraint.
46. What is a self-join in SQL, and how do you use it to retrieve data from a single table?
- A self-join is a join operation where a table is joined with itself.
- Self-joins are useful for retrieving data that involves relationships between records within a single table, such as hierarchical data or data with multiple levels.
- To perform a self-join, you use a table alias to give the table a different name for each instance of the join operation.
47. What is the difference between a natural join and an equi-join in SQL, and when would you use one over the other?
- A natural join is a type of join operation that matches columns in two tables with the same name and returns only the matching rows.
- An equi-join is a type of join operation that matches rows in two tables based on a specified column or expression and returns only the matching rows.
- Natural joins are convenient when the column names are the same in both tables, while equi-joins are useful when the column names are different or when you need to join on a non-matching column.
48. How do you use subqueries in SQL, and what are some common use cases for subqueries?
A subquery is a query that is nested inside another query. It can be used to retrieve data that will be used in the main query, or to filter data based on certain conditions.
Example:
| SELECT * FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location_id = 1); |
Some common use cases for subqueries include:
- Filtering data based on a condition in another table
- Retrieving data that will be used in calculations or other operations in the main query
- Checking for the existence of certain data in another table
49. How do you use the COALESCE function in SQL, and what does it do?
- The COALESCE function is used to return the first non-null value in a list of expressions.
- The syntax for COALESCE is COALESCE(expr1, expr2, … , exprN).
- It returns the first non-null expression from the list of expressions.
- If all expressions in the list are null, it returns null.
50. What is a cross join in SQL, and how do you use it to combine data from multiple tables?
- A cross join in SQL is used to combine all rows from two or more tables.
- It returns a Cartesian product of rows from all tables involved in the join.
- The syntax for a cross join is SELECT * FROM table1 CROSS JOIN table2;
- The resulting table will have every possible combination of rows from table1 and table2.
51. What is the difference between a left join and a right join in SQL, and when would you use one over the other?
- A left join in SQL returns all the rows from the left table and the matching rows from the right table. If there is no match, it returns null values for the columns from the right table.
- A right join in SQL returns all the rows from the right table and the matching rows from the left table. If there is no match, it returns null values for the columns from the left table.
- You would use a left join when you want to include all rows from the left table and only matching rows from the right table. You would use a right join when you want to include all rows from the right table and only matching rows from the left table.
52. How do you use the UPDATE statement in SQL, and what are some common mistakes to avoid when updating data in a table?
- The UPDATE statement is used to modify existing data in a table.
- The syntax for UPDATE is UPDATE table SET column1 = value1, column2 = value2 WHERE condition;
- Some common mistakes to avoid when updating data in a table include:
- Not including a WHERE clause, which will update all rows in the table.
- Not using proper quotation marks around string values.
- Not using proper syntax when updating values in columns that have foreign key constraints.
53. How do you create indexes in SQL, and what is their purpose?
An index is a data structure that is used to speed up the retrieval of data from a table. It is created on one or more columns of a table, and it contains a copy of the column data along with a reference to the original data in the table.
To create an index in SQL, you can use the CREATE INDEX statement followed by the index name, the table name, and the column(s) to be indexed.
Example:
| CREATE INDEX idx_last_name ON employees (last_name); |
The purpose of indexes is to improve the performance of queries by reducing the amount of time it takes to find the data that is needed.
54. How do you use the DELETE statement in SQL, and what are some common mistakes to avoid when deleting data from a table?
- The DELETE statement is used to remove data from a table.
- The syntax for DELETE is DELETE FROM table WHERE condition;
- Some common mistakes to avoid when deleting data from a table include:
- Not including a WHERE clause, which will delete all rows in the table.
- Not using proper syntax when deleting rows that have foreign key constraints.
- Not backing up the table before performing a delete operation.
55. What is a subquery in SQL, and how do you use it to retrieve data from multiple tables?
- A subquery is a query that is embedded within another query, and it is used to retrieve data from multiple tables.
- It is also known as an inner query or nested query, and it can be used in SELECT, INSERT, UPDATE, and DELETE statements.
- Subqueries can be used to filter, sort, group, or aggregate data from multiple tables based on certain conditions.
56. How do you use the FULL OUTER JOIN operator in SQL, and what does it do?
- A FULL OUTER JOIN is a type of join that returns all rows from both tables, including the rows that do not have matching values in the other table.
- It combines the results of a LEFT OUTER JOIN and a RIGHT OUTER JOIN, and it is also known as a FULL JOIN.
- In SQL, the FULL OUTER JOIN operator is written as “FULL OUTER JOIN” or “FULL JOIN”, and it is used to retrieve data from two or more tables based on matching values.
57. What is a correlated subquery in SQL, and how is it different from a regular subquery?
- A correlated subquery is a subquery that is dependent on the outer query, and it is used to retrieve data from multiple tables based on certain conditions.
- It differs from a regular subquery in that it uses a value from the outer query to filter the results of the subquery.
- Correlated subqueries can be used in SELECT, INSERT, UPDATE, and DELETE statements, and they are typically slower and less efficient than regular subqueries.
58. How do you use the EXCEPT and INTERSECT operators in SQL, and what do they do?
- The EXCEPT operator is used to retrieve all the rows from the first query that do not appear in the second query.
- The INTERSECT operator is used to retrieve all the rows that appear in both the first and second queries.
- Both operators can be used in SELECT statements to compare data from two or more tables based on certain conditions.
59. What is the difference between a left outer join and a left semi join in SQL?
- A left outer join returns all the rows from the left table and matching rows from the right table, while the non-matching rows from the right table are returned as NULL.
- A left semi join, on the other hand, returns only the rows from the left table that have matching rows in the right table.
- In SQL, the left outer join operator is written as “LEFT OUTER JOIN” or “LEFT JOIN”, while the left semi join operator is written as “LEFT SEMI JOIN”.
60. How do you use the CASE expression in SQL, and what is the syntax for using it?
- The CASE expression in SQL is used to evaluate conditions and return a value based on the result of the evaluation.
- It is similar to the IF-THEN-ELSE statement in other programming languages.
- The syntax for using the CASE expression is as follows:
| CASE expression WHEN condition1 THEN result1 WHEN condition2 THEN result2 ELSE result3 END |
Example:
| SELECT column_name, CASE WHEN column_name = ‘value1’ THEN ‘result1’ WHEN column_name = ‘value2’ THEN ‘result2’ ELSE ‘result3’ END AS new_column_name FROM table_name; |
61. What is the difference between the INNER JOIN and CROSS JOIN operators in SQL, and when would you use one over the other?
- The INNER JOIN and CROSS JOIN operators in SQL are used to combine data from two or more tables into a single result set.
- The main difference between them is that an INNER JOIN returns only the matching rows from both tables, while a CROSS JOIN returns all possible combinations of rows from both tables.
- You would use an INNER JOIN when you want to retrieve only the rows that have matching values in both tables, and you would use a CROSS JOIN when you want to retrieve all possible combinations of rows from both tables.
- Example of an INNER JOIN: SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.id;
- Example of a CROSS JOIN: SELECT * FROM table1 CROSS JOIN table2;
62. How do you use the PIVOT and UNPIVOT operators in SQL, and what do they do?
- The PIVOT and UNPIVOT operators in SQL are used to transform data from a row-based format to a column-based format and vice versa.
- The PIVOT operator is used to aggregate and rotate data from multiple rows into a single row, based on a specified column.
- The UNPIVOT operator is used to transform data from multiple columns into multiple rows, based on a specified column.
- Example of a PIVOT query: SELECT * FROM table_name PIVOT (SUM(column_name) FOR pivot_column IN ([value1], [value2], [value3]));
- Example of an UNPIVOT query: SELECT id, column_name, value FROM table_name UNPIVOT (value FOR column_name IN ([column1], [column2], [column3]));
63. What is the difference between a clustered index and a non-clustered index in SQL, and when would you use one over the other?
- A clustered index in SQL is used to physically sort and store data in a table based on the values of one or more columns. A table can have only one clustered index.
- A non-clustered index is used to create a separate data structure that stores the index keys and the pointer to the actual data. A table can have multiple non-clustered indexes.
- You would use a clustered index when you want to improve the performance of queries that retrieve large amounts of data or when you want to enforce a primary key constraint.
- You would use a non-clustered index when you want to improve the performance of queries that retrieve small amounts of data or when you want to enforce a unique constraint.
- Example of creating a clustered index: CREATE CLUSTERED INDEX index_name ON table_name (column_name);
- Example of creating a non-clustered index: CREATE NONCLUSTERED INDEX index_name ON table_name (column_name);
64. How do you use the CASE statement in SQL, and what is its syntax?
The CASE statement is used to perform conditional logic in SQL. It allows you to specify different actions to be taken depending on a certain condition.
The syntax of the CASE statement is as follows:
| CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ELSE result3 END |
Example:
| SELECT employee_id, first_name, last_name, CASE WHEN salary > 50000 THEN ‘High’ WHEN salary > 40000 THEN ‘Medium’ ELSE ‘Low’ END AS salary_level FROM employees; |
In this example, the CASE statement is used to create a new column called salary_level, which categorizes employees based on their salary.
65. How do you use the ROW_NUMBER() function in SQL, and what does it do?
- The ROW_NUMBER() function in SQL is used to assign a unique sequential number to each row in a result set.
- It is typically used to generate a ranking of the rows based on a specified order.
- The syntax for using the ROW_NUMBER() function is as follows:
SELECT ROW_NUMBER() OVER (ORDER BY column_name) AS row_num, column_name FROM table_name;
- The ORDER BY clause specifies the column(s) by which the rows are sorted.
- Example: SELECT ROW_NUMBER() OVER (ORDER BY column_name) AS row_num, column_name FROM table_name;
This query generates a result set that includes a unique row number for each row in the table. The row number is assigned based on the order of the column_name column.
66. What is a transaction in SQL, and how do you ensure data consistency during a transaction?
- A transaction in SQL is a sequence of operations that must be performed together as a single unit of work.
- Transactions ensure the integrity of the database by guaranteeing that all operations are completed successfully or that none of them are executed at all.
- To ensure data consistency during a transaction, you can use the ACID properties:
- Atomicity: All operations in the transaction must complete successfully, or none of them will be executed.
- Consistency: The database must be in a valid state before and after the transaction.
- Isolation: Transactions must be isolated from each other to prevent interference.
- Durability: Once a transaction is committed, its changes must be permanent and survive any system failure.
67. How do you use the LEAD() and LAG() functions in SQL, and what do they do?
- The LAG() and LEAD() functions are window functions in SQL that enable access to previous or subsequent rows within the same result set. • The LAG() function allows you to access data from the previous row, while the LEAD() function allows you to access data from the next row.
Both functions take three arguments:
- The first argument is the value to be returned.
- The second argument is the offset, which specifies the number of rows to move forward or backward.
- The third argument is the default value to be returned if there is no row to access. • Examples:
- SELECT LAG(column_name, 1, 0) OVER (ORDER BY column_name) AS prev_value FROM table_name;
- SELECT LEAD(column_name, 1, 0) OVER (ORDER BY column_name) AS next_value FROM table_name;
68. What is a recursive query in SQL, and how do you use it to retrieve hierarchical data from a table?
- A recursive query in SQL is a query that refers to its own output as a subquery, typically to retrieve hierarchical data from a table.
Recursive queries use the WITH RECURSIVE syntax and consist of two parts:
- The first part defines the base case, which is the starting point of the recursion.
- The second part defines the recursive case, which is the repeated action that builds on the previous result.
Examples:
- WITH RECURSIVE cte AS ( SELECT id, parent_id, name FROM table_name WHERE parent_id IS NULL UNION ALL SELECT t.id, t.parent_id, t.name FROM table_name t INNER JOIN cte ON t.parent_id = cte.id ) SELECT * FROM cte;
- This query retrieves hierarchical data from a table with a parent-child relationship.
69. How do you use the DISTINCT keyword in SQL, and what does it do?
The DISTINCT keyword is used in SQL to remove duplicates from a result set. It returns only unique values for the specified column(s).
Example:
| SELECT DISTINCT department_id FROM employees; |
In this example, the DISTINCT keyword is used to retrieve a list of all the unique department IDs from the employees table.
70. What is the difference between a correlated subquery and a nested subquery in SQL?
- A subquery in SQL is a query nested within another query.
- A correlated subquery is a subquery that depends on the outer query for its values.
- A nested subquery is a subquery that is independent of the outer query and can be executed on its own.
- Correlated subqueries are generally slower than nested subqueries because they must be executed multiple times, once for each row returned by the outer query.
- Example of a correlated subquery:
-
- SELECT column_name FROM table_name t1 WHERE column_name = (SELECT MAX(column_name) FROM table_name t2 WHERE t1.id = t2.id); • Example of a nested subquery:
- SELECT column_name FROM table_name WHERE id IN (SELECT id FROM table_name WHERE column_name = ‘value’);
71. How do you use the FOR XML statement in SQL, and what does it do?
- The FOR XML statement in SQL is used to generate XML output from a query result. • It enables you to retrieve data in a structured format that can be easily consumed by other applications.
- The FOR XML statement can be used with the SELECT statement, and it has several modes:
-
- RAW: Generates a single XML element for each row in the result set.
- AUTO: Generates a nested XML structure that represents the relationships between the tables.
- PATH: Enables you to define the XML structure explicitly by specifying the element and attribute names. • Example:
- SELECT column_name FROM table_name FOR XML RAW(‘row’), ELEMENTS;
- This query generates XML output where each row is represented by a <row> element. The ELEMENTS option specifies that the output should include element tags.
72. What is a materialized view in SQL, and how is it different from a regular view?
- A materialized view in SQL is a database object that stores the result of a query as a physical table.
- It differs from a regular view as a regular view does not store the result set in a table.
- Materialized views are used to improve the performance of complex queries by pre-computing expensive joins and aggregations.
73. How do you use the EXISTS keyword in SQL, and what does it do?
The EXISTS keyword is used in SQL to check for the existence of data in another table. It returns a Boolean value (true or false) based on whether the subquery returns any rows.
Example:
| SELECT * FROM employees WHERE EXISTS (SELECT * FROM departments WHERE departments.department_id = employees.department_id); |
In this example, the EXISTS keyword is used to retrieve all the employees who belong to a department. The subquery checks whether there are any rows in the departments table that match the department ID of each employee.
74. What is the difference between the DISTINCT and GROUP BY keywords in SQL, and when would you use one over the other?
- The DISTINCT keyword in SQL is used to remove duplicate rows from a result set.
- The GROUP BY keyword is used to group rows that have the same values in a particular column or set of columns.
- The main difference between the two is that DISTINCT is used to select unique values from a single column, while GROUP BY is used to group and aggregate data across multiple columns.
75. How do you use the WINDOW function in SQL, and what does it do?
- The WINDOW function in SQL is used to perform calculations across a set of rows in a table.
- It allows you to partition the data by one or more columns and then perform calculations within each partition.
- The WINDOW function is used in conjunction with the OVER clause to define the window or range of rows over which the calculation is performed.
76. What is a cross-database query in SQL, and how do you use it to retrieve data from multiple databases?
- A cross-database query in SQL is a query that retrieves data from tables in multiple databases.
- It is used to combine data from multiple databases into a single result set.
- To perform a cross-database query, you need to fully qualify the table names with the database name and schema name, and use the fully qualified table names in your query.
77. How do you use the RANK() function in SQL, and what does it do?
- The RANK() function in SQL is used to assign a rank to each row within a result set based on the values in one or more columns.
- It is used to return the ranking of each row, with the highest value receiving a rank of 1.
- The RANK() function can be used with the ORDER BY clause to specify the order in which the values are ranked.
78. What is a recursive common table expression in SQL, and how do you use it to retrieve hierarchical data from a table?
- A recursive common table expression (CTE) in SQL is used to retrieve hierarchical data from a table that has a self-referencing relationship.
- It is a temporary result set that is defined within a SELECT, INSERT, UPDATE, or DELETE statement.
- A recursive CTE is defined using a UNION ALL operator that references the CTE itself, and is terminated by a SELECT statement that does not reference the CTE.
79. How do you use the PIVOT operator to transpose rows into columns in SQL?
- The PIVOT operator in SQL is used to transpose rows into columns in a result set based on the values in a particular column.
- It is used to summarize data by grouping it according to a set of categories.
- The PIVOT operator is used in conjunction with the aggregate functions and the GROUP BY clause to perform the transposition.
80. What is a database trigger in SQL, and how is it different from a regular trigger?
- A database trigger in SQL is a special type of stored procedure that is automatically executed in response to certain database events, such as INSERT, UPDATE, or DELETE operations.
- It is different from a regular trigger in that it is executed in response to database events, rather than programmatic events.
- Database triggers are used to enforce business rules, validate data, and maintain data integrity.
81. How do you use the TRANSACTION statement in SQL, and what does it do?
- The TRANSACTION statement in SQL is used to group a set of SQL statements into a single transaction that can be committed or rolled back as a unit.
- It is used to ensure that all changes to the database are made as a single, atomic operation.
- The TRANSACTION statement is used in conjunction with the COMMIT and ROLLBACK statements to commit or roll back the transaction.
82. What is a dynamic SQL query in SQL, and how do you use it to construct queries on the fly?
- A dynamic SQL query in SQL is a query that is constructed at runtime, rather than being hard-coded into the program.
- It is used to build queries on the fly based on runtime conditions or user input.
- Dynamic SQL can be constructed using string concatenation, prepared statements, or stored procedures.
83. How do you use the SEQUENCE statement in SQL, and what does it do?
- The SEQUENCE statement in SQL is used to create a sequence object that can be used to generate a sequence of unique values.
- It is used to generate primary key values for tables or other values that require a unique identifier.
- The SEQUENCE statement is used in conjunction with the NEXT VALUE FOR function to generate the next value in the sequence.
84. What is a foreign key in SQL, and how do you use it to establish a relationship between two tables?
- A foreign key in SQL is a column or set of columns that references the primary key of another table, creating a relationship between the two tables.
- It is used to enforce referential integrity, ensuring that data in one table is consistent with data in another table.
- To establish a relationship between two tables using a foreign key, the foreign key column is defined in the child table, and it references the primary key column in the parent table.
85. How do you use the GROUP BY keyword in SQL, and what does it do?
- The GROUP BY keyword in SQL is used to group rows in a result set based on the values in one or more columns.
- It is used in conjunction with aggregate functions, such as SUM, COUNT, AVG, and MAX, to summarize data.
- The GROUP BY keyword is used to create summary reports, such as total sales by region or average salary by department.
86. What is a common table expression (CTE) in SQL, and how do you use it to simplify complex queries?
- A common table expression (CTE) in SQL is a temporary result set that is defined within a SELECT, INSERT, UPDATE, or DELETE statement.
- It is used to simplify complex queries by breaking them down into smaller, more manageable parts.
- A CTE is defined using the WITH clause, and it can be used as a subquery in the main query, making it easier to read and understand.
87. What is normalization in SQL, and why is it important in database design?
- Normalization is the process of organizing data in a database to reduce redundancy and dependency.
- It is important in database design because it helps to ensure data consistency, improves data integrity, and makes it easier to maintain and update the database.
- Normalization involves breaking down data into smaller, more manageable tables and creating relationships between them using primary keys and foreign keys.
88. What is a self join in SQL, and how do you use it to combine data from the same table?
- A self join in SQL is a join where a table is joined to itself.
- It is used to combine data from the same table when the table contains hierarchical or recursive data.
- To perform a self join, the table is given two different aliases, and a join condition is defined that links the aliases based on a common column.
89. How do you use the HAVING keyword in SQL, and what does it do?
- The HAVING keyword in SQL is used to filter groups in a result set based on a condition that applies to the group as a whole.
- It is used in conjunction with the GROUP BY keyword and aggregate functions, such as SUM, COUNT, AVG, and MAX.
- The HAVING keyword is used to create more complex filters than can be achieved with the WHERE clause, such as finding groups with a total sales value greater than a certain amount.
90. What is the difference between a primary key and a unique key in SQL, and when would you use one over the other?
- A primary key in SQL is a column or set of columns that uniquely identifies each row in a table. It is used to enforce data integrity and ensure that each row in the table is unique.
- A unique key in SQL is a column or set of columns that have unique values, but they are not necessarily used to identify each row in the table.
- You would use a primary key when you need to identify each row in the table uniquely, and you would use a unique key when you need to ensure that a column or set of columns has unique values, but they do not necessarily need to identify each row uniquely.
91. How do you use the ORDER BY keyword in SQL, and what does it do?
- The ORDER BY keyword in SQL is used to sort the result set of a query in ascending or descending order based on one or more columns.
- It is used to make it easier to read and analyze the data in the result set.
- The ORDER BY keyword can be used with any SELECT statement, and it can be used to sort the data by one or more columns in ascending or descending order.
92. What is a cursor in SQL, and how do you use it to manipulate data in a table?
- A cursor in SQL is a database object used to manipulate data in a result set one row at a time.
- It is used to iterate over the rows in a result set and perform operations on them.
- Cursors are typically used in stored procedures and other programming constructs that require iterative access to data in a table.
93. How do you use the TOP keyword in SQL, and what does it do?
- The TOP keyword in SQL is used to limit the number of rows returned by a SELECT statement.
- It is used to return the first n rows of a result set, where n is a specified number.
- The TOP keyword can be used with any SELECT statement, and it can be used to return the first n rows in ascending or descending order.
94. What is a stored procedure in SQL, and how do you create and use one?
- A stored procedure in SQL is a set of SQL statements that are stored in the database and can be executed as a single unit.
- It is used to encapsulate complex SQL logic and make it easier to manage and reuse.
- To create a stored procedure in SQL, you use the CREATE PROCEDURE statement, and to execute a stored procedure, you use the EXECUTE statement.
95. How do you use the LIKE keyword in SQL, and what does it do?
- The LIKE keyword in SQL is used to search for a pattern in a column of text data.
- It is used to perform partial matches on character strings, using wildcard characters such as % and _.
- The LIKE keyword is used in conjunction with the WHERE clause and can be used to search for specific patterns in a column of text data.
96. How do you use the TRUNCATE statement in SQL, and what is the difference between it and the DELETE statement?
- The TRUNCATE statement in SQL is used to remove all rows from a table without logging individual row deletions.
- It is used to quickly remove all data from a table when you do not need to keep a record of the individual rows that were deleted.
- The TRUNCATE statement is faster than the DELETE statement because it does not log individual row deletions, but it cannot be used with a WHERE clause.
- The DELETE statement is used to remove one or more rows from a table, and it can be used with a WHERE clause to specify which rows to delete. It logs each row deletion, which can make it slower than TRUNCATE.
97. What is a stored procedure in SQL, and how do you create one?
- A stored procedure is a set of SQL statements that are stored in the database and can be executed multiple times.
- It can accept input parameters and return output parameters.
- Use the CREATE PROCEDURE statement to create a new stored procedure, followed by
- the SQL statements you want to include in the procedure.
98. How do you use the DISTINCT keyword in SQL, and what does it do?
- The DISTINCT keyword is used to retrieve unique values from a column.
- It eliminates duplicate rows from the result set.
- Use the DISTINCT keyword after the SELECT statement, followed by the column name(s) you want to retrieve unique values from.
99. How do you use the MERGE statement in SQL, and what does it do?
- The MERGE statement in SQL is used to combine INSERT, UPDATE, and DELETE operations into a single transaction.
- It is used to synchronize two tables, by updating or inserting records in the target table based on the values in the source table.
- The MERGE statement works by comparing the values in the join columns of the source and target tables, and performing the appropriate action based on the match.
100. How do you use the OFFSET keyword in SQL, and what does it do?
- The OFFSET keyword is used to specify the number of rows to skip before returning the result set.
- Use the OFFSET keyword after the LIMIT keyword, followed by the number of rows to skip.
The Top 100 SQL Interview Questions and Answers provide a comprehensive guide for job seekers to prepare for SQL interviews, covering various aspects of SQL programming and database management. To acquire further knowledge, be sure to follow us at freshersnow.com.