
| Join Telegram |  |
| Join Whatsapp Groups |  |
SQLite Interview Questions and Answers: If you’re preparing for an upcoming SQLite interview, having a deep understanding of the features and functionality of this open-source, serverless relational database management system is essential. Not only is SQLite widely used in various applications, but it’s also known for its small size, speed, simplicity, and reliability. That’s why we’ve compiled a list of the Latest SQLite Interview Questions, including SQLite Technical Interview Questions that cater to both beginners and experienced professionals.
★★ Latest Technical Interview Questions ★★
SQLite Technical Interview Questions
By going through our collection of Top 100 SQLite Interview Questions and Answers, you can boost your chances of excelling in your upcoming technical interview.
Top 100 SQLite Interview Questions and Answers
Explore this section to familiarize yourself with the SQLite Interview Questions designed for freshers and experienced as well.
1. What is SQLite and how is it different from other databases?
- SQLite is an open-source, lightweight, serverless relational database management system.
- It differs from other databases in that it does not require a separate server process and can be embedded directly into an application.
2. Can you explain the architecture of SQLite?
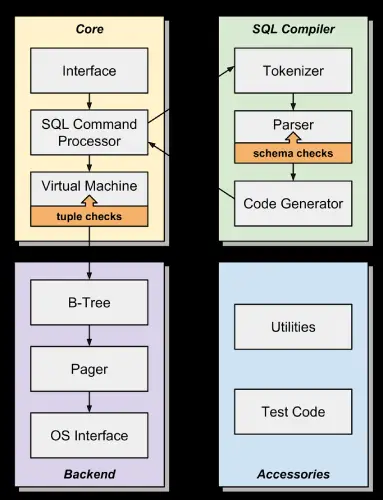
- The architecture of SQLite is based on a library that provides the SQL engine and database functionality.
- It uses a file-based approach to store data, with each database represented by a single file on disk.
- SQLite supports multiple concurrent transactions and has a locking mechanism to ensure data consistency.
3. What are the advantages of using SQLite?
- SQLite is lightweight, fast, and easy to use.
- It has a small memory footprint and requires minimal setup and administration.
- It is ACID-compliant and supports transactions, ensuring data consistency.
- It has cross-platform compatibility and can be used on various operating systems and programming languages.
4. What are the disadvantages of using SQLite?
- SQLite does not scale well for high-concurrency, high-volume applications.
- It does not support user management and access control, making it unsuitable for large-scale, multi-user environments.
- It has limited support for complex data types and advanced SQL features.
5. How do you install SQLite on your system?
- For Windows, you can download the SQLite command-line shell program from the official website and run the installer.
- For Linux, SQLite is often available in the distribution’s package repository, and can be installed using the package manager.
- For macOS, you can use Homebrew or MacPorts to install SQLite.
6. What is the difference between a VIEW and a TABLE in SQLite?
| Factor | VIEW | TABLE |
|---|---|---|
| Definition | A virtual table created from a SELECT statement | A physical table with rows and columns |
| Storage | Does not store any data, but rather displays data from underlying tables | Stores data on disk or in memory |
| Modifiability | Cannot be modified directly, but can be used to update the underlying tables | Can be modified directly using SQL commands such as INSERT, UPDATE, DELETE |
| Schema | Does not have its own schema, but rather inherits schema from underlying tables | Has its own schema defined at the time of creation |
| Performance | Can improve performance by providing a simplified or aggregated view of data | Performance can be impacted by the size and complexity of data stored in the table |
| Indexing | Cannot have indexes, but can be used in queries that utilize indexes on underlying tables | Can have indexes defined to improve query performance |
| Storage size | Does not consume any storage space as it does not store any data | Consumes storage space based on the number of rows and columns and the size of data in each column |
7. What are the data types supported by SQLite?
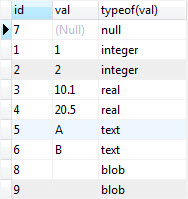
- NULL
- INTEGER
- REAL
- TEXT
- BLOB
8. How do you create a table in SQLite?
To create a table in SQLite, you can use the following syntax:
| CREATE TABLE table_name ( column1 datatype PRIMARY KEY, column2 datatype NOT NULL, column3 datatype DEFAULT 0, … ); |
Where:
- table_name is the name of the table you want to create.
- column1, column2, column3, etc. are the names of the columns in the table.
- datatype is the data type of each column.
- PRIMARY KEY indicates that this column is the primary key for the table.
- NOT NULL indicates that this column cannot contain NULL values.
- DEFAULT specifies a default value for the column.
9. What is the syntax for inserting data into a table in SQLite?
To insert data into a table in SQLite, you can use the following syntax:
| INSERT INTO table_name (column1, column2, column3, …) VALUES (value1, value2, value3, …); |
Where:
- table_name is the name of the table you want to insert data into.
- column1, column2, column3, etc. are the names of the columns you want to insert data into.
- value1, value2, value3, etc. are the corresponding values you want to insert into each column.
10. How do you update data in a table in SQLite?
To update data in a table in SQLite, you can use the following syntax:
| UPDATE table_name SET column1 = value1, column2 = value2, … WHERE condition; |
Where:
- table_name is the name of the table you want to update data in.
- column1, column2, etc. are the names of the columns you want to update.
- value1, value2, etc. are the new values you want to set for each column.
- condition specifies which rows to update. Only rows that satisfy the condition will be updated.
11. How do you delete data from a table in SQLite?
- To delete data from a table in SQLite, you can use the DELETE statement followed by the name of the table.
- The DELETE statement can also be combined with the WHERE clause to specify which rows to delete based on certain conditions.
12. Can you explain the difference between NULL and NOT NULL in SQLite?
- In SQLite, NULL means the absence of a value or the value is unknown, while NOT NULL means that a value must be present.
- When creating a table in SQLite, you can specify whether a column can have NULL values or not using the NULL and NOT NULL constraints respectively.
13. What is the difference between INTEGER and TEXT in SQLite?
- In SQLite, INTEGER is a numeric data type that can store whole numbers while TEXT is a character data type that can store alphanumeric data.
- INTEGER data type uses 1, 2, 3, 4, 6, or 8 bytes of storage space depending on the magnitude of the value while TEXT data type uses as much storage space as required to store the data.
14. How do you use the SELECT statement in SQLite?
- The SELECT statement is used to retrieve data from one or more tables in SQLite.
- To use the SELECT statement, you need to specify the columns you want to retrieve data from and the table name using the SELECT and FROM keywords respectively.
- You can also use other keywords like WHERE, ORDER BY, and GROUP BY to filter and sort the data.
15. Can you explain the difference between a LEFT JOIN and an INNER JOIN in SQLite?
| Factor | LEFT JOIN | INNER JOIN |
|---|---|---|
| Definition | Returns all rows from the left table and matching rows from the right table | Returns only the matching rows from both tables based on the specified join condition |
| Syntax | SELECT … FROM table1 LEFT JOIN table2 ON condition | SELECT … FROM table1 INNER JOIN table2 ON condition |
| Matching rows | Returns all rows from the left table and matching rows from the right table | Returns only the matching rows from both tables |
| Non-matching rows | Returns NULL values for columns from the right table if there is no match | Does not return non-matching rows |
| Result set size | Can be larger than either input table | Can be smaller than either input table |
| Performance | Can be slower than INNER JOIN because it requires a larger result set | Can be faster than LEFT JOIN because it returns a smaller result set |
| Common use cases | Returning all rows from the left table and matching rows from the right table, and handling missing data in the right table | Retrieving data from two tables based on a common column |
| Example query | SELECT * FROM employees LEFT JOIN departments ON employees.department_id = departments.department_id | SELECT * FROM customers INNER JOIN orders ON customers.customer_id = orders.customer_id |
16. How do you use the GROUP BY clause in SQLite?
- The GROUP BY clause is used to group rows based on a specific column or expression.
- It is used in combination with aggregate functions like SUM, COUNT, MAX, MIN, and AVG to perform calculations on the grouped data.
- For example: SELECT column1, SUM(column2) FROM table_name GROUP BY column1;
17. How do you use the HAVING clause in SQLite?
- The HAVING clause is used to filter data based on a condition applied to a group.
- It is used in combination with the GROUP BY clause and aggregate functions.
- For example: SELECT column1, SUM(column2) FROM table_name GROUP BY column1 HAVING SUM(column2) > 100;
18. How do you use the ORDER BY clause in SQLite?
- The ORDER BY clause is used to sort the result set based on one or more columns.
- It can sort the data in either ascending or descending order.
- For example: SELECT column1, column2 FROM table_name ORDER BY column1 ASC, column2 DESC;
19. Can you explain the difference between ascending and descending order in SQLite?
- Ascending order sorts the data in ascending order, with the lowest value first.
- Descending order sorts the data in descending order, with the highest value first.
20. What is the difference between a temporary table and a permanent table in SQLite?
| Factor | Temporary Table | Permanent Table |
|---|---|---|
| Definition | A table that exists for the duration of a session or transaction | A table that persists even after the session or transaction ends |
| Creation syntax | CREATE TEMPORARY TABLE table_name (column1 data_type, column2 data_type, …); | CREATE TABLE table_name (column1 data_type, column2 data_type, …); |
| Visibility | Visible only to the current session or transaction | Visible to all sessions and transactions |
| Data persistence | Data is lost when the session or transaction ends | Data persists even after the session or transaction ends |
| Indexing | Indexes can be created on temporary tables | Indexes can be created on permanent tables |
| Naming conflicts | Temporary table names are not visible to other sessions or transactions | Permanent table names are globally visible and can cause naming conflicts |
| Backup and restore | Temporary tables cannot be backed up or restored | Permanent tables can be backed up and restored |
| Common use cases | Temporary storage for intermediate results, temporary tables in complex queries or reports, session-specific data | Storing data that needs to persist across multiple sessions or transactions, primary data storage |
| Example queries | CREATE TEMPORARY TABLE temp_table AS SELECT * FROM employees WHERE salary > 50000; | CREATE TABLE permanent_table (id INTEGER PRIMARY KEY, name TEXT, age INTEGER); |
21. How do you create a view in SQLite?
- A view is a virtual table that is based on the result of a SELECT statement.
- It can be created using the CREATE VIEW statement.
- For example: CREATE VIEW view_name AS SELECT column1, column2 FROM table_name;
22. Can you explain the difference between a view and a table in SQLite?
- A table is a physical storage structure that contains data, while a view is a virtual table that is based on the result of a SELECT statement.
- Views do not store data, but instead retrieve it from the underlying tables on which they are based.
23. How do you update data in a view in SQLite?
- Data cannot be updated directly in a view in SQLite.
- To update data, you must modify the underlying table(s) on which the view is based.
24. How do you delete data from a view in SQLite?
- Data cannot be deleted directly from a view in SQLite.
- To delete data, you must delete it from the underlying table(s) on which the view is based.
25. How do you use subqueries in SQLite?
- A subquery is a query that is embedded inside another query.
- It can be used in various parts of a SQL statement, such as the WHERE clause, FROM clause, or SELECT clause.
- For example: SELECT column1 FROM table_name WHERE column2 IN (SELECT column3 FROM another_table);
26. Can you explain the difference between a stored procedure and a trigger in SQLite?
- A stored procedure is a set of SQL statements that can be executed repeatedly.
- A trigger is a special type of stored procedure that automatically executes in response to certain events, such as an INSERT, UPDATE, or DELETE operation on a table.
27. What is a user-defined function in SQLite?
A user-defined function in SQLite is a custom function that is created by the user and can be called from an SQL statement. It can accept one or more arguments and return a value.
28. How do you create a user-defined function in SQLite?
To create a user-defined function in SQLite, you can use the following syntax:
| CREATE FUNCTION function_name(argument1, argument2, …) RETURNS datatype AS BEGIN — Function body END; |
Where:
- function_name is the name of the function you want to create.
- argument1, argument2, etc. are the arguments that the function will accept.
- datatype is the data type of the value that the function will return.
- The BEGIN and END statements contain the body of the function.
29. Can you explain the difference between a scalar and aggregate function in SQLite?
- A scalar function in SQLite is a function that operates on a single value and returns a single value.
- An aggregate function in SQLite is a function that operates on a set of values and returns a single value.
30. What is the difference between a transaction and a savepoint in SQLite?
| Factor | Transaction | Savepoint |
|---|---|---|
| Definition | A sequence of SQL statements that are executed as a single unit of work | A point within a transaction that can be rolled back to in case of errors |
| Syntax | BEGIN TRANSACTION; … SQL statements …; COMMIT; | SAVEPOINT savepoint_name; … SQL statements …; ROLLBACK TO savepoint_name; |
| Rollback | Rolls back all changes made in the transaction | Rolls back only changes made after the savepoint was created |
| Commit | Commits all changes made in the transaction | Commits changes made after the savepoint was created |
| Nested | Transactions can be nested but each must be committed or rolled back separately | Savepoints can be nested and rolled back to individually |
| Isolation | Transactions are typically executed with the highest level of isolation, meaning that concurrent transactions do not interfere with each other | Savepoints are not typically used for isolation purposes |
| Common use cases | Ensuring data consistency, maintaining data integrity, and handling errors | Incrementally building up a transaction and rolling back to intermediate points if an error occurs |
| Example queries | BEGIN TRANSACTION; … SQL statements …; COMMIT; | SAVEPOINT sp1; … SQL statements …; SAVEPOINT sp2; … SQL statements …; ROLLBACK TO sp1; COMMIT; |
31. Where pattern can include the following wildcard characters:
- % (percent sign) represents zero, one, or multiple characters.
- _ (underscore) represents a single character.
32. How do you use the BETWEEN operator in SQLite?
The BETWEEN operator is used to filter the results of an SQL query based on a range of values. The syntax is as follows:
| SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2; |
Where value1 and value2 specify the range of values to filter by.
33. How do you use the IN operator in SQLite?
The IN operator is used to filter the results of an SQL query based on a specific set of values. The syntax is as follows:
| SELECT column_name(s) FROM table_name WHERE column_name IN (value1, value2, …); |
Where value1, value2, etc. are the specific values to filter by.
34. How do you use the UNION operator in SQLite?
The UNION operator is used to combine the results of two or more SELECT statements into a single result set. The syntax is as follows:
| SELECT column_name(s) FROM table1 UNION SELECT column_name(s) FROM table2; Where table1 and table2 are the names of the tables to combine. |
35. How do you use the JOIN clause in SQLite?
The JOIN clause is used to combine rows from two or more tables based on a related column between them. The syntax is as follows:
| SELECT column_name(s) FROM table1 JOIN table2 ON table1.column_name = table2.column_name; |
Where table1 and table2 are the names of the tables to join, and column_name is the related column between them.
36. What is the difference between an inner join and an outer join in SQLite?
- An inner join in SQLite returns only the rows that have matching values in both tables being joined.
- An outer join in SQLite returns all the rows from one table and the matching rows from the other table being joined. If there are no matching rows, the result will contain NULL values. There are three types of outer joins in SQLite:
- LEFT OUTER JOIN: returns all the rows from the left table and the matching rows from the right table.
- RIGHT OUTER JOIN: returns all the rows from the right table and the matching rows from the left table.
- FULL OUTER JOIN: returns all the rows from both tables and the matching rows. If there are no matching rows, the result will contain NULL values. However, SQLite does not support FULL OUTER JOIN directly, but it can be emulated using UNION and LEFT OUTER JOIN/RIGHT OUTER JOIN.
37. Can you explain the difference between a clustered and non-clustered index in SQLite?
- In SQLite, a clustered index is a type of index where the data rows in a table are physically sorted based on the indexed column, while a non-clustered index is a separate structure that stores the index data separately from the table data.
- A table can only have one clustered index, while it can have multiple non-clustered indexes.
- Clustered indexes are generally faster for retrieving large amounts of data, while non-clustered indexes are more suitable for searching and filtering specific values.
38. Can you explain the difference between the INTEGER and REAL data types in SQLite?
| Factor | INTEGER | REAL |
|---|---|---|
| Definition | A whole number data type | A floating-point number data type |
| Storage size | Uses 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value | Uses 8 bytes for all values |
| Range of values | -9223372036854775808 to +9223372036854775807 | Approximately ± 1.7 x 10^308 |
| Precision | Exact | Rounded to approximately 15 decimal digits |
| Arithmetic operators | Supports all standard integer arithmetic operators | Supports all standard floating-point arithmetic operators |
| Comparison operators | Supports all standard integer comparison operators | Supports all standard floating-point comparison operators |
| Common use cases | Storing discrete numerical values, such as IDs or counts | Storing continuous numerical values, such as measurements or currency amounts |
| Example values | 42, -123456789, 0, 9223372036854775807 | 3.14, -1.0, 100.5, 1.23e-5 |
| Example queries | SELECT COUNT(*) FROM my_table WHERE my_column > 100; | SELECT AVG(price) FROM products WHERE category = ‘Electronics’; |
39. How do you optimize a SQLite database?
- To optimize a SQLite database, you can use the VACUUM command to rebuild the database file and free up unused space.
- You can also use the ANALYZE command to update the statistics used by the query optimizer, and the PRAGMA command to set various database parameters for better performance.
40. Can you explain the difference between a database and a schema in SQLite?
- In SQLite, a database is a file that contains one or more tables, while a schema is a logical container that holds the database objects like tables, indexes, and triggers.
- Unlike other database management systems, SQLite does not have a concept of schemas, so all the database objects are stored in the same database file.
41. Can you explain the difference between correlated and uncorrelated subqueries in SQLite?
- An uncorrelated subquery in SQLite can be executed independently of the outer query, and it returns a single value to the outer query.
- A correlated subquery in SQLite is executed for each row of the outer query and it is dependent on the outer query. It uses the values from the outer query to produce a result for the inner query.
42. How do you use the EXISTS operator in SQLite?
The EXISTS operator in SQLite is used to check whether a subquery returns any rows or not.
The syntax for using EXISTS operator is:
| SELECT column_name(s) FROM table_name WHERE EXISTS (subquery); |
43. How do you use the NOT operator in SQLite?
The NOT operator in SQLite is used to negate a boolean expression.
The syntax for using NOT operator is:
| SELECT column_name(s) FROM table_name WHERE NOT boolean_expression; |
44. How do you use the CASE statement in SQLite?
The CASE statement in SQLite is used to perform conditional logic in SQL queries. The syntax for using CASE statement is:
| SELECT column_name, CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 … ELSE result END FROM table_name; |
45. How do you use the COALESCE function in SQLite?
The COALESCE function in SQLite is used to return the first non-null value in a list of expressions. The syntax for using COALESCE function is:
| SELECT COALESCE(expression1, expression2, …, expression_n) FROM table_name; |
46. How do you use the CAST function in SQLite?
The CAST function in SQLite is used to convert a value of one data type to another data type. The syntax for using CAST function is:
| SELECT CAST(expression AS data_type) FROM table_name; |
47. Can you explain the difference between implicit and explicit data type conversion in SQLite?
- Implicit data type conversion in SQLite is done automatically by the database system when a value of one data type is used in a context that requires a different data type.
- Explicit data type conversion in SQLite is done using the CAST function or other conversion functions to convert a value from one data type to another.
48. How do you use the COUNT function in SQLite?
The COUNT function in SQLite is used to count the number of rows that match a certain condition in a table.
The syntax for using COUNT function is:
| SELECT COUNT(*) FROM table_name WHERE condition; |
49. How do you use the AVG function in SQLite?
The AVG function in SQLite is used to calculate the average value of a numeric column in a table The syntax for using AVG function is:
| SELECT AVG(column_name) FROM table_name; |
50. How do you use the MAX and MIN functions in SQLite?
The MAX function in SQLite is used to find the highest value in a column of a table, while the MIN function is used to find the lowest value in a column of a table. The syntax for using MAX and MIN functions is:
| SELECT MAX(column_name) FROM table_name; |
| SELECT MIN(column_name) FROM table_name; |
51. How do you use the SUM function in SQLite?
- The SUM function in SQLite is used to find the sum of all values in a column of a table.
- To use the SUM function, you need to specify the column name as an argument.
- For example, to find the sum of values in the “Price” column of the “Products” table, the query would be: SELECT SUM(Price) FROM Products;
52. What is the difference between a primary key and a unique key in SQLite?
| Factor | Primary Key | Unique Key |
|---|---|---|
| Definition | A column or combination of columns that uniquely identifies each row in a table | A column or combination of columns that contains unique values |
| Number of keys | Only one primary key is allowed per table | Multiple unique keys are allowed per table |
| Null values | Primary key columns cannot contain NULL values | Unique key columns can contain NULL values (with the exception of the UNIQUE constraint on the combination of columns) |
| Index creation | A primary key constraint automatically creates a unique index on the key columns | A unique constraint automatically creates a unique index on the key columns |
| Usage | Primary keys are used to enforce referential integrity, join tables, and ensure uniqueness | Unique keys are used to ensure uniqueness and improve query performance |
| Query optimization | Primary keys are automatically indexed, making queries faster | Unique keys are automatically indexed, making queries faster |
| Altering constraints | Primary key constraints can be altered, but the new key columns must not contain duplicates or NULL values | Unique constraints can be altered, but the new key columns must not contain duplicates (with the exception of the UNIQUE constraint on the combination of columns) |
| Example table syntax | CREATE TABLE my_table (id INTEGER PRIMARY KEY, name TEXT, email TEXT); | CREATE TABLE my_table (id INTEGER, name TEXT, email TEXT, UNIQUE (email)); |
| Example queries | SELECT * FROM my_table WHERE id = 123; | SELECT * FROM my_table WHERE email = ‘example@example.com’; |
53. How do you use the DATE and TIME functions in SQLite?
- The DATE and TIME functions in SQLite are used to retrieve the current date and time respectively.
- To use the DATE function, the query would be: SELECT DATE(‘now’);
- To use the TIME function, the query would be: SELECT TIME(‘now’);
54. How do you optimize the performance of a SQLite database?
To optimize the performance of a SQLite database, you can consider the following techniques:
- Use indexes on columns that are frequently used in WHERE or JOIN clauses.
- Use the EXPLAIN QUERY PLAN command to analyze and optimize queries.
- Avoid using wildcard characters at the beginning of LIKE clauses.
- Use transactions to group multiple queries into a single atomic operation.
55. Can you explain the difference between a view and a table in SQLite?
- A table in SQLite is a collection of data stored in a structured format with a fixed schema.
- A view in SQLite is a virtual table that is created based on the result of a SELECT statement.
- The main difference between a view and a table is that a view does not store data physically, but rather presents data from one or more tables.
56. What is a trigger in SQLite? How is it used?
- A trigger in SQLite is a special type of stored procedure that is automatically executed in response to certain database events, such as INSERT, UPDATE, or DELETE.
- Triggers are used to enforce business rules or perform complex data validations.
- The trigger code is executed before or after the database event, and can modify the data being processed.
57. How do you encrypt a SQLite database?
- To encrypt a SQLite database, you need to use an encryption extension or library, such as SQLiteCrypt, SEE, or SQLCipher.
- You can create an encrypted database by specifying the encryption key when opening the database connection.
- Once the database is encrypted, all data is stored in an encrypted format, and can only be accessed with the correct encryption key.
58. What are the different types of collations in SQLite?
- A collation in SQLite is a set of rules that determine how strings are compared and sorted.
- There are three types of collations in SQLite: BINARY, NOCASE, and RTRIM.
- BINARY collation is case-sensitive and compares strings byte by byte.
- NOCASE collation is case-insensitive and compares strings without regard to case.
- RTRIM collation is case-insensitive and compares strings after removing trailing whitespace.
59. How can you migrate data from one SQLite database to another?
To migrate data from one SQLite database to another, you can use the following steps:
- Export the data from the source database to a CSV or SQL file.
- Create the target database and the necessary tables and columns.
- Import the data from the CSV or SQL file into the target database.
60. Can you explain the role of PRAGMA in SQLite?
PRAGMA is a keyword used in SQLite to set or query certain runtime parameters or compile-time options for the database connection. It is used to control various aspects of the behavior of SQLite.
The role of PRAGMA in SQLite is to:
- Set or retrieve various database-specific settings such as the default synchronization mode, cache size, and page size.
- Set or retrieve the schema version for the database.
- Query the status and schema of a database object such as a table, index, or trigger.
- Provide diagnostic information about the database connection and schema.
- Manage the behavior of the SQLite optimizer.
- Control the behavior of certain SQL statements, such as the VACUUM command.
61. Can you explain the difference between a clustered and non-clustered index in SQLite?
A clustered index determines the physical order of data in a table, while a non-clustered index is a separate structure that stores a copy of the indexed data.
62. How do you drop an index in SQLite?
To drop an index in SQLite, you can use the DROP INDEX statement followed by the name of the index you want to drop.
63. What is the difference between the COUNT(*) and COUNT(column_name) functions in SQLite?
| Factor | COUNT(*) | COUNT(column_name) |
|---|---|---|
| Definition | Counts the total number of rows in a table | Counts the number of non-null values in the specified column |
| NULL values | Includes rows with NULL values in the count | Excludes rows with NULL values in the count |
| Performance | Generally slower than COUNT(column_name) because it counts all rows | Generally faster than COUNT(*) because it only counts non-null values |
| Memory usage | Uses more memory than COUNT(column_name) because it counts all rows | Uses less memory than COUNT(*) because it only counts non-null values |
| Usage | Used to count the total number of rows in a table | Used to count the number of non-null values in a column |
| Example syntax | SELECT COUNT(*) FROM my_table; | SELECT COUNT(column_name) FROM my_table; |
| Example result with NULLs | If there are 5 rows and 1 has a NULL value, COUNT(*) would return 5 and COUNT(column_name) would return 4 | If there are 5 rows and 1 has a NULL value, COUNT(*) would return 4 and COUNT(column_name) would return 3 |
64. Can you explain the difference between a database and a schema in SQLite?
In SQLite, there is no concept of a schema. Instead, each database is a self-contained unit that can contain multiple tables, indexes, and other objects.
65. What is a database transaction and how is it used in SQLite?
A database transaction is a sequence of operations performed as a single unit of work that either all succeed or all fail. Transactions in SQLite are used to ensure data consistency and integrity.
66. Can you explain the difference between ACID and BASE in SQLite?
ACID is a set of properties that ensure database transactions are reliable and consistent, while BASE is an alternative approach that prioritizes availability and scalability over consistency.
67. How do you create a trigger in SQLite?
To create a trigger in SQLite, you can use the CREATE TRIGGER statement followed by the name of the trigger, the event that will trigger the trigger, and the action the trigger will perform.
68. What is a trigger action in SQLite?
A trigger action in SQLite is the code that runs when a trigger is fired. Trigger actions can be used to update data, insert new data, or enforce business rules.
69. How do you drop a trigger in SQLite?
To drop a trigger in SQLite, you can use the DROP TRIGGER statement followed by the name of the trigger you want to drop.
70. How do you create a stored procedure in SQLite?
SQLite does not support stored procedures, but you can simulate them using triggers and user-defined functions.
71. Can you explain the difference between a subquery and a JOIN in SQLite?
| Factor | Subquery | JOIN |
|---|---|---|
| Definition | A query within a query | A method to combine rows from two or more tables based on a related column |
| Syntax | Enclosed in parentheses and used as a table or value in the main query | Includes the JOIN keyword, the table name(s), and the ON keyword with the join condition |
| Performance | Generally slower than JOINs because the subquery is executed once for each row in the outer query | Generally faster than subqueries because JOINs are optimized by the query optimizer |
| Complexity | Can be complex and difficult to understand or maintain as the query gets larger | Can become complex, but can be easier to understand and maintain than subqueries |
| Usage | Used to filter, aggregate, or modify data before it is used in the main query | Used to combine data from two or more tables based on a related column |
| Result set | Returns a single value or a set of values that can be used in the main query | Returns a result set that includes columns from both tables |
| Example syntax | SELECT * FROM my_table WHERE column_name IN (SELECT other_column FROM other_table); | SELECT * FROM my_table JOIN other_table ON my_table.column_name = other_table.other_column; |
| Example use case | To filter data based on values from another table | To combine data from two or more related tables |
72. What is the maximum size of a SQLite database?
- The maximum size of a SQLite database is determined by the operating system’s file size limit.
- In most cases, it is 140 terabytes.
73. How do you create an index in SQLite?
Use the CREATE INDEX statement followed by the name of the index, the table name, and the column name(s) to be indexed.
74. What is a foreign key constraint in SQLite? How is it used?
- A foreign key constraint is used to enforce referential integrity between tables.
- It ensures that the values in the specified column(s) of a table match the values in the primary key column(s) of another table.
- Use the FOREIGN KEY clause in the CREATE TABLE statement to define a foreign key constraint.
75. How can you retrieve the last inserted row in a SQLite table?
Use the last_insert_rowid() function to retrieve the ID of the last inserted row.
76. Can you explain the difference between a left join and a right join in SQLite?
- A left join returns all rows from the left table and matching rows from the right table, and NULL values for non-matching rows in the right table.
- A right join returns all rows from the right table and matching rows from the left table, and NULL values for non-matching rows in the left table.
77. How do you check the integrity of a SQLite database?
- Use the PRAGMA integrity_check command to check the integrity of a SQLite database.
- It returns “ok” if the database is structurally sound, and “error” if it contains errors.
78. What is a common table expression (CTE) in SQLite?
- A CTE is a temporary named result set that can be referenced within a SELECT, INSERT, UPDATE, or DELETE statement.
- It is defined using the WITH keyword followed by a name and a SELECT statement.
79. Can you explain the difference between a clustered and non-clustered index in SQLite?
- In SQLite, there is no concept of a clustered index.
- However, SQLite supports the creation of non-clustered indexes on one or more columns of a table.
- A non-clustered index contains a copy of the indexed columns and a pointer to the corresponding row in the table.
- When querying data, the non-clustered index is used to quickly locate the rows that match the search criteria.
- Non-clustered indexes are generally smaller in size than the actual table data, which allows for faster searching and sorting of data.
80. How do you perform backup and restore operations in SQLite?
- To perform a backup operation in SQLite, you can use the SQLite command-line tool or a third-party tool that supports SQLite.
- The SQLite command-line tool provides a built-in backup command that allows you to make a copy of a database file.
- To create a backup using the SQLite command-line tool, you can use the following command: sqlite3 old_database.db “.backup new_database.db”
- To restore a backup in SQLite, you can simply copy the backup file to a new location or rename it to the original database filename.
- You can also use the SQLite command-line tool to restore a backup by using the following command: sqlite3 new_database.db “.restore old_database.db”
- It’s important to note that when restoring a backup, any data in the original database file will be overwritten. Therefore, it’s recommended to create a backup before performing any restore operations.
81. How do you monitor and optimize the memory usage of a SQLite database?
- To monitor the memory usage of a SQLite database, you can use the “PRAGMA” command with the “cache_size” or “page_count” options.
- To optimize memory usage, you can adjust the cache size, use transactions, and avoid storing large binary objects in the database.
- You can also use tools like the “sqlite3_analyzer” command-line utility to analyze the database and identify areas for optimization.
82. Can you explain the difference between a blob and a text data type in SQLite?
- The “blob” data type in SQLite is used to store binary data, while the “text” data type is used to store text data.
- Blobs can store any type of binary data, such as images or compressed files, while text data can only store character strings.
- Text data is usually encoded using a specific character encoding, while blobs are not.
83. How do you retrieve data from multiple tables in SQLite?
- To retrieve data from multiple tables in SQLite, you can use the “JOIN” keyword in your SQL query.
- The JOIN keyword allows you to combine data from two or more tables based on a common column.
- There are different types of JOINs, including INNER JOIN, LEFT JOIN, and RIGHT JOIN, which determine how the data is combined.
84. What is the purpose of the VACUUM command in SQLite?
- The VACUUM command in SQLite is used to reclaim unused space in the database file and improve performance.
- When data is deleted from a SQLite database, the unused space is not automatically released back to the operating system.
- The VACUUM command compacts the database file and releases unused space, which can reduce the size of the database file and improve read and write performance.
85. What is a virtual table in SQLite? How is it used?
- A virtual table in SQLite is an abstract representation of data that can be accessed like a traditional database table.
- It is used to integrate SQLite with external data sources and custom data processing algorithms.
- It allows users to define their own custom table types that can be queried using SQL statements.
86. Can you explain the difference between SQLite and MySQL?
- SQLite is a file-based database management system, while MySQL is a server-based system.
- SQLite is simpler and more lightweight compared to MySQL.
- SQLite is suitable for smaller databases or projects, while MySQL is better suited for larger and more complex databases.
- SQLite doesn’t support client-server architecture, while MySQL does.
- MySQL has more advanced features and better performance compared to SQLite.
87. What is the difference between a NULL value and a zero value in SQLite?
| NULL Value | Zero Value |
|---|---|
| Represents absence of a value | Represents a numeric value of zero |
| Used to indicate missing or unknown data | Represents an actual value |
| Cannot be compared using arithmetic operators like >, <, =, etc. | Can be compared using arithmetic operators |
| NULL values are not included in calculations that involve numerical operations | Zero values are included in calculations that involve numerical operations |
| Example: If a person’s middle name is not known, it can be represented as NULL | Example: If a person’s age is zero, it can be represented as 0 |
88. How do you use the LIMIT clause in SQLite?
- The LIMIT clause is used to limit the number of rows returned by a query.
- It takes one or two arguments, the first being the number of rows to return and the second being the offset from the first row.
- For example: SELECT column1, column2 FROM table_name LIMIT 10;
89. How do you use the LIKE operator in SQLite?
The LIKE operator is used to search for a specific pattern in a string. It can be used in the WHERE clause of an SQL statement. The syntax is as follows:
SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern;
90. How do you drop an index in SQLite?
- To drop an index in SQLite, you can use the DROP INDEX statement followed by the name of the index.
- The syntax for dropping an index in SQLite is: DROP INDEX index_name;
91. How do you use the RANDOM function in SQLite?
- The RANDOM function in SQLite is used to generate a random integer value.
- To use the RANDOM function, you can simply call it in your query.
- For example, to generate a random integer between 1 and 100, the query would be: SELECT RANDOM() % 100 + 1;
92. How do you optimize a SQLite database?
To optimize a SQLite database, you can use the VACUUM command which reclaims unused space and defragments the database file.
93. How do you implement transactions in SQLite?
- Use BEGIN, COMMIT, and ROLLBACK statements to start, commit, and roll back transactions respectively.
- Use the AUTOCOMMIT pragma to enable or disable automatic commits.
94. What is the syntax for creating an index in SQLite?
- To create an index in SQLite, you can use the CREATE INDEX statement followed by the name of the index, the ON keyword, and the name of the table and column to be indexed.
- The syntax for creating an index in SQLite is: CREATE INDEX index_name ON table_name (column_name);
- You can also specify additional options like UNIQUE, DESC, and COLLATE when creating an index.
95. List out the areas where SQLite works well?
- Embedded devices and the internet of things
- File archives
- Server side database
- Experimental SQL language extensions
- Stand-in for an enterprise database during demos or testing
- Internal or temporary databases
- Replacement for ad hoc disk files
- Application file format
- Data Analysis
- Websites
- Cache for enterprise data
96. What are the SQLite storage classes?
- Null: The value is a NULL value
- Real: The value is a floating point value, stored as an 8 byte IEEE floating point number
- Text: The value is a text string, stored using the database encoding ( UTF-8, UTF-16BE)
- Integer: The value is a signed integer (1,2,3, etc.)
- BLOB (Binary Large Object): The value is a blob of data, exactly stored as it was input
97. When the Indexes should be avoided?
Indexes should be avoided when
- Tables that changes frequently
- Tables are small
- Columns that are frequently manipulated/ having a high number of NULL values
98. What is the use of SQLITE group by clause?
When used in conjunction with the SELECT statement, the GROUP BY clause in SQLite enables the grouping of similar data together, based on common values, attributes, or expressions.
99. Explain how to recover deleted data from my SQLite database?
If a backup copy of the database file is not available, recovering lost information in SQLite is not possible. However, SQLite offers a security feature called SQLITE SECURE DELETE, which replaces all deleted data with zeroes to prevent unauthorized access to sensitive information.
100. When can you get an SQLITE_SCHEMA error?
In SQLite, if the prepared SQL statement is invalid and cannot be executed, the SQLITE_SCHEMA error is raised. This type of error only occurs when utilizing the sqlite3 prepare() and sqlite3 step() interfaces to execute SQL statements.
The Top 100 SQLite Interview Questions and Answers provide a comprehensive guide to assess your knowledge of SQLite and help you prepare for technical interviews. To expand your knowledge, be sure to follow us on freshersnow.com.